Trong kỷ nguyên Big Data, việc lưu trữ và xử lý khối lượng dữ liệu khổng lồ trên một máy tính đơn lẻ là điều không khả thi. Để giải quyết bài toán này, Google đã xây dựng một hệ thống file phân tán nổi tiếng mang tên Google File System (GFS).
Vậy GFS là gì, hoạt động ra sao và vì sao nó trở thành nền tảng cho Hadoop và các hệ thống Big Data hiện đại?
Google File System (GFS) là gì?
GFS là một hệ thống tập tin phân tán (Distributed File System) do Google thiết kế để lưu trữ và xử lý dữ liệu cực lớn (GB → TB → PB) trên hàng nghìn máy tính thông thường.
GFS được tạo ra nhằm phục vụ các ứng dụng nội bộ của Google như:
- Lưu trữ dữ liệu tìm kiếm (search index)
- Log hệ thống
- Dữ liệu video, hình ảnh
- Dữ liệu phân tích quy mô lớn
Mục tiêu chính của GFS là: mở rộng tốt (scalable), chịu lỗi cao (fault-tolerant) và tối ưu cho dữ liệu lớn.
Vì sao Google cần GFS?
Các hệ thống file truyền thống:
- Không chịu được lỗi phần cứng
- Khó mở rộng khi dữ liệu tăng nhanh
- Không tối ưu cho xử lý song song
Trong khi đó, Google phải làm việc với:
- Hàng triệu file lớn
- Hàng nghìn máy rẻ tiền (dễ hỏng)
- Hàng triệu truy cập đọc/ghi mỗi ngày
GFS ra đời để chấp nhận lỗi phần cứng là chuyện bình thường, và hệ thống tự phục hồi khi có sự cố.
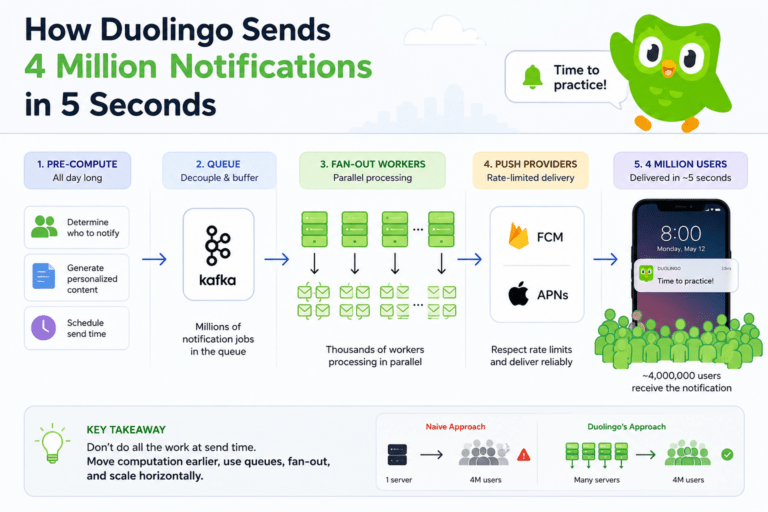
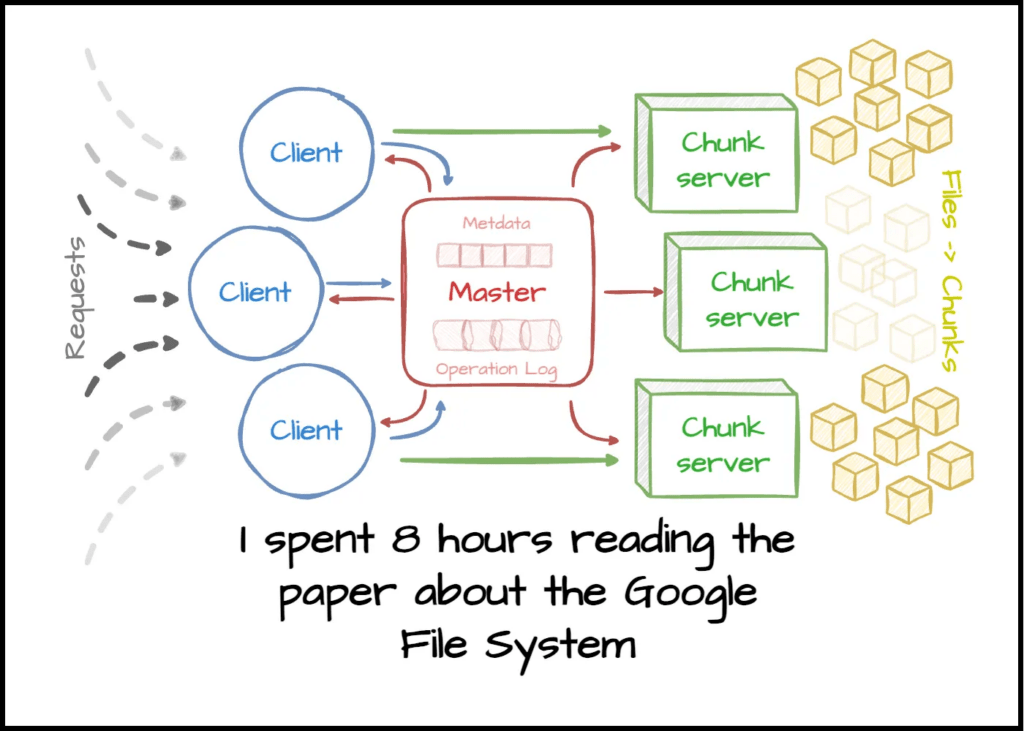
Kiến trúc của Google File System
GFS có kiến trúc đơn giản nhưng rất hiệu quả, gồm 3 thành phần chính:
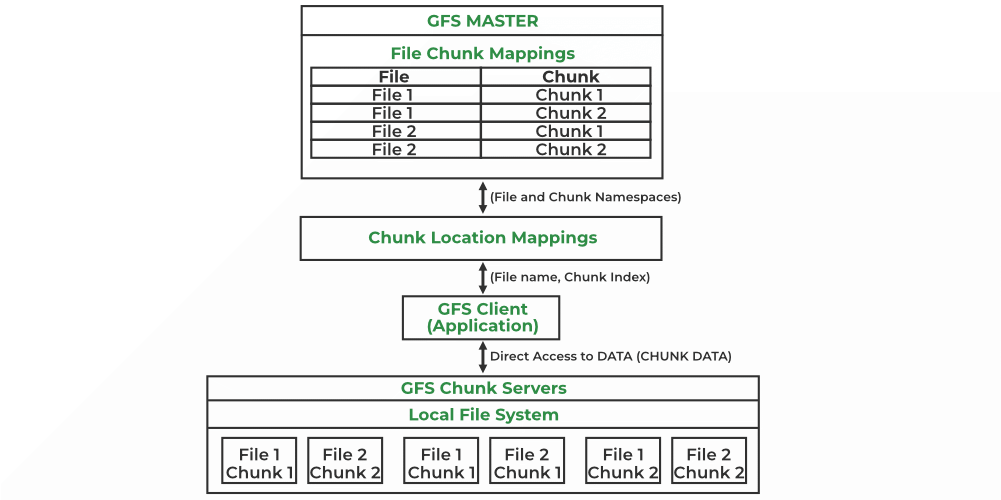
1. Master Server
- Quản lý metadata: tên file, vị trí dữ liệu, quyền truy cập
- Không lưu dữ liệu thật
- Chỉ đóng vai trò điều phối
2. Chunk Server
- Lưu dữ liệu thật
- File được chia thành các chunk (mỗi chunk = 64MB)
- Mỗi chunk được sao lưu (replication) trên nhiều máy (thường là 3)
3. Client
- Là chương trình của người dùng
- Khi cần đọc/ghi file:
- Hỏi Master để biết vị trí
- Giao tiếp trực tiếp với Chunk Server để truyền dữ liệu
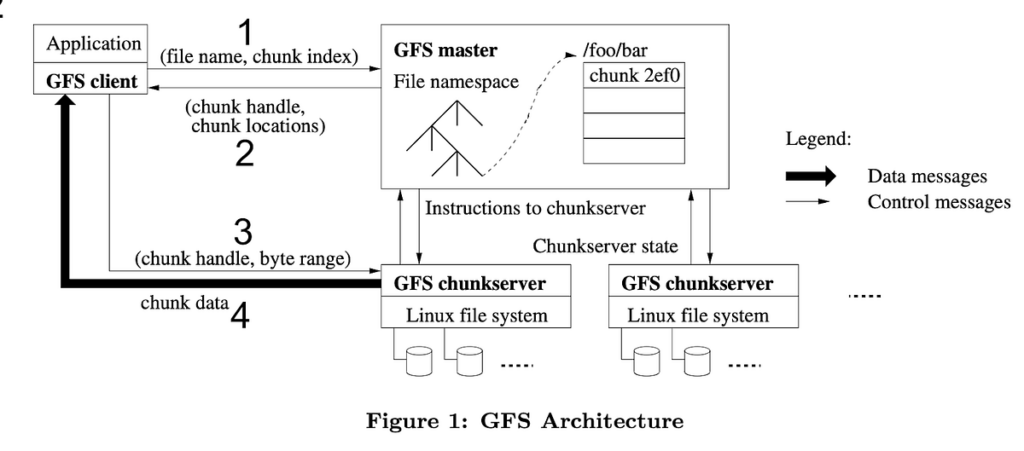
Cách GFS đọc dữ liệu (Read Operation)

Quy trình đọc file trong GFS:
- Client gửi yêu cầu đọc file cho Master
- Master trả về danh sách Chunk Server chứa dữ liệu
- Client đọc dữ liệu trực tiếp từ Chunk Server
Master không tham gia truyền dữ liệu, giúp hệ thống mở rộng tốt và giảm nghẽn cổ chai.
Cách GFS ghi dữ liệu (Write Operation)
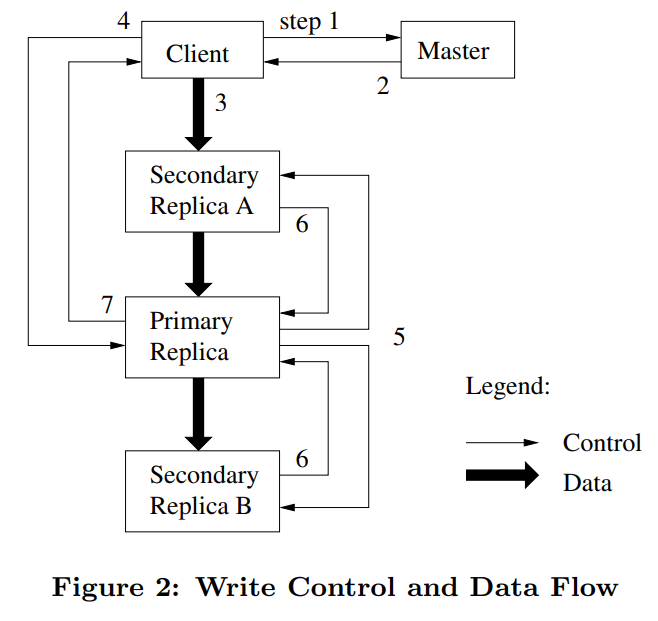
Quá trình ghi dữ liệu trong GFS được thiết kế nhằm đảm bảo tính nhất quán giữa các bản sao (replica) và khả năng chịu lỗi, thông qua sự phối hợp giữa Client, Master, Primary Replica và Secondary Replicas. Luồng điều khiển (control flow) và luồng dữ liệu (data flow) được thực hiện theo các bước sau:
Bước 1: Client gửi yêu cầu ghi dữ liệu (write request) đến Master để xin metadata của chunk cần ghi.
Bước 2: Master phản hồi cho Client thông tin về các chunk server đang lưu chunk đó, đồng thời chỉ định một replica làm Primary và các replica còn lại làm Secondary.
Bước 3 (Data flow): Client bắt đầu đẩy dữ liệu (push data) đến các chunk server theo dạng pipeline. Trong hình minh họa, dữ liệu được gửi trước tới Secondary Replica A, sau đó được truyền tiếp xuống Primary Replica và Secondary Replica B. Dữ liệu được lưu vào bộ nhớ đệm (buffer) tại các replica nhưng chưa được ghi ra đĩa.
Bước 4: Sau khi dữ liệu đã được phân phối đến tất cả các replica, Client gửi một lệnh ghi (write command) đến Primary Replica để bắt đầu quá trình ghi chính thức.
Bước 5: Primary Replica đóng vai trò điều phối, quyết định thứ tự ghi (serialization order) của các thao tác ghi và gửi lệnh ghi này đến các Secondary Replicas.
Bước 6: Các Secondary Replicas thực hiện ghi dữ liệu theo đúng thứ tự do Primary chỉ định và gửi phản hồi (acknowledgement) lại cho Primary khi hoàn tất.
Bước 7: Khi Primary Replica nhận được xác nhận thành công từ tất cả các Secondary Replicas, nó sẽ gửi phản hồi cuối cùng về cho Client, thông báo rằng thao tác ghi dữ liệu đã thành công.
Vì sao GFS dùng chunk kích thước 64MB?
- Giảm số lượng metadata mà Master phải quản lý
- Tối ưu cho đọc/ghi dữ liệu lớn (streaming)
- Giảm chi phí kết nối và truy vấn
Nếu file nhỏ hơn 64MB, GFS vẫn lưu bình thường và chỉ chiếm đúng dung lượng cần thiết.
Khả năng chịu lỗi trong GFS
GFS được thiết kế với giả định:
Máy sẽ hỏng – và đó là chuyện bình thường
Cơ chế chịu lỗi:
- Sao lưu dữ liệu trên nhiều Chunk Server
- Master theo dõi trạng thái qua heartbeat
- Khi một node chết → tự động tạo bản sao mới
Mối liên hệ giữa GFS và Hadoop
GFS là nền tảng lý thuyết và kiến trúc ban đầu mà Hadoop học hỏi và phát triển theo. Khi Google công bố các bài báo khoa học về GFS và MapReduce, cộng đồng mã nguồn mở đã dựa vào đó để xây dựng Hadoop như một hệ sinh thái Big Data hoàn chỉnh. Trong Hadoop, HDFS (Hadoop Distributed File System) đóng vai trò tương đương với GFS, với kiến trúc NameNode – DataNode tương ứng với Master – Chunk Server trong GFS. Cả hai hệ thống đều sử dụng cơ chế chia dữ liệu thành các khối lớn, sao lưu nhiều bản sao (replication), và chịu lỗi tự động, nhằm đảm bảo khả năng lưu trữ và xử lý dữ liệu quy mô lớn trên các cụm máy thông thường. Có thể xem Hadoop là phiên bản mã nguồn mở kế thừa và hiện thực hóa ý tưởng của GFS, giúp các doanh nghiệp và tổ chức bên ngoài Google tiếp cận công nghệ Big Data ở quy mô lớn.
Tham khảo thêm tại:
https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf