This document details the architecture of Mezon-Sock, a high-performance C-based WebSocket server optimized for 100,000 Concurrent Connected Users (CCU). The solution leverages Linux io_uring for asynchronous I/O and BoringSSL for encrypted communication, specifically tailored for a low-latency chat environment.
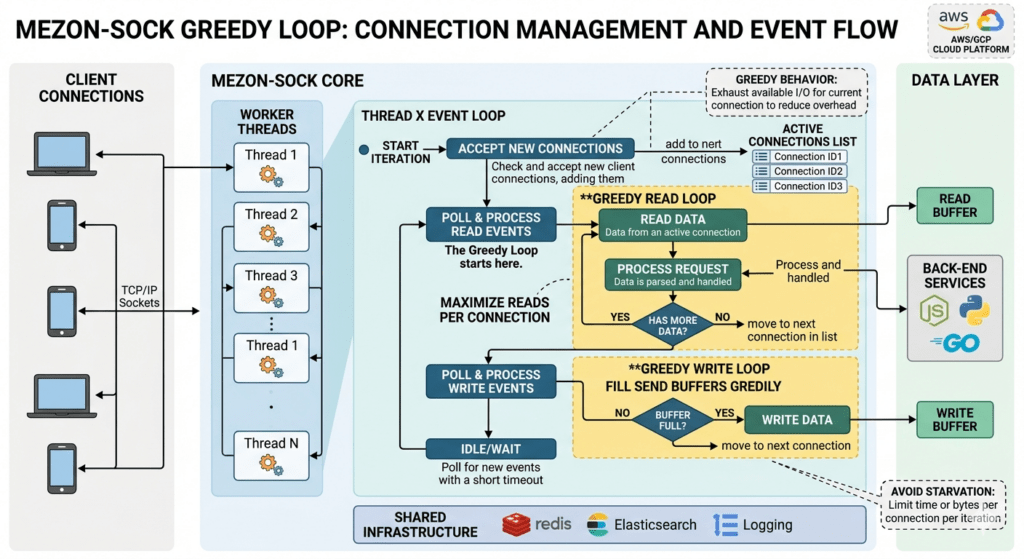
1. Core Architecture: The “Greedy” io_uring Loop
Standard epoll-based servers suffer from high system call overhead (one read or write call per event). Mezon-Sock uses io_uring to reduce the kernel-user space boundary crossing.
Asynchronous Event Handling
The server uses a Proactor pattern. Instead of asking the kernel “Is this socket ready?”, it submits a poll request and waits for a Completion Queue Entry (CQE).
The Greedy Read/Write Strategy
When a socket becomes ready (OP_READ_READY), the server enters a “Greedy Loop.” It performs multiple SSL_read operations until the SSL engine returns SSL_ERROR_WANT_READ. This ensures that a single notification from the kernel can process an entire burst of chat messages, significantly increasing throughput.
System Call Batching (The “Greedy” Flush)
This is where the major system call reduction happens. When a worker thread handles a OP_WRITE_READY event for a connection:
- The
flush_write_queueloop: It doesn’t just send one packet and return to the kernel. It attempts toSSL_writeas many packets as possible from the queue until the socket buffer is full (SSL_ERROR_WANT_WRITE). - If a user has 5 pending chat messages in their queue, they might all be sent in a single TCP packet and a single system call, depending on the MTU and SSL record size.
2. SSL/TLS Optimization with BoringSSL
For a chat app, TLS handshakes and encryption are the primary CPU bottlenecks.
- Non-Blocking SSL Handshake: The handshake is integrated directly into the
io_uringloop. If a handshake requires more data, it yields and adds a poll, allowing the thread to handle other users. - Moving Write Buffers: By enabling
SSL_MODE_ACCEPT_MOVING_WRITE_BUFFER, we allow the write queue to move data from stack-allocated buffers to heap-allocated persistent slots without breaking the SSL state. - Session Resumption: (Configurable) Support for TLS Session Tickets allows returning users to reconnect with a 1-RTT handshake instead of 2-RTT, reducing latency and CPU load during “reconnect storms.”
3. Sharded Session Registry (Reducing Lock Contention)
In a 100k CCU environment, a single global mutex on the user registry becomes a massive bottleneck. Every time a user connects, disconnects, or is looked up for a message, the lock is hit.
Implementation: Horizontal Partitioning (Sharding)
We replace the single session_registry with an array of shards (e.g., 64 or 128 shards).
define REGISTRY_SHARDS 128
define GET_SHARD(uid) ((uid) % REGISTRY_SHARDS)
typedef struct {
pthread_rwlock_t lock;
hash_table_t sessions; // Map: UserID -> mezon_conn_t
} registry_shard_t;
registry_shard_t session_shards[REGISTRY_SHARDS];
Optimization Result: Instead of 100,000 users competing for 1 lock, only ~780 users compete for 1 lock per shard. This reduces lock wait time by over 98%.
4. Sharded Presence & Stream Tracker
In a chat app, “Presence” (who is online in a channel/clan) is the most volatile data. Mezon-Sock uses a Stream Tracker to manage which users are subscribed to specific “streams” (e.g., clan:123, notifications:user_456).
Stream Sharding
Similar to the registry, the Presence Tracker is sharded by the Stream ID (hash of the string or the integer ID).
- Tracker Map: Each shard contains a map where the key is the
StreamIDand the value is a linked list or dynamic array ofmezon_conn_t*. - Lock-less Reads: We use
pthread_rwlockwhere message broadcasting (reads) can happen concurrently, and only subscribing/unsubscribing (writes) requires an exclusive lock.
5. Memory Management: Mimalloc & Object Pooling
Chat apps generate millions of tiny allocations (packets, string keys). Standard malloc leads to memory fragmentation.
- Mimalloc: We use Microsoft’s
mimalloc, which is optimized for multi-threaded performance and prevents fragmentation. - Connection Pooling:
mezon_conn_tstructures are pre-allocated in a pool. When a user connects, we “pop” a prepared struct. This avoids expensivezalloccalls on every new connection. - Broadcast Packet Ref-Counting: When a message is broadcasted to 1,000 users in a clan, the packet is allocated once. Each connection’s write queue stores a pointer to the
shared_pktand increments anatomic_int ref_count. The memory is freed only when the last user’s socket has successfully sent the data.
6. Zero-Copy Write Queue
The wq_push and flush_write_queue logic ensures that the application never blocks on a slow client.
- If
SSL_writereturns a partial length, the remainder is stored in thewrite_slot_t. - The
io_uringpoll is updated toPOLLOUT. - Once the kernel signals the buffer is clear, the remaining bytes are flushed. This prevents “Head-of-Line Blocking” for the rest of the server’s users.
Summary of Optimizations
| Component | Optimization Technique | Benefit |
|---|---|---|
| I/O Engine | io_uring (Proactor) | Minimized Syscalls & Context Switches |
| Concurrency | Lock Sharding (128 shards) | Near-zero lock contention for CCU |
| Memory | mimalloc + Atomic Ref Counting | High-speed allocation, zero-copy broadcasts |
| Network | Greedy SSL Loop | Maximum throughput for bursty chat traffic |
| Socket | SO_REUSEPORT | Allows multiple threads to bind to the same port |