Progressive Disclosure
Agent có đủ mọi thứ cần thiết. Nhưng vẫn trả lời sai.
Bạn đã xây pipeline truy xuất, đánh index tài liệu, kết nối tools. Context window 200K token, bạn feed vào 40K token thông tin được chọn lọc kỹ lưỡng. Model đủ thông minh, test với câu hỏi đơn lẻ thì trả lời chuẩn. Nhưng khi chạy production, qua workflow nhiều bước, độ chính xác giảm. Agent ảo tưởng ra policy không tồn tại, bỏ qua tool đáng lẽ phải gọi, hoặc tự tin trả lời câu hỏi bằng thông tin từ 3 bước trước thông tin đã không còn liên quan. Thông tin có đó. Model đơn giản là không dùng được.
Attention Tax Bạn Đang Trả Mỗi Ngày
Bản năng dễ hiểu: cho model nhiều thông tin hơn, nhận kết quả tốt hơn. Nhưng nghiên cứu kể câu chuyện khác.
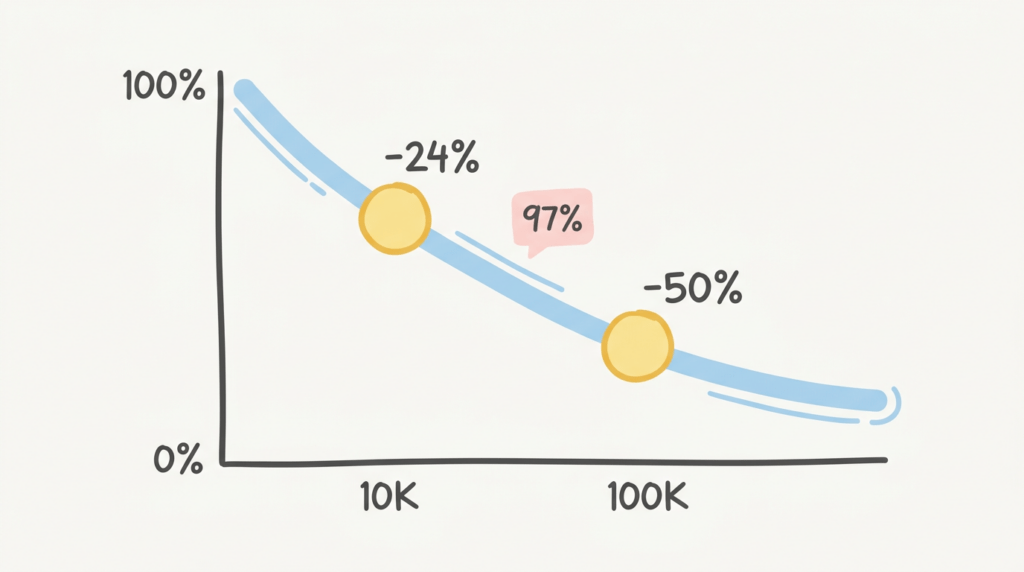
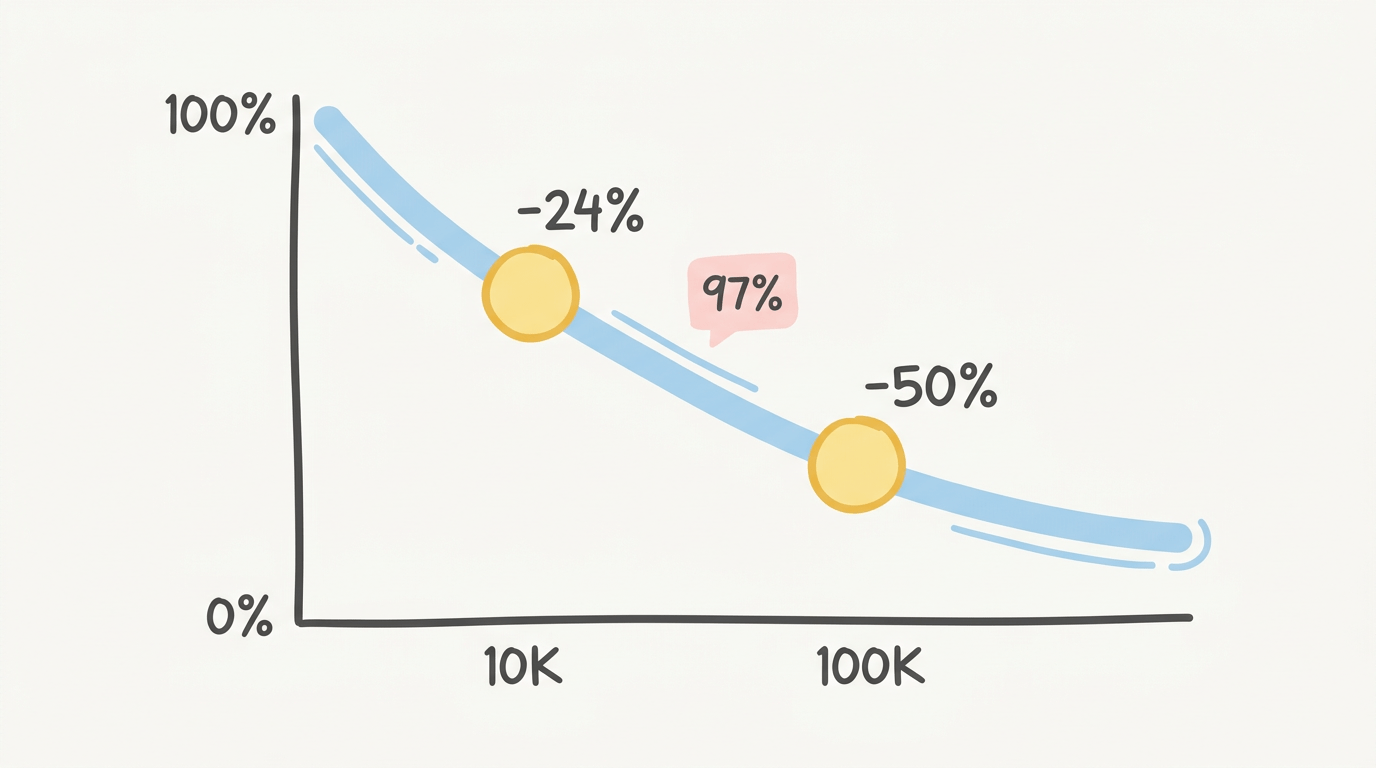
Tháng 10/2025, các nhà nghiên cứu từ Stanford và UC Berkeley công bố phát hiện ngược với trực giác: ngay cả khi LLM truy xuất hoàn hảo tất cả thông tin liên quan đọc lại token với 100% exact match performance vẫn giảm 13.9% đến 85% khi độ dài input tăng. Họ test 5 model bao gồm GPT-4o, Claude 3.5 Sonnet và Gemini 2.0. Llama-3.1-8B giảm 24.2% trên câu hỏi MMLU mở rộng đến 30K token, dù đạt 97% retrieval accuracy trên cùng dữ liệu đó. Model tìm được câu trả lời. Nhưng không suy luận được với context dài.
Đây không phải lỗi retrieval. Các nhà nghiên cứu đi xa hơn: họ thay tất cả token không liên quan bằng khoảng trắng và mask chúng hoàn toàn khỏi attention. Performance vẫn giảm. Độ dài input chính là vấn đề.
Chroma Research xác nhận pattern này ở quy mô lớn. Nghiên cứu “Context Rot” tháng 7/2025 test 18 frontier model GPT-4.1, Claude 4, Gemini 2.5, Qwen3 và các model khác và phát hiện degradation nhất quán trên tất cả. Accuracy giảm 20-50% khi chuyển từ 10K lên 100K+ token, một số model rơi từ 90% xuống 51% trong test multi-turn dialogue. Phát hiện bất ngờ: văn bản xáo trộn, không cấu trúc thực ra cho kết quả tốt hơn document mạch lạc. Pattern cấu trúc trong văn xuôi viết tốt có thể can thiệp vào cơ chế attention, tạo false signal cạnh tranh với query thực sự.
Sau đó là vấn đề vị trí. Nelson Liu của Stanford và đồng nghiệp ghi nhận hiện tượng “Lost in the Middle”: model tập trung mạnh vào đầu và cuối context window, accuracy giảm 30%+ cho thông tin nằm giữa. Hai yếu tố kiến trúc gây ra điều này: causal attention tự nhiên thiên về token sớm hơn, và rotary positional encoding tạo hiệu ứng phân rã cho nội dung xa. Document bạn truy xuất cẩn thận có thể chứa đúng câu trả lời, nhưng nếu rơi vào giữa window 50K token, model có thể bỏ qua hoàn toàn.
Ý nghĩa thực tế: load nhiều context không chỉ lãng phí token. Nó chủ động làm giảm chất lượng suy luận trên context bạn thực sự cần.
Vấn Đề 0.8%
Dự án Claude-Mem đưa ra con số cụ thể cho sự lãng phí này. Họ đo kịch bản thực tế: agent bắt đầu session code và load 25,000 token lịch sử dự án. Agent làm việc trên bug fix. Trong 25,000 token đó, khoảng 200 token liên quan đến task hiện tại. 0.8% tín hiệu. Phần còn lại là nhiễu cạnh tranh attention.
Trong đo lường rộng hơn, cách tiếp cận RAG truyền thống load 35,000 token qua các session trước, observation và file summary. Chỉ khoảng 2,000 token thực sự liên quan đến task: hiệu suất 6%. 94% còn lại không chỉ lãng phí băng thông. Dựa trên nghiên cứu phía trên, 33,000 token không liên quan đó đang chủ động làm giảm khả năng model sử dụng 2,000 token quan trọng.
Pattern này xuất hiện khắp nơi agent tiêu thụ context: hệ thống documentation mà agent load toàn bộ file spec để trả lời một câu hỏi, tool registry mà 150 tool definition nuốt 30-60K token trước khi agent bắt đầu làm việc, và conversation nhiều lượt mà output từ bước 1 cưỡi theo đến bước 20.
Vấn đề MCP tool overload minh họa rõ điều này. Microsoft Research phát hiện tool space lớn có thể giảm agent performance đến 85%. Ngay cả việc scale vừa phải cũng gây hại benchmark của Jenova AI cho thấy chuyển từ 10 lên 100 tool gây giảm ~10% accuracy trên mọi model test. Gemini 2.0 Flash từ 98.4% accuracy với 10 tool xuống 88.2% với 100 tool. Cursor giới hạn MCP tool ở 40. GitHub Copilot giới hạn 128. OpenAI khuyến nghị dưới 20. Đây không phải giới hạn tùy tiện đây là phản ứng với degradation đo được.
Insight cốt lõi từ nghiên cứu tháng 1/2026 về intelligence degradation trong long-context LLM: attention concentration phân rã theo hàm mũ với độ dài context. Với Qwen2.5-7B, các nhà nghiên cứu xác định ngưỡng quan trọng ở 43.2% context window vượt qua đó, “catastrophic degradation” bắt đầu. Khuyến nghị thực tế: giữ context dưới 40% window để performance ổn định. Nếu dùng model 128K, nghĩa là dưới ~51K token. Hầu hết production agent vượt xa con số đó trước khi đọc xong system prompt và tool definition.
Nguyên Tắc UX, Tái Sử Dụng
Giải pháp đã nằm trong một lĩnh vực khác suốt ba mươi năm.
Năm 1995, Jakob Nielsen tại Nielsen Norman Group giới thiệu progressive disclosure như interaction design pattern: chỉ hiển thị cho người dùng những gì họ cần bây giờ, và hoãn mọi thứ khác sang màn hình phụ. Nguyên tắc xuất phát từ tâm lý học: giảm thông tin trình bày tại bất kỳ thời điểm nào giúp con người tập trung vào thứ thực sự liên quan. Google Search là ví dụ kinh điển: một ô text duy nhất cho hầu hết người dùng, với advanced filter có sẵn cách một click cho người cần.
Nguyên tắc tương tự áp dụng cho AI agent, với một khác biệt quan trọng: agent không chỉ là người dùng. Agent còn là hệ thống quyết định load gì tiếp theo. Progressive disclosure cho agent nghĩa là cấu trúc thông tin để agent bắt đầu với index nhẹ và kéo độ sâu khi cần, dùng suy luận của chính nó để quyết định đường đi nào.
Anthropic chính thức hóa điều này vào tháng 11/2025 với Agent Skills. Hệ thống dùng kiến trúc ba lớp:
- Layer 1 – Metadata (~100 token/skill): Chỉ tên và mô tả. Load lúc khởi động để agent biết khả năng nào tồn tại.
- Layer 2 – Core instruction (~200-500 token): File SKILL.md đầy đủ. Chỉ load khi agent xác định skill khớp với task hiện tại.
- Layer 3+ – Referenced content (tùy): Script, file tham khảo, ví dụ đóng gói trong thư mục skill. Load on-demand khi agent gặp nhu cầu cụ thể trong quá trình thực thi.
Insight chủ chốt, theo documentation Anthropic: “lượng context có thể đóng gói vào skill thực sự không giới hạn.” Không có context penalty cho nội dung agent không truy cập. Skill có thể bao gồm 50,000 token tài liệu tham khảo, và nếu agent chỉ cần summary 300 token, đó là tất cả những gì load. Tại AWS re:Invent 2025, Anthropic nói thẳng: “Claude đã đủ thông minh – intelligence không phải bottleneck, context mới là.”
Google Agent Development Kit (ADK) đạt cùng kết luận từ hướng khác. ADK coi context là “compiled view trên hệ thống stateful phong phú hơn,” tách working context (prompt trực tiếp), session (log tương tác), memory (kiến thức tồn tại lâu) và artifact (dữ liệu lớn được tham chiếu, không dán vào prompt). Pattern Artifact của họ dùng lazy loading: agent nhận file summary, và chỉ load raw data khi quyết định cần. Như Revionics nói sau khi áp dụng ADK trong production: “agent suy luận hiệu quả trên big data qua storage artifact thay vì chỉ dựa vào LLM context.”
Nguyên Tắc Rabbit Hole
Các pattern này đều chia sẻ cấu trúc chung: three-layer skill của Anthropic, artifact của Google, indexed retrieval của Claude-Mem. Tôi gọi là Nguyên tắc Rabbit Hole:
Cấu trúc thông tin như entry point nông dẫn đến detail sâu dần, mỗi level tiếp cận được bằng một tool call duy nhất.
Thay vì đưa cho agent sách giáo khoa, bạn đưa mục lục và đèn pin.
Cơ chế đơn giản. Bốn bước, lặp lại:
- Xem bản đồ: index phẳng, dễ quét của những gì tồn tại
- Chọn hang: chọn phần liên quan dựa trên metadata
- Tiến đến tầng sau: mỗi level link đến level tiếp theo
- Dừng khi đủ: không bao giờ bị ép qua tài liệu không liên quan
Điều này biến context từ payload (đẩy cho agent) thành tài nguyên (agent kéo về). Quá trình suy luận của agent trở thành logic routing. Agent đọc bản đồ, xác định những gì cần, load đường đi đó, suy luận trên đó, sau đó chuyển đến decision point tiếp theo. Item agent không cần tốn zero token.
Dự án Claude-Mem chứng minh sự khác biệt: cách tiếp cận progressive disclosure của họ load ~955 token (index 800 token cộng fetched detail 155 token) so với 25,000-token dump truyền thống. Kết quả task giống nhau. Ít hơn hai mươi sáu lần token. Và dựa trên nghiên cứu về attention degradation, có thể chất lượng suy luận tốt hơn trên token được load.
Năm Quy Tắc Xây Dựng Rabbit Hole
Nguyên tắc đơn giản. Làm nó hoạt động ổn định đòi hỏi kỷ luật. Năm quy tắc:
Quy tắc 1: Surface Layer – Giữ Phẳng. Entry point là danh sách phẳng, mỗi item vừa một dòng với đủ metadata để trả lời: “Tôi có quan tâm không?” Format không quan trọng. YAML frontmatter, CSV row, JSON Lines đều được. Điều quan trọng: một item một dòng, metadata có cấu trúc, quét được bằng search.
@ENDPOINT method=GET path=/users/{id} auth=required rate_limit=100/min
@ENDPOINT method=POST path=/users auth=required rate_limit=10/min
@ENDPOINT method=GET path=/health auth=none rate_limit=noneQuy tắc 2: Stable Address – Đưa Mọi Thứ Tọa Độ. Mỗi item có ID duy nhất, ổn định xuất hiện trong index và lại ở vị trí detail. Search ID, nhận đúng hai hit: index entry và detail. Address tốt là tuần tự (T:001, KB:0042), prefix theo type để tránh xung đột, và không bao giờ tái sử dụng.
Quy tắc 3: Progressive Depth – Đi Sâu Đúng Mức Cần. Thông tin sống theo layer, mỗi layer tiếp cận được từ layer trên:
| Level | Load gì | Khi nào |
|---|---|---|
| Surface | Index, cái gì tồn tại (~50-100 token/item) | Luôn luôn |
| Detail | Hoạt động thế nào (~200-500 token) | Khi item khớp task hiện tại |
| Sub-detail | Raw data, config, ví dụ (tùy) | Khi detail tham chiếu chúng |
Mỗi level tốn zero token cho đến khi truy cập. Độ sâu trở thành lựa chọn, không phải chi phí.
Quy tắc 4: Relationship Link – Kết Nối Các Điểm. Không có relationship rõ ràng, agent coi ba triệu chứng của cùng bug là ba vấn đề độc lập. Encode connection @CAUSES source=E:001 target=E:002 để agent fix root cause một lần thay vì vá triệu chứng. Format nào cũng được miễn relationship search được.
Quy tắc 5: No Duplication Một Sự kiện, Một Nơi. Surface layer có metadata. Detail layer có chi tiết. Relationship layer có connection. Không gì được phát lại. Duplication lãng phí token và tạo mâu thuẫn khi một bản copy được cập nhật và bản kia không.
Discovery Loop Trong Thực Tế
Năm quy tắc kết hợp thành pattern phổ quát: Search → Decide → Descend → Repeat.
Đây là cách nó hoạt động với blog writing skill thực tế. Implementation gốc là file command nguyên khối ~130 dòng. Mọi tone rule, structure pattern và quality check load vào context ngay khi skill kích hoạt. Khoảng 1,800 token, luôn luôn, không quan trọng agent đang viết opening paragraph hay chạy final quality check.
Phiên bản refactor chia monolith thành file tài nguyên atomic tổ chức theo concern. Surface file (~300 token) chứa workflow với pointer, không phải rule:
### Opening
- Đọc structure/opening.md cho pattern hook + scope + hero image
- Đọc tone/data-driven.md nếu cần hướng dẫn trích dẫn thống kê
### Body Section
- Đọc structure/sections.md cho H2/H3 pattern
- Đọc tone/voice.md nếu cần điều chỉnh toneQuá trình suy luận của agent thúc đẩy loading. Viết introduction? Load structure/opening.md (~150 token) và có thể tone/data-driven.md (~100 token). Viết comparison? Load structure/decision-framework.md. Chạy final check? Load quality/checklist.md. Tại bất kỳ giai đoạn nào, agent có ~400-500 token hướng dẫn liên quan thay vì 1,800 token mọi thứ.
Tổng điển hình qua session đầy đủ: 800-1,200 token load dần, so với 1,800 token load một lần. Nhưng lợi ích thực sự không phải số token. Tại mỗi giai đoạn, attention của agent tập trung vào rule quan trọng ngay bây giờ, không bị pha loãng qua mọi rule skill chứa.
Nếu bài viết không cần decision framework (ví dụ tutorial), agent đơn giản không bao giờ load decision-framework.md. Zero token lãng phí trên structure không liên quan. Agent quyết định, dựa trên task, rabbit hole nào để xuống.
Decision Gate: Để Agent Chọn
Phần bị đánh giá thấp nhất của progressive disclosure là điều xảy ra tại surface layer. Agent không chỉ thấy index. Agent quyết định load gì tiếp theo. Đây là decision gate: điểm agent phải đánh giá option và commit vào đường đi trước khi tiêu token cho detail.
Decision gate quan trọng vì ép agent suy luận về thông tin trước khi suy luận với thông tin. Xét sự khác biệt:
Không có decision gate: agent nhận 15 document ghép thành một context block. Agent bắt đầu suy luận trên tất cả đồng thời, attention trải mỏng qua 40K token.
Có decision gate: agent nhận index 15 dòng. Agent đọc metadata, xác định ba document liên quan đến câu hỏi hiện tại, load ba cái đó (~3K token tổng) và suy luận trên chúng với attention tập trung.
Cách tiếp cận thứ hai dùng ít token hơn, nhưng quan trọng hơn, tạo suy luận tốt hơn vì attention budget của agent tập trung vào tài liệu agent chọn vì lý do. Redis MCP filtering demo định lượng điều này: không có filtering, agent đánh giá mọi tool, mất 3+ giây, tiêu ~23K token và chọn sai tool. Với pre-filtering (dạng decision gate), agent chỉ đánh giá 3 tool liên quan, trả lời đúng trong 392ms dùng 800 token.
Khi nào thêm decision gate: Bất cứ khi nào agent có hơn 5-7 option để chọn. Dưới ngưỡng đó, chi phí nhận thức của chính quyết định có thể vượt lợi ích. Trên đó, gate đều cải thiện cả accuracy và efficiency.
Khi Progressive Disclosure Không Phù Hợp
Không phải hệ thống nào cũng cần điều này. Progressive disclosure thêm indirection, và indirection có chi phí.
Bỏ qua khi tổng context dưới 10K token, agent luôn cần toàn bộ thông tin, bạn xây single-turn tool, hoặc data không có phân cấp tự nhiên.
Đầu tư khi context thường xuyên vượt 20K token và agent dùng dưới một nửa những gì load, bạn thấy accuracy giảm theo kích thước context, agent thực hiện multi-step task, hoặc bạn có 10+ tool và data source. Team Claude-Mem nắm bắt triết lý: “Context hữu hạn. Mỗi token load giảm reasoning capacity. Load tối thiểu, evict mạnh tay, đo liên tục.”
Đo Lường Hiệu Quả
Progressive disclosure không phải thứ ship và quên. Bạn đo nó. Track token load, token efficiency (liên quan vs. tổng), roundtrip để đến thông tin đúng, tool call và task accuracy.
Khi metric trông tệ, nó chỉ vào fix cụ thể:
- Token cao, accuracy thấp → Agent chết đắm trong nội dung không liên quan. Thêm surface layer; chia monolith thành topic file.
- Token thấp, accuracy thấp → Surface description quá mơ hồ. Thêm tag và keyword vào frontmatter.
- Nhiều roundtrip, accuracy cao → Agent search rộng. Surface routing tốt hơn; thêm domain-specific filter.
- Ít roundtrip, token cao → Load toàn bộ file khi chỉ cần fragment. Thêm script bridge để extract fragment.
Claude Code, Gemini CLI và Codex CLI đều có native instrumentation (hook, telemetry, JSONL transcript) để extract các con số này không cần custom tooling.
Từ Passenger Đến Navigator
Đây là shift progressive disclosure tạo ra.
Trong cách tiếp cận truyền thống, agent là passenger. Ai đó (bạn, system prompt, RAG pipeline) quyết định thông tin agent thấy. Agent nhận context được lắp ráp sẵn và làm tốt nhất với những gì xuất hiện. Nếu context tốt, agent hoạt động tốt. Nếu context phình to, cũ hoặc thiếu fact chủ chốt, agent fail. Agent không thể fix vấn đề vì không kiểm soát những gì nhìn thấy.
Với progressive disclosure, agent trở thành navigator. Agent bắt đầu với bản đồ, index nhẹ về những gì tồn tại. Agent đọc bản đồ, chọn điểm đến, đi sâu đúng mức cần, sau đó chuyển sang decision point tiếp theo. Agent kiểm soát context của chính mình. Agent load những gì cần, bỏ qua những gì không, và dừng khi đủ.
Context window cứ lớn dần. 200K, 1M, 10M token. Nhưng mọi nghiên cứu chúng ta xem đều cho thấy ném nhiều token vào vấn đề làm suy luận tệ hơn, không tốt hơn. Model hoạt động tốt nhất không phải model có nhiều thông tin nhất. Đó là model có thông tin đúng, load đúng thời điểm, với nhiễu tối thiểu.
Đưa cho agent bản đồ, không phải tour. Để agent chọn rabbit hole nào xuống. Agent sẽ tìm thấy những gì cần nhanh hơn, dùng ít token hơn để đến đó, và suy luận tốt hơn với budget tiết kiệm được.
Viết dựa trên nghiên cứu từ Chroma “Context Rot” study (tháng 7/2025), paper “Context Length Alone Hurts” của Stanford/UC Berkeley (tháng 10/2025), kiến trúc Agent Skills của Anthropic (tháng 11/2025), đo lường progressive disclosure của Claude-Mem và nghiên cứu “Lost in the Middle” của Stanford. Xuất bản tháng 3/2026.
Nguồn & Tài liệu Tham khảo
- Progressive Disclosure — Nielsen Norman Group (1995)
- Context Length Alone Hurts LLM Performance Despite Perfect Retrieval — Stanford, UC Berkeley (Oct 2025)
- Context Rot — Chroma Research (July 2025)
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al., Stanford (2023)
- Intelligence Degradation in Long-Context LLMs (Jan 2026)
- Equipping Agents for the Real World with Agent Skills — Anthropic (Nov 2025)
- Agent Skills Documentation — Anthropic
- Architecting Efficient Context-Aware Multi-Agent Framework — Google ADK (Dec 2025)
- Progressive Disclosure — Claude-Mem
- Tool-Space Interference in the MCP Era — Microsoft Research (2025)
- AI Tool Overload: Why More Tools Mean Worse Performance — Jenova AI (2025)
- State of Agent Engineering — LangChain (Dec 2025)
- Code Execution with MCP: Building More Efficient Agents — Simon Willison / Anthropic (Nov 2025)