RAG đến Agentic RAG
Hệ thống RAG của bạn truy xuất đúng tài liệu. Embedding được tinh chỉnh. Chunk được tối ưu. Nhưng agent vẫn tạo ra câu trả lời sai với độ tự tin tuyệt đối.
Đây là nghịch lý đẩy ngành công nghiệp từ truy xuất bị động sang vòng lặp lý luận chủ động. RAG không chết, nó đang tiến hóa từ mô hình đơn thuần chèn tài liệu thành hệ thống xác minh tự trị. Bài viết này theo dõi quá trình chuyển đổi đó và chỉ cho bạn cách xây dựng cơ chế truy xuất tự phê bình chính nó.
Phần 1: Kỷ nguyên RAG Đơn giản
Có một khoảng khắc ngắn ngủi vào năm 2023 khi RAG như phép màu. Bạn embedding tài liệu, lưu vào vector database, truy xuất top-k kết quả khớp nhất, nhồi vào prompt. Model có quyền truy cập vào knowledge base. Vấn đề giải quyết.
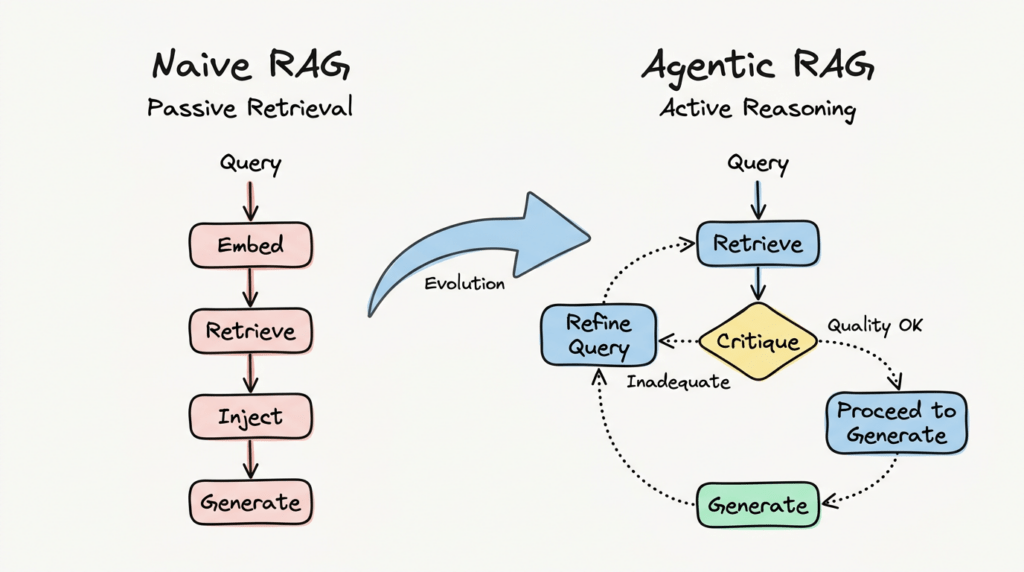
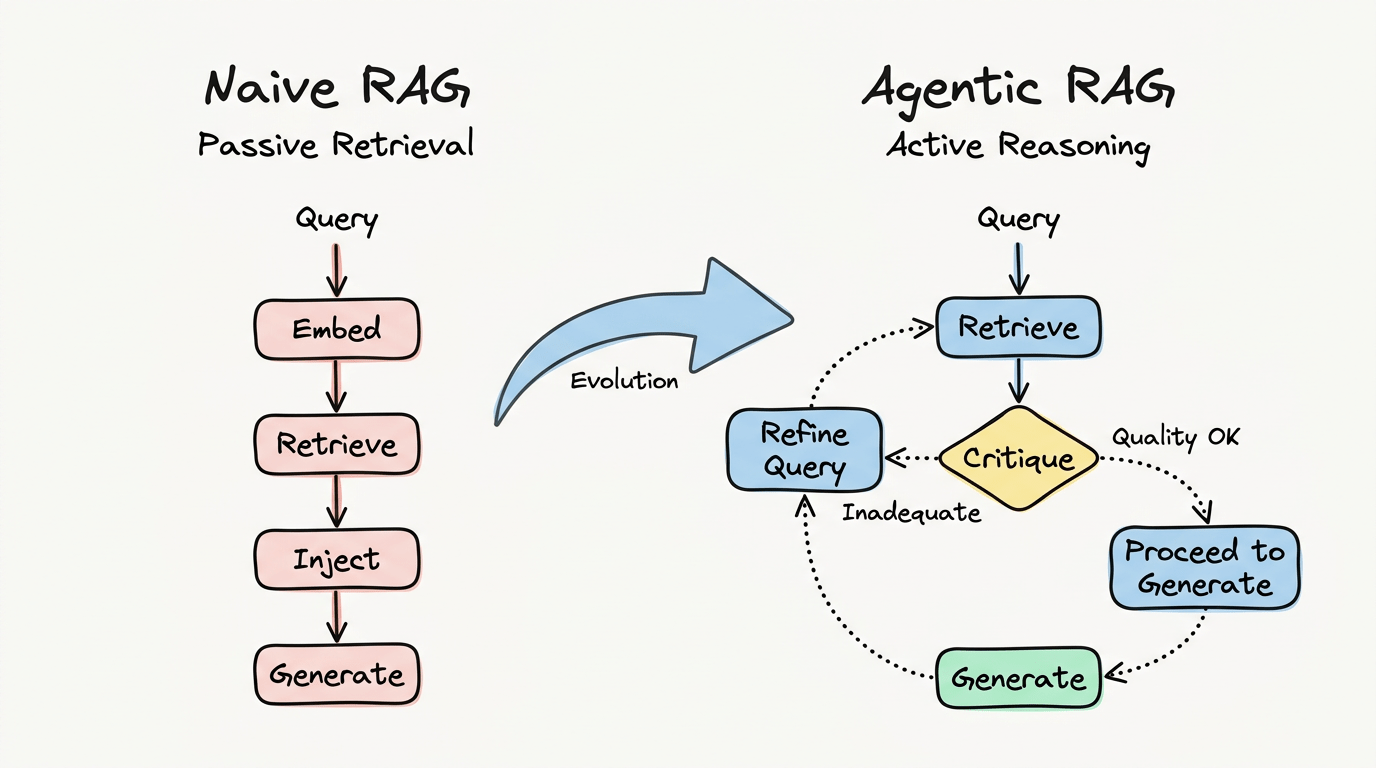
Mô hình này thẳng thắn: Query → Embed → Retrieve → Inject → Generate. Nhanh. Đơn giản. Và thành công rực rỡ với hệ thống hỏi đáp cơ bản trên tài liệu có cấu trúc rõ ràng.
Nhưng khi các team mở rộng vượt ra ngoài tìm kiếm tài liệu, các vết nứt bắt đầu lộ rõ. Các chunk truy xuất về mặt kỹ thuật liên quan nhưng thực tế vô dụng. Model không thể tìm thấy thông tin cần thiết, ngay cả khi nó nằm ngay đó trong context window.
Phần 2: Tại sao RAG Đơn giản Đổ vỡ dưới Áp lực
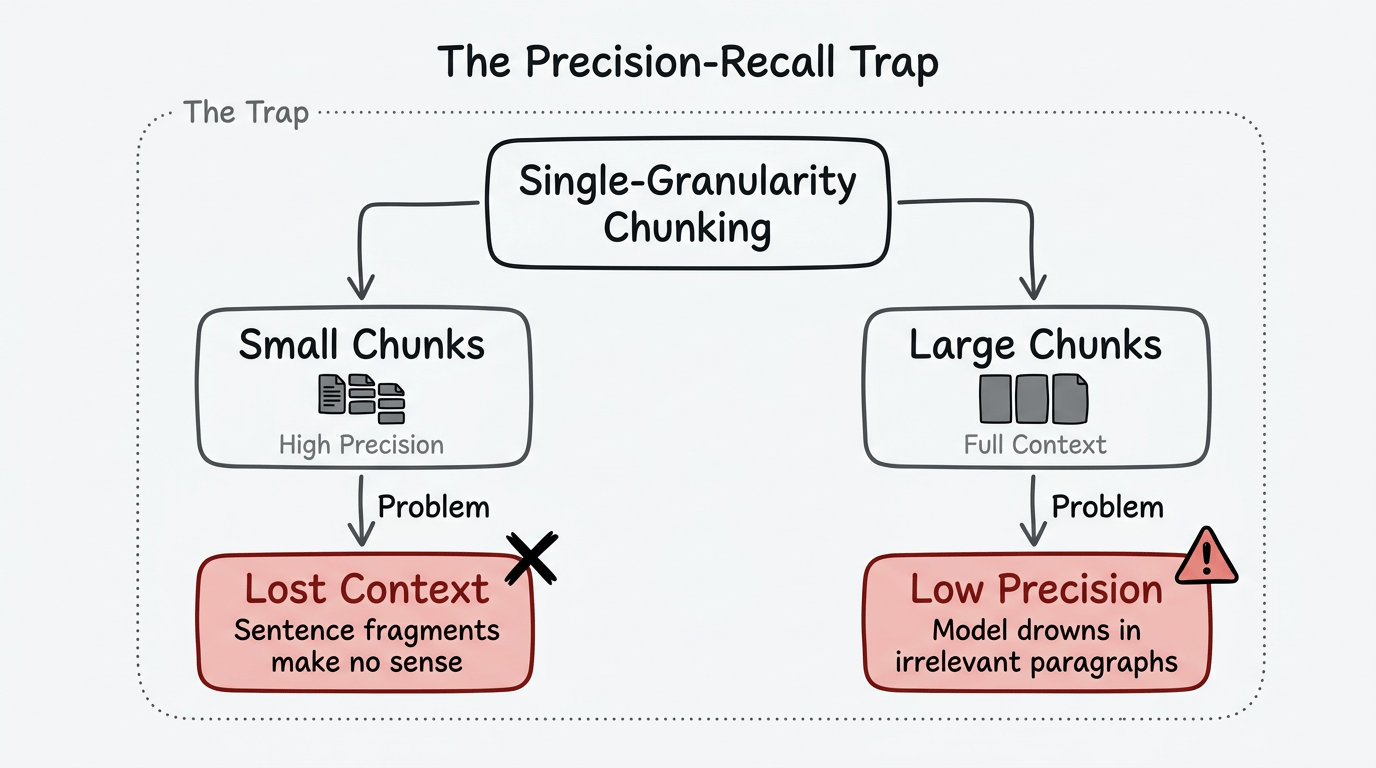
Bẫy Precision-Recall
RAG đơn giản buộc bạn vào lựa chọn bất khả thi. Chunk nhỏ cho bạn độ chính xác cao—retriever tìm chính xác những gì khớp với query. Nhưng chunk nhỏ mất ngữ cảnh. Model nhận những mảnh câu không có nghĩa khi đứng riêng lẻ.
Chunk lớn giữ ngữ cảnh nhưng phá hủy độ chính xác. Retriever của bạn lấy cả phần tài liệu vì một câu khớp với query. Model chìm trong đống đoạn văn không liên quan, tìm tín hiệu trong ồn.
Đây không phải vấn đề tinh chỉnh. Đây là vấn đề kiến trúc. Chunking với độ chi tiết đơn nhất không thể thỏa mãn cả hai yêu cầu cùng lúc. Bạn tối ưu một cái, hy sinh cái kia.
Vấn đề Lạc giữa dòng (Lost in the Middle)
Năm 2024, các nhà nghiên cứu tại RAGFlow ghi chép những gì các practitioner đã biết: nhồi văn bản dài vào context window của LLM một cách máy móc làm phân tán sự chú ý của model và giảm đáng kể chất lượng câu trả lời qua hiện tượng gọi là “information flooding” (tràn ngập thông tin). Model có quyền truy cập vào thông tin—nhưng không thể tìm thấy nó.
Cuộc tranh luận “Liệu Long Context có thể Thay thế RAG?” đạt đỉnh vào 2024 và bước vào thử nghiệm sản xuất năm 2025. Một số team thử bỏ qua truy xuất hoàn toàn, đẩy toàn bộ bộ sưu tập tài liệu vào các model tiên tiến với context window hàng triệu token. Các tình huống theo mô hình cố định như xem xét hợp đồng cho thấy triển vọng ban đầu.
Nhưng hóa ra năng lực context thô không giải quyết được truy cập thông tin. Theo đánh giá RAGFlow 2025, nhồi văn bản vào context window một cách máy móc về cơ bản là chiến lược brute-force gây ra chính hiện tượng “Lost in the Middle” mà RAG được tạo ra để giải quyết.
Khi Truy xuất Context Trở thành Vector Tấn công
Có điều gì tệ hơn truy xuất tệ: truy xuất độc hại. Tài liệu bảo mật Gen AI của OWASP năm 2025 mô tả các cuộc tấn công khi tài liệu bị sửa đổi trong kho RAG làm thay đổi đầu ra LLM. Kẻ tấn công thay đổi tài liệu chính sách trong knowledge base của bạn. Khi query của người dùng truy xuất nội dung đã bị đầu độc đó, các chỉ thị độc hại điều hướng phản hồi của model.
Nghiên cứu về RAG poisoning trên knowledge graph cho thấy kẻ tấn công có thể chèn nhiễu loạn làm sai lệch quá trình lý luận trong hệ thống KG-RAG. Và vì RAG hoạt động ở cấp độ tài liệu, việc xác thực tính toàn vẹn của các chunk truy xuất trở thành vấn đề trust boundary.
Model giả định nội dung truy xuất là ground truth. Khi giả định đó sụp đổ, hệ thống của bạn cũng vậy.
Phần 3: Chuyển đổi—Vòng lặp Truy xuất Chủ động
Self-RAG: Khi Model Phê bình Chính nó
Tháng 10/2023, các nhà nghiên cứu từ University of Washington, IBM AI Research và Allen Institute công bố Self-RAG tại ICLR 2024 (được chấp nhận là bài trình bày Oral—top 1%). Insight cốt lõi: model nên quyết định khi nào cần truy xuất, đánh giá những gì truy xuất được, và phê bình đầu ra của chính mình trước khi trả lời.
Self-RAG giới thiệu reflection token—các marker đặc biệt chỉ ra sự cần thiết truy xuất và đánh giá chất lượng sinh ra. Thay vì chèn mù quáng các tài liệu top-k, model hỏi: Tôi có cần thông tin bên ngoài cho query này không? Nếu có, nó truy xuất. Sau đó nó hỏi: Nội dung truy xuất này thực sự liên quan không? Nếu không, nó truy xuất lại với query tinh chỉnh.
Kết quả: model Self-RAG ở 7B và 13B tham số vượt ChatGPT và Llama2 tăng cường truy xuất trên các tác vụ QA mở, lý luận và xác minh sự thật. Không phải vì chúng có embedding tốt hơn hay context window lớn hơn, mà vì chúng học cách xác minh nguồn trước khi tin tưởng.
Lý luận Nhiều bước thay vì Chèn Một lần
RAG truyền thống là giao dịch một lần: truy xuất một lần, sinh một lần, xong. Agentic RAG coi truy xuất là vòng lặp lặp đi lặp lại. Agent xây dựng query, truy xuất tài liệu, đánh giá mức độ liên quan, và quyết định tinh chỉnh tìm kiếm hay tiến hành sinh câu trả lời.
Khảo sát tháng 1/2025 về Agentic RAG (arXiv:2501.09136) hình thức hóa cách các agent tự trị nhúng reflection, planning và sử dụng công cụ vào framework truy xuất. Thay vì workflow tĩnh, agent điều chỉnh chiến lược động dựa trên những gì tìm được. Nếu lần truy xuất đầu không cho kết quả tốt, agent reformulate query. Nếu tài liệu truy xuất mâu thuẫn nhau, agent cross-reference hoặc tìm kiếm tiebreaker.
Triển khai sản xuất dùng agent kiểu ReAct—plan, observe và adapt—báo cáo giảm 25-40% truy xuất không liên quan so với RAG đơn giản. Nhưng chúng cũng lộ các failure mode mới: vòng lặp truy xuất khi agent bị kẹt tinh chỉnh các query không bao giờ cho kết quả tốt, và quyết định truy xuất sai khi agent bỏ qua truy xuất trong lúc thực sự cần context bên ngoài.
Đây là sự đánh đổi. Agentic RAG giảm nhiễu nhưng tăng độ phức tạp. Bạn không còn debug một hàm truy xuất—bạn đang debug một quá trình ra quyết định tự trị.
Phần 4: Vượt Vector Search – Công cụ Truy xuất Tăng cường
Hybrid Search là Mặc định Mới
Đến 2025, sự đồng thuận vững chắc: vector đơn thuần không đủ. BM25 keyword search kết hợp với vector similarity—hybrid search—luôn vượt từng phương pháp riêng lẻ. PostgreSQL với pgvector, Azure SQL với vector indexing, và các vector database chuyên dụng như Pinecone và Qdrant đều hội tụ về cùng mô hình này.
SQL Server 2025 và Azure SQL Database tung ra vector indexing ở public preview, cho phép hybrid query kết hợp semantic similarity với filter có cấu trúc. Bây giờ bạn có thể hỏi “Tìm tài liệu tương tự ngữ nghĩa với query này, nhưng chỉ từ báo cáo tài chính Q4 2024 do team compliance viết,” trong một database call duy nhất.
Hệ thống hybrid retrieval cắt giảm độ trễ tới 50% so với mô hình vector-rồi-filter tuần tự, theo nghiên cứu tổng hợp trong các hướng dẫn đánh giá RAG năm 2025. Stack truy xuất không chỉ nhanh hơn—mà còn chính xác hơn.
Khi SQL, Grep và API Gia nhập Stack Truy xuất
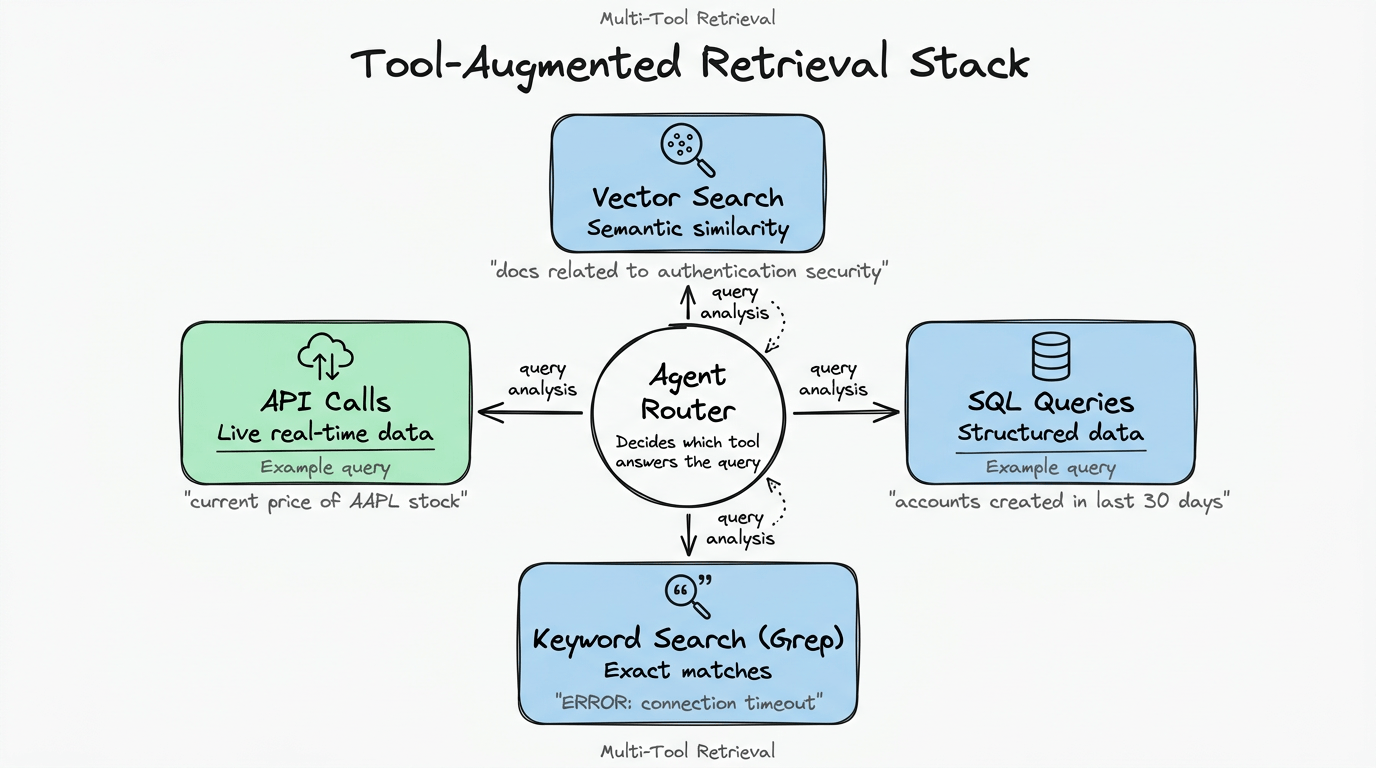
Vector database không bao giờ được thiết kế làm nguồn kiến thức duy nhất. Chúng tốt cho semantic similarity, tệ cho exact match, và vô dụng với dữ liệu real-time.
Hệ thống Agentic RAG hiện đại coi truy xuất là bài toán đa công cụ:
- Vector search cho semantic similarity (“tài liệu liên quan đến bảo mật authentication”)
- SQL query cho dữ liệu có cấu trúc (“tài khoản người dùng tạo trong 30 ngày qua”)
- Keyword search (Grep) cho chuỗi chính xác (“ERROR: connection timeout”)
- API call cho dữ liệu live (“giá hiện tại của cổ phiếu AAPL”)
Framework như LangChain và LlamaIndex cung cấp integration layer, nhưng kiến trúc về mặt khái niệm đơn giản: cho agent nhiều công cụ và để nó quyết định công cụ nào trả lời query. Agent không chỉ truy xuất—nó định tuyến.
GraphRAG: Mã hóa Quan hệ mà Embedding Làm phẳng
Buzzword nóng nhất cuối 2024 và đầu 2025, theo hướng dẫn RAG doanh nghiệp của Data Nucleus, là GraphRAG—graph-enhanced retrieval augmented generation. Vấn đề cốt lõi nó giải quyết: embedding nắm bắt semantic similarity nhưng phá hủy quan hệ rõ ràng.
Nếu tài liệu của bạn nói “Service A phụ thuộc vào Service B,” một vector search cho “Service A” có thể truy xuất câu đó. Nhưng nó không truy xuất các phụ thuộc transitive, các failure mode khi Service B down, hay các architectural decision record giải thích tại sao phụ thuộc tồn tại.
GraphRAG mã hóa entity và quan hệ một cách rõ ràng. Khi agent query Service A, nó không chỉ truy xuất text chunk—nó đi qua dependency graph, lấy các entity liên quan, và bề mặt hóa ngữ cảnh mà embedding đơn thuần làm phẳng.
Có phải hype không? Một phần. Xây dựng và duy trì knowledge graph đắt. Nhưng với các domain có cấu trúc quan hệ phong phú—kiến trúc phần mềm doanh nghiệp, luật án lệ, nghiên cứu khoa học, raphRAG cung cấp mô hình truy cập mà pure embedding không thể sánh.
Phần 5: Xác minh là Khả năng Hạng nhất
Mô hình Vòng lặp Xác minh
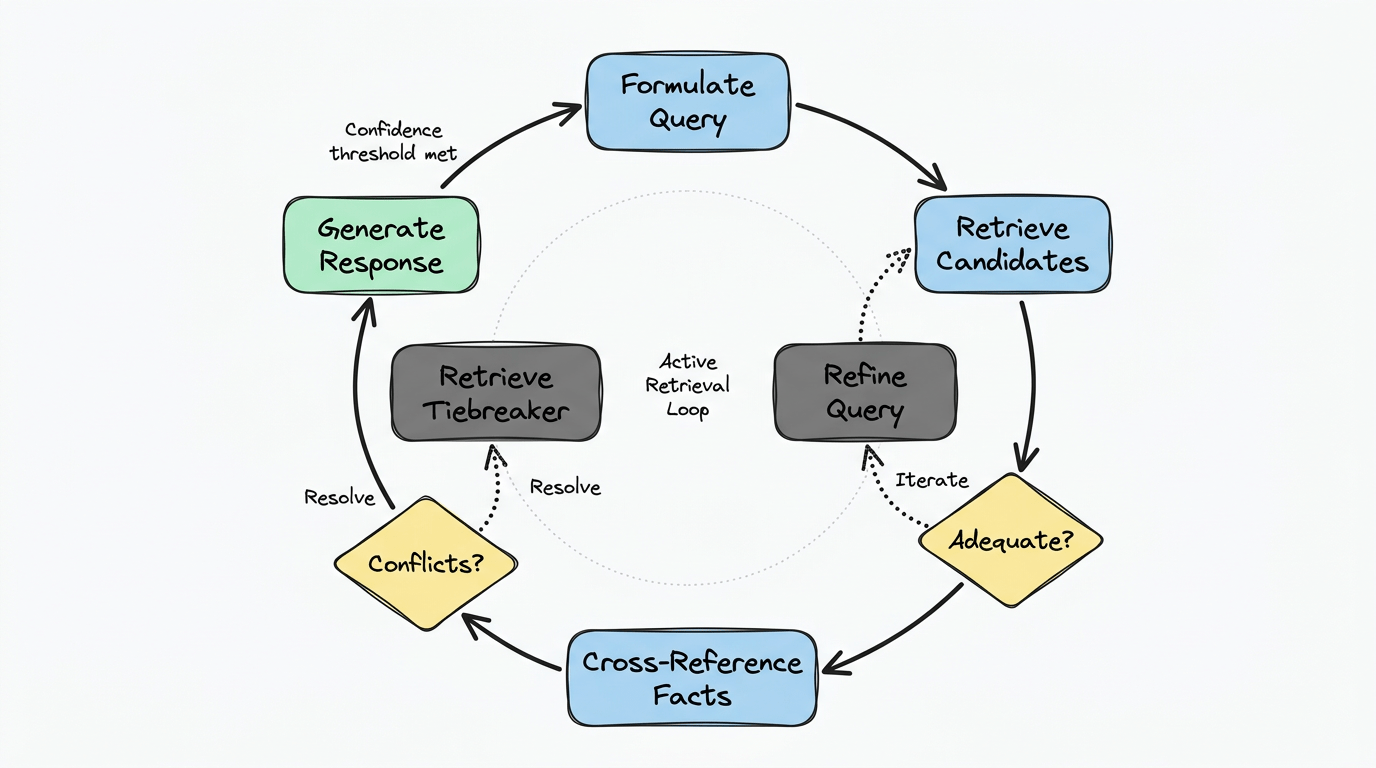
Đây là chuyển đổi kiến trúc cốt lõi: truy xuất không còn là bước cuối trước sinh câu trả lời. Nó là bước đầu trong vòng lặp xác minh.
Mô hình:
- Xây dựng query dựa trên task
- Truy xuất tài liệu ứng viên
- Phê bình chất lượng truy xuất (relevance, coverage, conflict)
- Nếu không đủ, tinh chỉnh query và truy xuất lại
- Cross-reference sự thật giữa các tài liệu
- Nếu có mâu thuẫn, truy xuất nguồn tiebreaker
- Chỉ sinh response khi đạt ngưỡng confidence
Mô hình này yêu cầu agent lý luận về trạng thái kiến thức của chính nó. Nó không thể dựa vào “truy xuất top-3 và hy vọng.” Nó phải đánh giá ba tài liệu đó có thực sự trả lời câu hỏi không, chúng có đồng ý với nhau không, và nó có cần thêm thông tin không.
Self-RAG triển khai điều này với reflection token. Hệ thống khác dùng verification tool rõ ràng—agent đọc các chunk truy xuất và trả về relevance score trước khi sinh tiếp. Dù thế nào, nguyên tắc vẫn giữ: tin tưởng mù quáng vào truy xuất là bug, không phải feature.
Bộ ba RAG: Context, Groundedness, Relevance
Framework đánh giá RAG hội tụ về ba chiều năm 2025, thường gọi là Bộ ba RAG:
- Context Relevance: Các tài liệu truy xuất có thực sự liên quan đến query không?
- Groundedness: Các claim được sinh có được nội dung truy xuất hỗ trợ không?
- Answer Relevance: Response cuối có thực sự trả lời câu hỏi người dùng không?
Mỗi chiều đo một failure mode khác nhau. Context relevance cao nhưng groundedness thấp nghĩa là retriever hoạt động nhưng generator ảo giác. Groundedness cao nhưng answer relevance thấp nghĩa là model trích nguồn chính xác nhưng trả lời sai câu hỏi.
Insight: chất lượng truy xuất chỉ giải thích khoảng 60% phương sai trong hiệu suất RAG end-to-end, theo nghiên cứu đánh giá 2024-2025. 40% còn lại đến từ model sử dụng context được cho tốt như thế nào. Bạn có thể cải thiện retrieval recall từ 80% lên 95% và chỉ thấy tăng 5-10% chất lượng câu trả lời nếu generation model không biết cách trích xuất và tổng hợp thông tin từ chunk.
Đây là lý do vòng lặp xác minh quan trọng. Chúng không chỉ cải thiện truy xuất—chúng thu hẹp khoảng cách giữa những gì agent truy xuất và những gì nó thực sử dụng.
Phần 6: Memory vs. Knowledge
System Knowledge và Session Memory Không Giống nhau
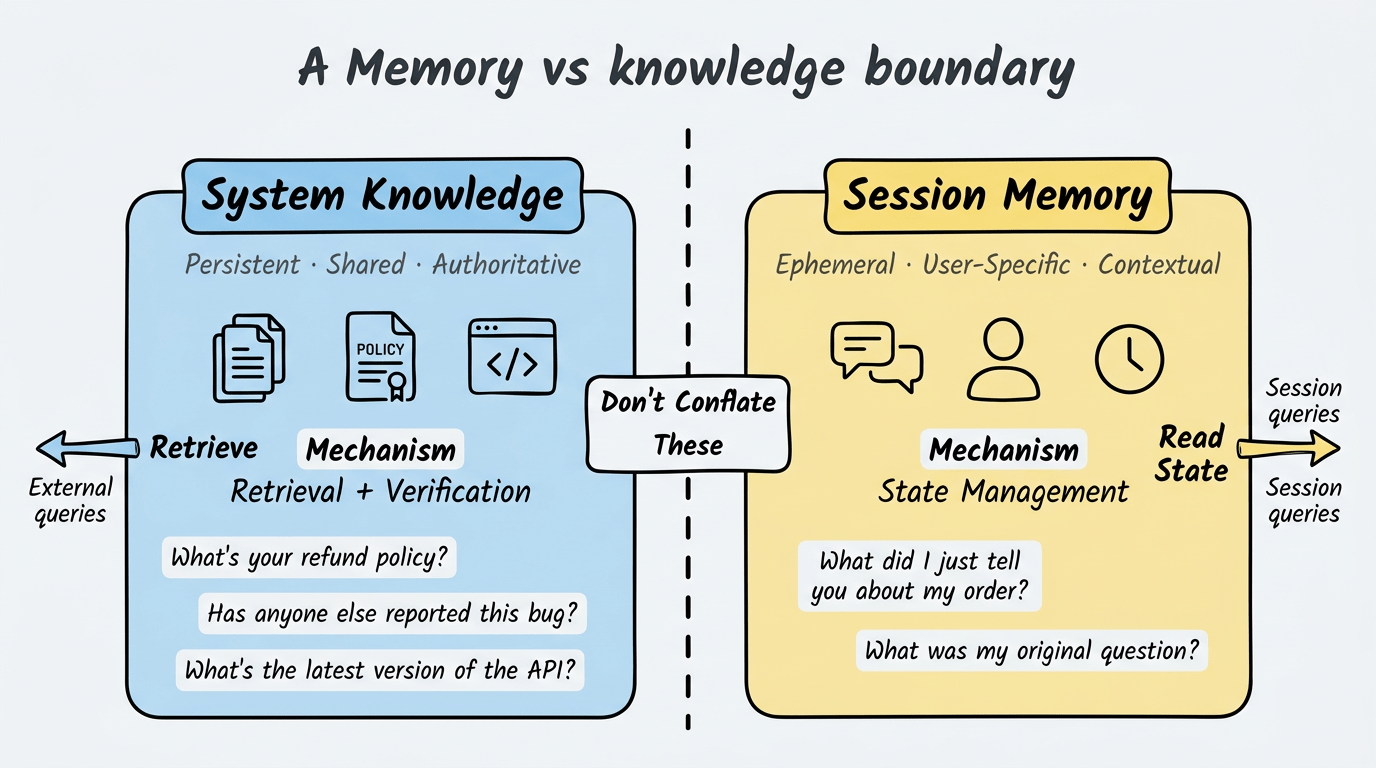
Hệ thống RAG quản lý hai loại thông tin khác nhau về mặt khái niệm, và nhầm lẫn chúng phá vỡ kiến trúc của bạn.
System Knowledge là persistent, shared và authoritative. Tài liệu sản phẩm, chính sách công ty, code repository. Đây là những gì RAG truy xuất—tài liệu tồn tại độc lập với bất kỳ phiên người dùng nào.
Session Memory là ephemeral, user-specific và contextual. Những gì người dùng nói ba message trước. Các tham số họ cung cấp. Trạng thái tài khoản của họ. Điều này sống trong context window, không phải vector database.
RAG đơn giản cố giải quyết cả hai với cùng cơ chế truy xuất. Người dùng hỏi “Tôi đã nói gì trước đó?” và hệ thống tìm trong vector database. Nó thất bại vì session memory không phải vấn đề truy xuất—đó là vấn đề quản lý trạng thái.
Agentic RAG tách biệt các mối quan tâm này. System knowledge đi qua truy xuất (với xác minh). Session memory sống trong managed state mà agent duy trì qua các turn. Agent biết câu hỏi nào cần tài liệu bên ngoài và câu hỏi nào cần nhìn vào conversation history.
Khi nào Truy xuất, Khi nào Nhớ
Decision framework:
| Loại Query | Nguồn | Cơ chế |
|---|---|---|
| “Chính sách hoàn tiền của bạn là gì?” | System knowledge | Truy xuất từ tài liệu, xác minh tính cập nhật |
| “Tôi vừa nói gì về đơn hàng của tôi?” | Session memory | Đọc từ conversation state |
| “Có ai khác báo cáo bug này không?” | System knowledge | Truy xuất từ issue tracker, kiểm tra recency |
| “Câu hỏi ban đầu của tôi là gì?” | Session memory | Scan conversation history |
| “Phiên bản mới nhất của API là gì?” | System knowledge (live) | API call, không phải truy xuất tài liệu |
Ranh giới không phải lúc nào cũng rõ ràng, nhưng nguyên tắc là: truy xuất lấy kiến thức bên ngoài authoritative. Memory truy cập trạng thái session-specific. Agent cần cả hai, và nhầm lẫn chúng dẫn đến hệ thống tìm kiếm thông tin đã có hoặc không lấy thông tin cần thiết.
Phần 7: Lộ trình Di chuyển – Từ Truy xuất Bị động đến Chủ động
Bước 1: Audit Chất lượng Truy xuất Hiện tại
Trước khi thêm lý luận nhiều bước, xác minh truy xuất một bước thực hoạt động. Dùng framework Bộ ba RAG:
- Lấy mẫu 100 production query
- Với mỗi query, kiểm tra top-5 chunk truy xuất
- Chấm điểm context relevance thủ công: Các chunk này có thực hữu ích để trả lời query không?
- Chấm điểm groundedness: Nếu model trích các chunk này, câu trả lời có đúng sự thật không?
- Chấm điểm answer relevance: Response được sinh cuối cùng có trả lời điều người dùng hỏi không?
Nếu bạn có context relevance thấp (truy xuất tệ), sửa embedding, chunk size hoặc indexing strategy trước. Nếu bạn có context relevance cao nhưng groundedness thấp (model bỏ qua nguồn), đó là vấn đề generation. Nếu bạn có groundedness cao nhưng answer relevance thấp (model trả lời sai câu hỏi), đó là vấn đề query understanding.
Agentic RAG không sửa được embedding tệ. Bắt đầu với RAG đơn giản hoạt động, rồi tiến hóa nó.
Bước 2: Thêm Xác minh Rõ ràng trước khi Thêm Vòng lặp Nhiều bước
Mô hình agentic đơn giản nhất: cho hệ thống một công cụ “verify” chấm điểm chất lượng truy xuất trước sinh.
1. Truy xuất top-k tài liệu
2. Gọi verify(query, documents) → relevance_score
3. Nếu relevance_score < ngưỡng:
- Log failure
- Trả "Tôi không tìm thấy thông tin liên quan" thay vì ảo giác
4. Nếu không: tiến hành sinhĐiều này không yêu cầu reflection token hay agent framework. Đây là hàm gatekeeper ngăn garbage-in-garbage-out. Bạn có thể triển khai với kiểm tra embedding distance đơn giản, một classifier nhẹ, hoặc thậm chí LLM prompt: “Đánh giá mức độ liên quan của các tài liệu này với query trên thang 1-10.”
Bước 3: Giới thiệu Truy xuất Nhiều bước cho Query Quan trọng
Không phải query nào cũng cần tinh chỉnh lặp. “Chính sách trả hàng là gì?” có thể trả lời bằng truy xuất một lần. “Tại sao deployment lỗi lúc 3 giờ sáng thứ Ba trước?” có lẽ không.
Giới thiệu truy xuất nhiều bước có chọn lọc:
- Query quan trọng: Tuân thủ, bảo mật, incident response
- Query mơ hồ: Ý định người dùng không rõ, nhiều cách hiểu có thể
- Kết quả mâu thuẫn: Truy xuất đầu trả về thông tin xung đột
Với các trường hợp này, triển khai vòng lặp tinh chỉnh:
1. Truy xuất với query ban đầu
2. Đánh giá: Kết quả đủ không?
3. Nếu không: Reformulate query (mở rộng, thu hẹp hoặc paraphrase)
4. Truy xuất lại
5. Cross-reference kết quả
6. Sinh response chỉ khi đạt ngưỡng confidenceQuan trọng là biết khi nào dừng. Đặt số lần lặp tối đa (thường 2-3) và ngưỡng confidence. Nếu agent không thể tìm kết quả tốt sau ba lần, trả “thông tin không đủ” thay vì lặp mãi.
Bước 4: Mở rộng Stack Truy xuất Vượt Vector
Khi verification và refinement hoạt động, thêm công cụ bổ sung:
- Hybrid search: Kết hợp vector và BM25 keyword search
- Structured query: Để agent viết SQL cho dữ liệu bảng
- API call: Định tuyến yêu cầu dữ liệu live (giá, trạng thái, metric real-time) ra khỏi truy xuất tài liệu
- Graph traversal: Với domain có quan hệ phong phú, thêm knowledge graph query
Kiến trúc agent giữ nguyên—bạn chỉ cho nó thêm công cụ chuyên biệt. Thay vì “retrieve,” agent bây giờ quyết định: Tôi nên dùng semantic search, keyword search, SQL hay API call?
Framework như LangChain cung cấp integration sẵn. Bạn cũng có thể xây dựng custom tool với function calling đơn giản.
Phần 8: Failure Mode và Điều cần Quan sát
Vòng lặp Truy xuất
Hệ thống agentic có thể bị kẹt tinh chỉnh query không bao giờ cho kết quả tốt. Người dùng hỏi về tính năng sản phẩm không tồn tại. Agent truy xuất, tìm kết quả yếu, tinh chỉnh query, truy xuất lại, tìm kết quả yếu, tinh chỉnh query…
Giảm thiểu: Đặt giới hạn cứng cho số lần truy xuất (tối đa 2-3). Nếu tinh chỉnh không cải thiện relevance score, fail gracefully với “Tôi không tìm thấy thông tin về chủ đề đó.”
Over-Verification
Thêm verification step tăng độ trễ và chi phí. Mỗi critique call là một LLM invocation thêm. Với query số lượng lớn, ít quan trọng, overhead không đáng.
Giảm thiểu: Định tuyến query đơn giản qua truy xuất một lần nhanh. Dành xác minh nhiều bước cho yêu cầu phức tạp hoặc quan trọng. Dùng model rẻ hơn (Haiku thay vì Opus) cho verification nếu độ chính xác cho phép.
Contradiction Paralysis
Agent truy xuất nhiều tài liệu với thông tin xung đột. Verification phát hiện conflict, nhưng agent không giải quyết được. Nó truy xuất thêm tài liệu, tìm thêm conflict, và cuối cùng timeout không trả lời.
Giảm thiểu: Xây dựng logic tie-breaking rõ ràng. Ưu tiên tài liệu chính thức hơn bài forum. Đánh trọng nguồn gần đây hơn nguồn lỗi thời. Nếu conflict vẫn tồn tại, bề mặt cho người dùng: “Tôi tìm thấy thông tin xung đột. Nguồn A nói X, Nguồn B nói Y. Cái nào đúng?”
Tool Selection Error
Agent chọn sai công cụ truy xuất cho query. Dùng SQL khi nên dùng semantic search, hoặc ngược lại. Lãng phí thời gian cho tool call không liên quan trước khi tìm được cách đúng.
Giảm thiểu: Cung cấp mô tả tool rõ ràng và ví dụ sử dụng. Monitor mô hình tool selection và thêm heuristic cho query phổ biến. Một số team phân loại trước query (factual vs navigational vs procedural) và định tuyến chúng đến công cụ thích hợp tự động.
Nhìn về Tương lai: Truy xuất Đang đi về Đâu
Truy xuất đang trở thành quá trình lý luận, không chỉ database lookup. Biên giới không phải embedding nhanh hơn hay context window lớn hơn, đó là agent hiểu những gì mình không biết, xây dựng câu hỏi tốt hơn, xác minh nguồn, và tích hợp thông tin qua nhiều modality và công cụ.
Đến 2027, theo dự báo AI doanh nghiệp, workflow phức tạp sẽ mặc định dùng hệ thống multi-agent khi các agent chuyên biệt cộng tác: research agent khám phá không gian thông tin, verification agent cross-check factual claim, synthesis agent kết hợp phát hiện, và governance agent đảm bảo tuân thủ. Truy xuất trở thành lý luận phân tán.
Thách thức không phải năng lực kỹ thuật—các model tiên tiến đã xử lý được lý luận nhiều bước và sử dụng công cụ. Thách thức là vận hành: làm thế nào test, debug và duy trì hệ thống ra quyết định truy xuất tự trị? Làm thế nào monitor vòng lặp truy xuất, mâu thuẫn và tool selection error trong production? Làm thế nào cân bằng lợi ích độ chính xác của xác minh nhiều bước với độ trễ và chi phí của các LLM call bổ sung?
Đây là những câu hỏi định hình giai đoạn tiếp theo của RAG. Chuyển đổi paradigm từ truy xuất bị động sang lý luận chủ động đã ở đây. Cơ sở hạ tầng để vận hành nó ở quy mô vẫn đang được xây dựng.
Viết dựa trên nghiên cứu từ bài báo Self-RAG ICLR 2024, khảo sát Agentic RAG tháng 1/2025 (arXiv:2501.09136), đánh giá ngành RAGFlow 2025, tài liệu Gen AI Security của OWASP, và framework đánh giá RAG doanh nghiệp. Xuất bản tháng 3/2025.
Nguồn & Tài liệu Tham khảo
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection — ICLR 2024
- Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG — arXiv (2025)
- From RAG to Context — A 2025 year-end review of RAG — RAGFlow (2025)
- LLM01:2025 Prompt Injection — OWASP Gen AI Security Project (2025)
- RAG Evaluation Metrics Guide: Measure AI Success 2025 — FutureAGI (2025)
- RAG in 2025: The enterprise guide to retrieval augmented generation, Graph RAG and agentic AI — Data Nucleus (2025)
- PostgreSQL Hybrid Search Using pgvector and Cohere — Tiger Data (2025)
- Azure SQL Database Vector Search — Microsoft GitHub (2025)
- The Next Frontier of RAG: How Enterprise Knowledge Systems Will Evolve (2026-2030) — NStarX Inc. (2024)
- Naive RAG vs. advanced RAG — Meilisearch (2024)