Context as Architecture
Agent của bạn khởi động sáng nay rất tỉnh táo. Đến giờ thứ ba, nó bắt đầu lặp lại. Đến giờ thứ sáu, nó mâu thuẫn với các quyết định đã đưa ra sáng nay.
Đây không phải lỗi của model. Đây là lỗi kiến trúc. LLM stateless không nhớ gì giữa các lượt tương tác. Chúng chỉ nhìn vào lịch sử đã ghép nối mà bạn đưa vào và coi đó là sự thật tuyệt đối, ngay cả khi lịch sử đó phình to với các chi tiết không liên quan, bị nhiễm độc bởi các ảo giác trong quá khứ, hoặc thiếu quyết định quan trọng từ hai giờ trước. Agent không có bộ nhớ. Nó chỉ có một đống text. Khi đống text đó vượt quá khả năng tập trung hiệu quả của model, tính mạch lạc sụp đổ.
Xây dựng agent chạy hàng giờ, hàng ngày hoặc hàng tuần đòi hỏi phải coi context như một hệ thống quản lý với lifecycle, không phải bản ghi cuộc trò chuyện. Bài viết này đi sâu vào memory stack—kiến trúc giúp agent loại bỏ những gì đã cũ, nén những gì hữu ích, lưu checkpoint những gì quan trọng, và reset khi cần bắt đầu lại từ đầu.
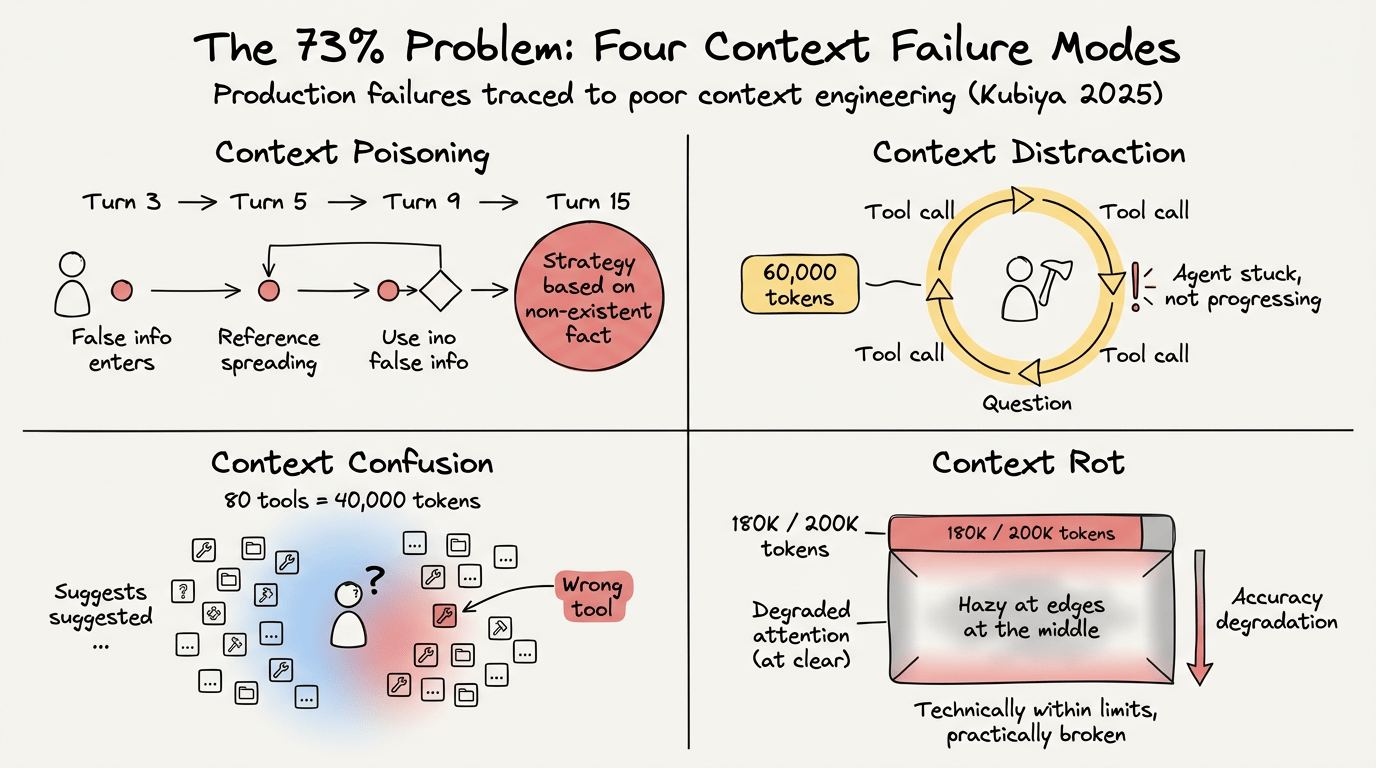
Vấn đề 73%
Hệ thống AI production sống hoặc chết dựa trên cách quản lý context. Theo phân tích năm 2025 của Kubiya về các triển khai doanh nghiệp, 73% lỗi production bắt nguồn từ context engineering kém. Khảo sát của FlowHunt về các dự án AI cho thấy hơn 40% lỗi xuất phát từ việc cung cấp context kém hoặc không liên quan cho model.
Đây không phải edge case. Đây là dạng lỗi phổ biến nhất.
Bốn Dạng Lỗi Context Phổ biến
Những gì thường bị hỏng:
Context Poisoning: Một ảo giác xâm nhập vào context của agent ở lượt 3. Agent tham chiếu thông tin sai đó ở lượt 5, sau đó dùng nó để đưa ra quyết định ở lượt 9. Đến lượt 15, thông tin nhiễm độc đã được trích dẫn năm lần và agent đang theo đuổi chiến lược dựa trên thứ chưa bao giờ tồn tại.
Context Distraction: Lịch sử cuộc trò chuyện tăng lên 60.000 token. Model bắt đầu tập trung quá mức vào các hành động trong quá khứ, lặp lại các lệnh gọi tool đã thực hiện, hỏi lại các câu hỏi đã trả lời. Agent không tiến triển. Nó kẹt trong vòng lặp, phát lại bản ghi của chính nó.
Context Confusion: Agent có quyền truy cập vào 80 tool. Định nghĩa cho cả 80 tool nằm trong context window, tiêu tốn 40.000 token trước khi agent bắt đầu làm việc (xem progressive disclosure). Khi người dùng hỏi một câu hỏi đơn giản, model quét qua các mô tả tool không liên quan, chọn sai tool, và tạo phản hồi không khớp với nhiệm vụ.
Context Rot: Context window là 200.000 token và bạn đang dùng 180.000 trong số đó. Về mặt kỹ thuật, bạn vẫn trong giới hạn. Thực tế, model không thể tập trung (xem agentic RAG). Độ chính xác giảm sút. Agent mắc lỗi ở các tác vụ mà nó xử lý đúng khi context còn gọn.
Do đó, phát hiện từ phân tích “How to Fix Your Context” của Drew Breunig: không có quản lý context có chủ ý, validation, tóm tắt, retrieval có chọn lọc, pruning hoặc cô lập ngay cả context window lớn cũng tạo ra kết quả không đáng tin cậy hoặc không mạch lạc. Tính robust phân biệt hệ thống production với prototype.
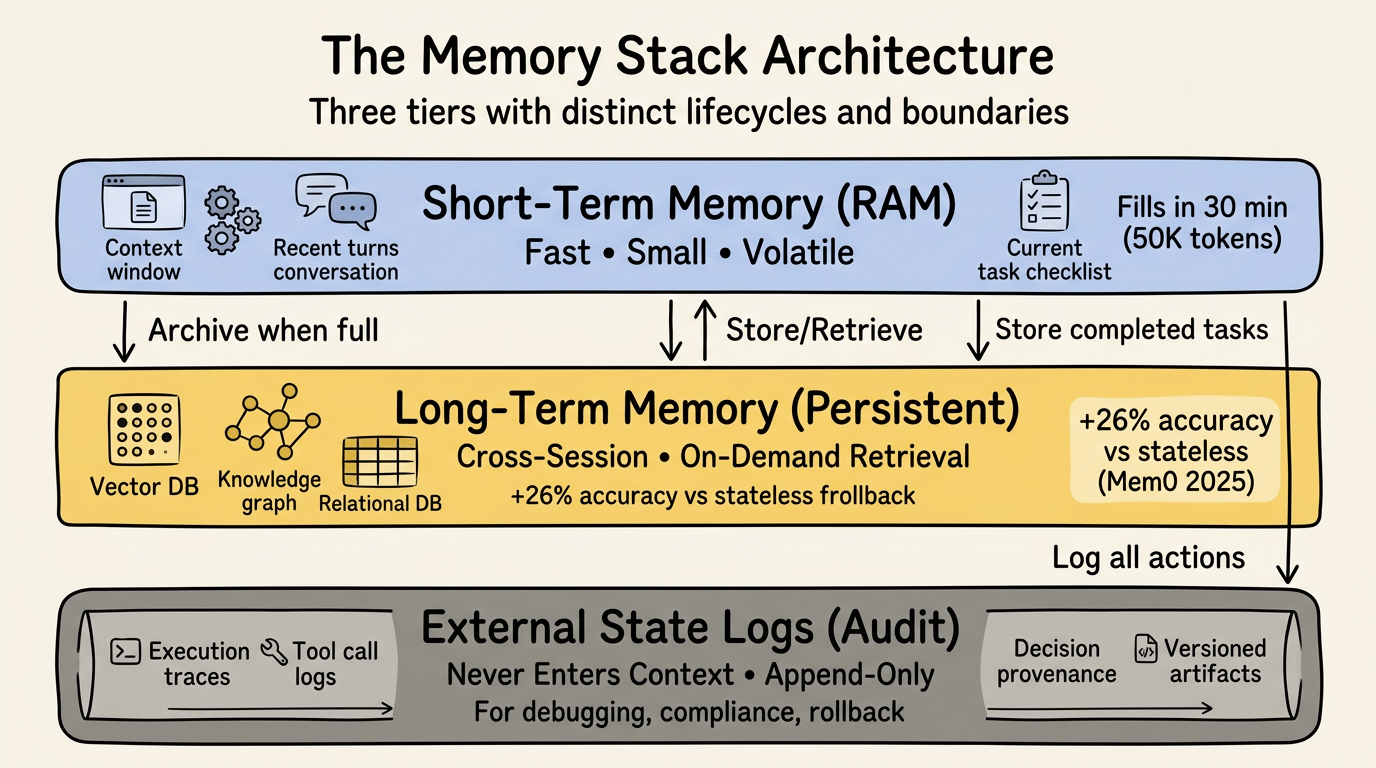
Memory Stack
Nếu muốn agent chạy lâu hơn một lượt tương tác, bạn cần kiến trúc memory. Không chỉ context window. Không chỉ vector database. Một hệ thống phân lớp nơi các thông tin khác nhau nằm ở các cấp độ khác nhau, với quy tắc rõ ràng về thông tin nào di chuyển giữa các lớp và khi nào.
Kiến trúc có ba tầng:
Bộ nhớ ngắn hạn (Working Context)
Đây là context window của LLM prompt trực tiếp, các lượt gần đây, output của tool đang hoạt động và nhiệm vụ đang làm. Hãy nghĩ về nó như RAM. Nhanh, nhỏ, tạm thời. Báo cáo năm 2025 của IBM về bộ nhớ AI agent mô tả bộ nhớ ngắn hạn như khả năng cho phép agent nhớ các input gần đây để ra quyết định ngay lập tức. Đây là những gì model thấy ngay bây giờ.
Bộ nhớ ngắn hạn xóa sạch khi tác vụ hoàn thành hoặc session kết thúc. Nó được quản lý in-context (chính prompt) hoặc trong các biến state tạm thời chỉ tồn tại cho lần thực thi hiện tại. Kiến trúc checkpoint của LangGraph cho phép snapshot state này tại các điểm cụ thể cho phép pause/resume, phê duyệt human-in-the-loop và rollback về các state trước đó.
Tuy nhiên, vấn đề: bộ nhớ ngắn hạn đầy rất nhanh. Mỗi lệnh gọi tool thêm output. Mỗi bước suy luận thêm token. Một coding agent debug vấn đề phức tạp có thể đốt hết 50.000 token trong ba mươi phút. Lúc đó, khả năng tập trung của agent bắt đầu suy giảm. Model mất focus. Lỗi xuất hiện.
Bộ nhớ dài hạn (Persistent Storage)
Đây là nơi lưu trữ thông tin cần tồn tại qua các session. Sở thích người dùng. Quyết định trong quá khứ. Pattern đã học. Những gì đã làm việc, thất bại và tại sao. Theo nghiên cứu do MongoDB và Redis tổng hợp năm 2025, bộ nhớ dài hạn thường được triển khai bằng database, knowledge graph hoặc vector embedding tồn tại độc lập với bất kỳ cuộc trò chuyện đơn lẻ nào.
Bộ nhớ dài hạn không nằm trong prompt. Nó được truy xuất on-demand khi agent xác định thông tin đó có liên quan. Agent hỏi “Tôi đã gặp user này chưa?” và query database. “Chúng ta đã thử cách tiếp cận này chưa?” và quét episodic log. “Best practice cho tác vụ này là gì?” và search vector store.
Nghiên cứu năm 2025 của Mem0 phát hiện rằng hệ thống persistent memory đạt độ chính xác phản hồi cao hơn 26% so với phương pháp stateless. Đó là sự khác biệt giữa prototype và hệ thống production. Tuy nhiên, bộ nhớ dài hạn tạo thêm độ phức tạp. Bạn không còn debug một prompt. Bạn đang debug một hệ thống retrieval, một lớp storage và logic quyết định khi nào fetch cái gì.
External State Logs (Observability & Audit)
Đây là thứ không bao giờ vào context của model nhưng phải được bảo toàn để debug, compliance và rollback. Full execution trace. Tool call log. Decision provenance. Versioned artifact. Bạn không đưa vào LLM, bạn log nó để con người (hoặc hệ thống audit) có thể replay những gì đã xảy ra.
External state log trả lời câu hỏi “Tại sao agent làm vậy?” Khi agent đưa ra quyết định sai trong production, bạn cần tái tạo lại context chính xác mà nó thấy, các tool nó có quyền truy cập và đường đi suy luận mà nó đi theo. Framework AgentOps 2025 của Microsoft nhấn mạnh grounding và memory với retrieval qua các hệ thống ghi chép, cộng với kiểm soát human-in-the-loop với các checkpoint được nhắm mục tiêu, escalation và khả năng pause hoặc revert hành động.
Tuy nhiên, các log không cải thiện suy luận của agent. Chúng làm cho lỗi có thể debug được và quyết định có thể audit được.
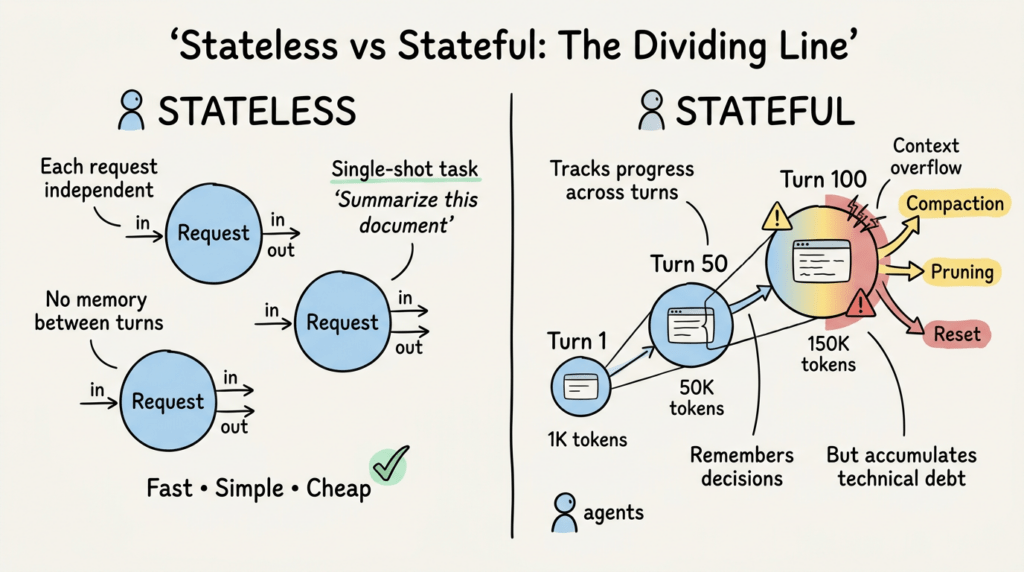
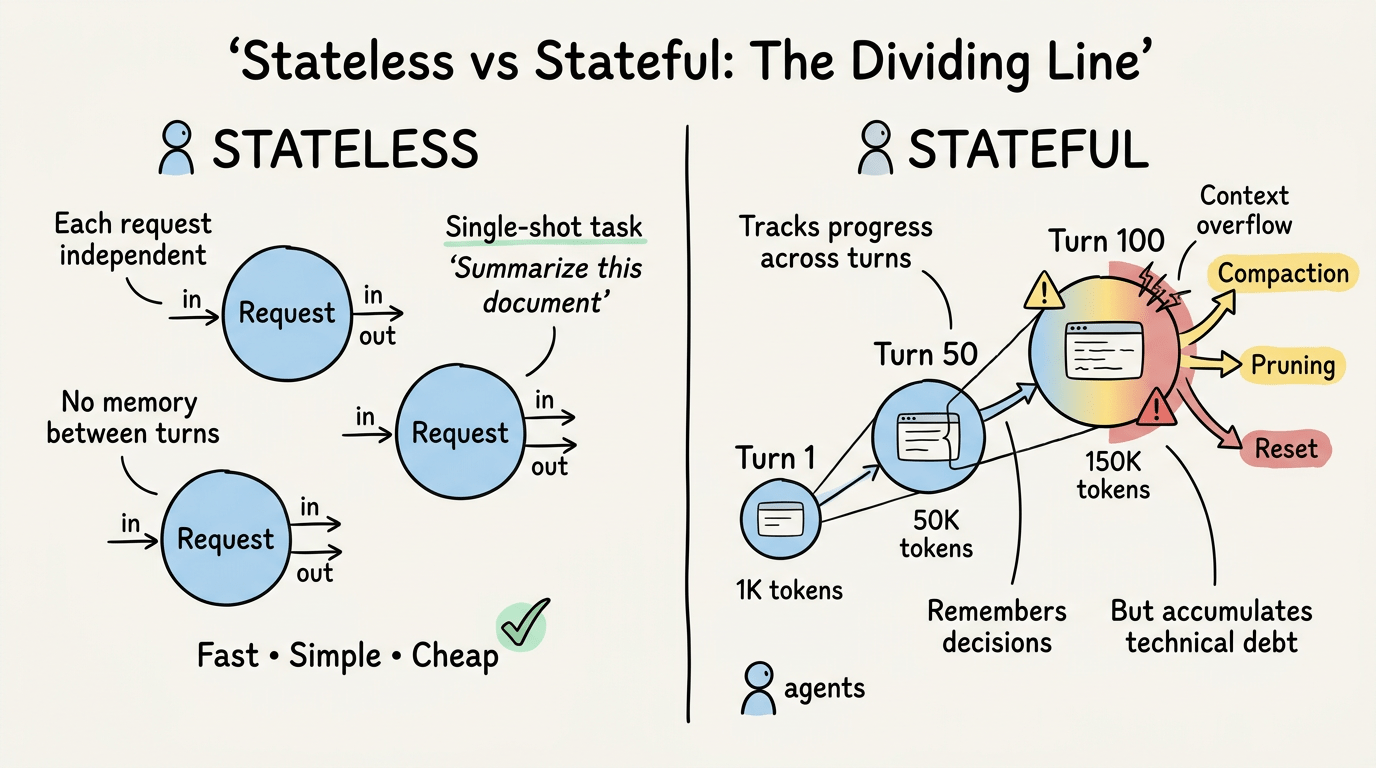
Stateless Chết, Stateful Sống
Đây là ranh giới phân chia: agent stateless coi mỗi yêu cầu như độc lập. Agent stateful duy trì tính liên tục qua các lượt, session, thậm chí cả deployment.
Stateless hoạt động cho các tác vụ single-shot. User hỏi “Tóm tắt tài liệu này.” Agent đọc, tóm tắt, trả kết quả. Xong. Không cần nhớ. Không cần quản lý state. Nhanh, đơn giản, rẻ.
Ngược lại, stateful trở nên cần thiết ngay khi bạn cần agent theo dõi tiến độ, nhớ quyết định hoặc tiếp tục sau khi bị gián đoạn. Workflow nhiều bước. Trợ lý cá nhân hóa. Tác vụ chạy dài kéo dài hàng giờ hoặc hàng ngày. Hệ thống phải sống sót qua các lần khởi động lại process mà không mất vị trí.
Hơn nữa, theo phân tích của Letta về kiến trúc agent stateful, state cho phép agent xây dựng dựa trên thông tin trong quá khứ, học từ sai lầm và xử lý các mục tiêu phức tạp, dài hạn. Agent không chỉ phản hồi, nó tiến hóa. Sở thích trở nên sắc bén. Sai lầm được ghi lại và tránh lần sau. Hành vi của agent thích nghi dựa trên kinh nghiệm tích lũy.
Nhưng agent stateful tích lũy nợ kỹ thuật dưới dạng context cũ. So sánh năm 2025 của Daffodil Software về agent stateful vs stateless nêu bật thách thức cốt lõi: developer thường tích lũy lịch sử cuộc trò chuyện ở client và gửi toàn bộ lịch sử với mỗi yêu cầu. Chi phí token tăng tuyến tính theo độ dài cuộc trò chuyện. Giới hạn context window buộc phải cắt bớt các message cũ hơn. Latency tăng khi prompt phình to.
Cuối cùng, bạn chạm tường. Ví dụ, cuộc trò chuyện đã 100 lượt. Lịch sử là 150.000 token. Agent không thể thấy quyết định quan trọng từ lượt 12 vì nó bị chôn vùi dưới 80 lượt đối thoại tiếp theo. Bạn cần compaction, pruning hoặc reset. Nếu không, agent chết chìm trong bộ nhớ của chính nó.
Pruning Strategy: Giữ gì, Bỏ gì
Context pruning có nguồn gốc từ NLP cổ điển, nhưng mức độ quan trọng cao hơn với agent. Ví dụ, cắt quá mạnh, bạn mất tính mạch lạc. Cắt quá ít, bạn gặp context rot. Chiến lược phụ thuộc vào loại thông tin bạn đang quản lý.
Attention-Weighted Pruning
Loại bỏ nội dung mà model hầu như không chú ý đến. Điều này yêu cầu quyền truy cập vào attention weight, mà hầu hết production API không cung cấp, nhưng khi có sẵn, đây là con dao phẫu chính xác. Tài liệu Agent Development Kit của Google về nén context mô tả attention-weighted pruning như việc loại bỏ nội dung low-attention giữa session. Nếu model không dùng, nó là nhiễu.
Tuy nhiên, đánh đổi: attention weight biến động. Nội dung có low-attention ở lượt 5 có thể trở nên quan trọng ở lượt 20 khi tác vụ thay đổi. Prune nó, và bạn đã tạo ra khoảng trống kiến thức mà agent không thể khôi phục.
Relevance Decay
Thông tin cũ hơn được hạ ưu tiên theo thời gian trừ khi được đánh dấu rõ ràng là persistent. Một chỉ dẫn tác vụ từ hai giờ trước có thể vẫn liên quan. Một output debug từ hai giờ trước có lẽ đã cũ. Framework ADK của Google áp dụng relevance decay để hạ ưu tiên nội dung cũ hơn dựa trên thời gian và topic drift.
Cách này hoạt động tốt cho agent đàm thoại nơi chủ đề tự nhiên thay đổi. Ngược lại, nó hỏng khi các tác vụ chạy dài yêu cầu tài liệu tham khảo ổn định phải tồn tại không đổi hàng giờ hoặc hàng ngày.
Anchored Iterative Summarization
Cách tiếp cận của Factory.ai về nén context: khi context gần đến ngưỡng (ví dụ 128.000 token), hệ thống chỉ tóm tắt phạm vi mới bị cắt và merge với bản tóm tắt hiện có. Bản tóm tắt được cấu trúc session intent, file modification, quyết định đã đưa ra, bước tiếp theo để agent biết tìm cái gì ở đâu.
Tuy nhiên, đây là nén lossy. Bạn tin tưởng một LLM để chắt lọc những gì quan trọng, sau đó loại bỏ dữ liệu thô. Nếu quá trình tóm tắt bỏ sót một chi tiết quan trọng, chi tiết đó mất vĩnh viễn. Bạn không thể truy xuất nó sau. Quá trình nén là một chiều.
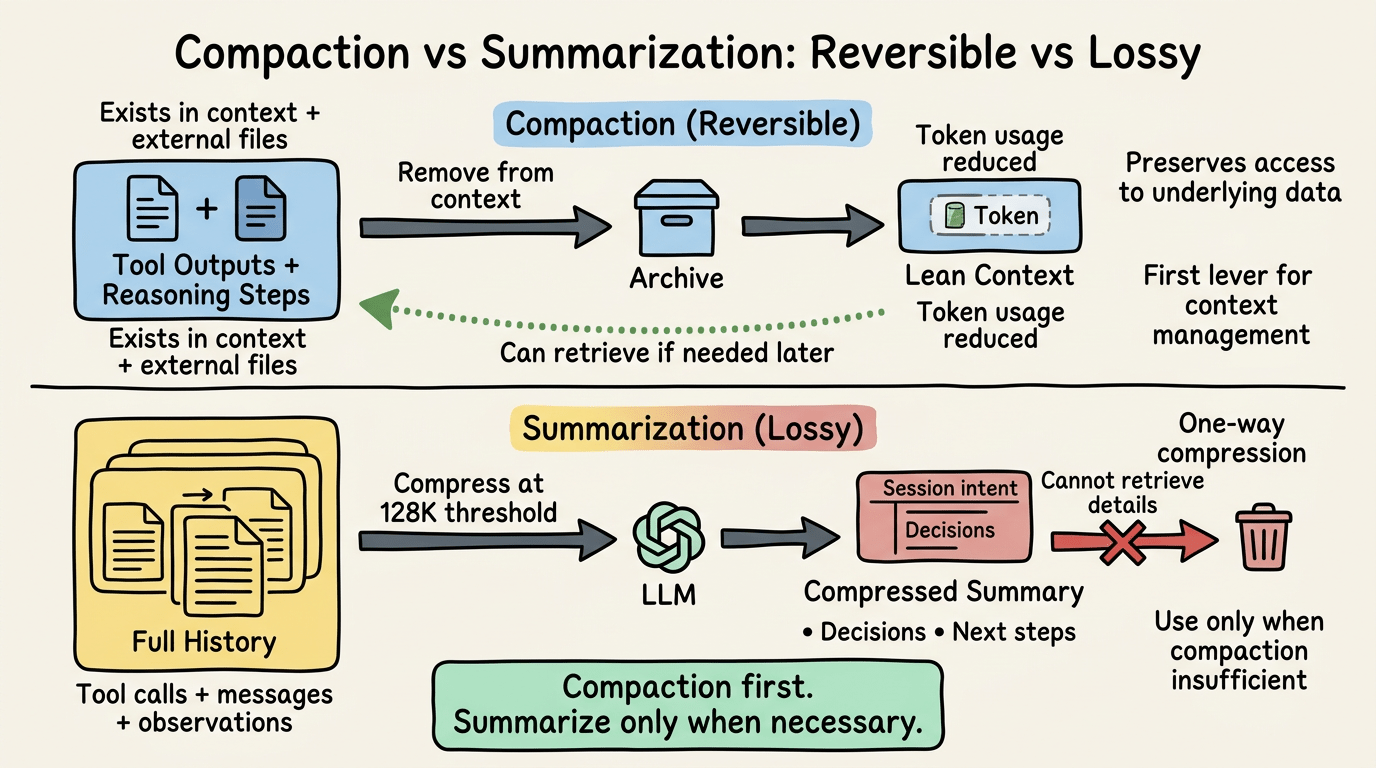
Compaction vs Tóm tắt: Reversible vs Lossy
Thuật ngữ quan trọng. Compaction và tóm tắt không phải cùng một thao tác.
Compaction là reversible. Bạn loại bỏ thông tin dư thừa vì nó tồn tại ở nơi khác trong môi trường. Output của tool đã được log vào file? Loại bỏ chúng khỏi context; agent có thể đọc lại file nếu cần. Các bước suy luận trung gian dẫn đến quyết định cuối cùng? Lưu trữ chúng; agent có thể fetch archive nếu cần xem lại logic. Compaction giảm sử dụng token mà không mất quyền truy cập vào dữ liệu nền.
Tóm tắt là lossy. Bạn dùng một LLM để nén lịch sử, bao gồm tool call, message và observation thành dạng ngắn hơn, sau đó loại bỏ bản gốc. Bạn đặt cược bản tóm tắt nắm bắt những gì quan trọng và các chi tiết gốc sẽ không cần nữa. Theo tài liệu của Google ADK, khi đạt ngưỡng có thể cấu hình (như số lượng invocation), hệ thống kích hoạt process bất đồng bộ sử dụng LLM để tóm tắt các event cũ hơn qua sliding window và ghi bản tóm tắt trở lại session như một event mới.
Do đó, phát hiện chính từ nghiên cứu context engineering: compaction nên là đòn bẩy đầu tiên của bạn. Chỉ tóm tắt khi compaction không thể giảm sử dụng token đủ thấp. Compaction bảo toàn tùy chọn truy xuất chi tiết sau. Tóm tắt đốt cháy tùy chọn đó để đổi lấy nén.
Checkpoint: Save State cho Agent
Cơ chế checkpoint của LangGraph, như được ghi trong hướng dẫn 2025 của SparkCo, lưu state đầy đủ của agent tại mỗi node trong execution graph. Điều này cho phép các tính năng mà hệ thống production cần: retry logic khi một bước thất bại, phê duyệt human-in-the-loop trước các hành động rủi ro cao, rollback về các state trước đó khi agent đi lạc hướng và replay từ checkpoint sau khi chỉnh sửa prompt hoặc tham số.
Cụ thể, một checkpoint nắm bắt mọi thứ agent biết tại thời điểm đó: lịch sử cuộc trò chuyện, working memory, output của tool, suy luận trung gian, kế hoạch hiện tại. Nếu agent mắc lỗi ba bước sau đó, bạn rollback về checkpoint và chạy lại với input đã sửa. Bạn không mất công việc đã làm trước đó.
Tuy nhiên, checkpoint không miễn phí. Mỗi checkpoint tiêu tốn storage. Truy xuất checkpoint thêm latency. Hệ thống với chính sách checkpoint tích cực có thể tạo hàng trăm snapshot mỗi giờ, lấp đầy database với state hiếm khi được truy cập. Cân bằng: checkpoint tại các điểm quyết định, thời điểm agent cam kết với một đường đi và các bước tương lai phụ thuộc vào cam kết đó. Đừng checkpoint mỗi lần tạo token. Checkpoint khi agent hoàn thành lập kế hoạch, hoàn thành tool call, nhận phê duyệt từ user hoặc đạt ranh giới giai đoạn tự nhiên.
Ngoài ra, LangGraph cung cấp nhiều checkpoint storage backend: InMemorySaver cho test tạm thời, SqliteSaver cho persistence cục bộ, PostgresSaver cho triển khai production với độ bền và khả năng phục hồi process. Kiến trúc giống nhau bất kể backend, state được serialize, lưu trữ với thread ID và checkpoint ID, và truy xuất khi cần.
Versioning: Khi Context trở thành Deployment Artifact
Nếu agent của bạn dùng bộ nhớ dài hạn, knowledge base bên ngoài và định nghĩa tool thay đổi theo thời gian, bạn đang quản lý một hệ thống versioned dù có cố ý hay không. Theo nghiên cứu của NJ Raman năm 2025, 60% lỗi agent production gây ra bởi các vấn đề tool versioning.
Những gì bị hỏng: Bạn triển khai version 2 của một tool thay đổi API contract. Các memory cũ trong long-term storage của agent tham chiếu schema version 1. Agent truy xuất một memory, cố dùng nó với tool version 2, và thất bại. Hoặc tệ hơn, nó thành công với dữ liệu bị hỏng vì schema mismatch không bị bắt.
Giải pháp là phân loại versioning bốn lớp:
- Cognitive layer: System prompt, chỉ dẫn suy luận, guardrail
- Model layer: LLM nào, version nào, tham số nào
- Knowledge context: RAG corpus, vector embedding, persistent memory
- Tool contract: API schema, function signature, input/output mong đợi
Đặc biệt, mỗi lớp version độc lập. Bạn có thể cập nhật model mà không đổi tool. Bạn có thể cập nhật tool mà không đổi knowledge base. Nhưng bạn phải theo dõi những gì thay đổi và đảm bảo logic rollback tôn trọng cả bốn lớp. Rollback code mà không rollback context tạo ra hành vi không nhất quán, không thể dự đoán.
Hơn nữa, phân tích của NJ Raman nêu bật một ràng buộc quan trọng: một số agent không bao giờ nên rollback. Agent với bộ nhớ dài hạn gắn với sự kiện kinh doanh, giao dịch tài chính, quyết định pháp lý, workflow chuỗi, nên được “rolled forward,” không phải revert. Rollback có nguy cơ nhân đôi hành động, làm hỏng state hoặc tạo xung đột với các hệ thống downstream đã xử lý output của agent.
Pattern production: blue-green deployment. Duy trì hai môi trường. Triển khai version mới lên green trong khi blue xử lý lưu lượng production. Dần dần chuyển tải sang green. Giám sát suy giảm. Nếu metric giảm dưới ngưỡng, định tuyến lưu lượng trở lại blue. Cả hai môi trường duy trì context storage riêng, vì vậy rollback không làm hỏng state.
Khi nào Xóa sạch Slate
Context destruction là tính năng, không phải bug. Đôi khi nước đi tốt nhất là loại bỏ state tích lũy và tái tạo một môi trường mới từ các bản tóm tắt cấp cao.
Khi drift trở nên persistent. Ví dụ, agent đã chạy 18 giờ. Nó đã thực hiện 500 tool call. Lịch sử cuộc trò chuyện là một mớ hỗn độn của debugging output, kết quả trung gian và các cách tiếp cận bị bỏ. Chất lượng suy luận của agent đang suy giảm. Bạn đã thử tóm tắt. Bạn đã thử pruning. Vẫn không đủ. Do đó, giải pháp: xóa slate, trích xuất một bản tóm tắt có cấu trúc về quyết định và kết quả, bắt đầu session mới với bản tóm tắt đó làm seed context.
Khi user context switch. Agent đang giúp User A debug API issue. User B bắt đầu cuộc trò chuyện mới về database migration. Nếu agent là stateful và bạn không reset, session của User B kế thừa context còn sót lại từ session của User A, một vấn đề bảo mật và vấn đề mạch lạc. Reset đảm bảo ranh giới sạch giữa các user.
Khi hoàn thành tác vụ cung cấp ranh giới tự nhiên. Agent đã hoàn thành tác vụ coding. Test pass. Code được commit. Không có lý do để mang working memory của tác vụ đó vào tác vụ tiếp theo. Xóa bộ nhớ ngắn hạn, lưu trữ kết quả vào bộ nhớ dài hạn, bắt đầu mới.
Hướng dẫn của Skywork về reset LLM context lưu ý rằng hard reset nên khớp với thời lượng tác vụ thực tế. Reset hàng ngày mặc định lúc 4:00 sáng giờ địa phương,. một lựa chọn an toàn cho hầu hết workflow. Idle timeout reset ngăn các session bị bỏ rơi tiêu tốn tài nguyên vô thời hạn. Task-completion reset căn chỉnh lifecycle memory với ranh giới tác vụ tự nhiên.
Tài liệu OpenAI Agents SDK về session memory nhấn mạnh rằng trimming cấp session và tóm tắt ngăn “kế hoạch hôm qua” ghi đè yêu cầu hôm nay. Không có logic reset rõ ràng, agent kẹt trong quá khứ. Chúng coi chỉ dẫn cũ như mục tiêu hiện tại. Chúng bỏ qua input mới vì context bão hòa với dữ liệu lịch sử.
Reset không phải lỗi. Chúng là vệ sinh.
Giải pháp thay thế Observational Memory
Không phải mọi agent đều cần vector database. Một số workflow hưởng lợi từ kiến trúc đơn giản hơn.
Observational memory, được phát triển bởi Mastra và phân tích trong báo cáo 2025 của VentureBeat, dùng hai agent nền, Observer và Reflector để nén lịch sử cuộc trò chuyện thành observation log có ngày tháng. Không có vector database. Không có graph database. Chỉ một định dạng text mà agent đọc như notebook.
Về mặt kinh tế: với khối lượng công việc text-heavy, observational memory đạt nén 3-6x. Với các tác vụ agent tool-heavy, tỷ lệ nén đạt 5-40x. Kiến trúc đơn giản hơn giúp debug dễ hơn không có embedding pipeline để khắc phục sự cố, không có retrieval ranking để điều chỉnh. Và context ổn định, cached cho phép prompt caching, nơi các nhà cung cấp giảm chi phí token 4-10x cho truy cập lặp lại vào cùng base context.
Tuy nhiên, đánh đổi: observational memory ưu tiên những gì agent đã thấy và quyết định hơn là tìm kiếm corpus bên ngoài rộng hơn. Nó hoạt động tốt cho coding agent, debugging workflow và các tác vụ chạy dài với context ổn định. Nó ít phù hợp cho open-ended knowledge discovery hoặc các tình huống recall compliance-heavy nơi bạn cần semantic search toàn corpus.
Điểm quyết định: nếu agent của bạn chủ yếu suy luận qua các hành động và output trong quá khứ của chính nó, observational memory rẻ hơn và đơn giản hơn RAG. Nếu agent của bạn cần tìm kiếm qua hàng nghìn tài liệu agent chưa bao giờ thấy, bạn vẫn cần vector retrieval.
Multi-Agent Memory Coordination: Vấn đề chưa giải quyết
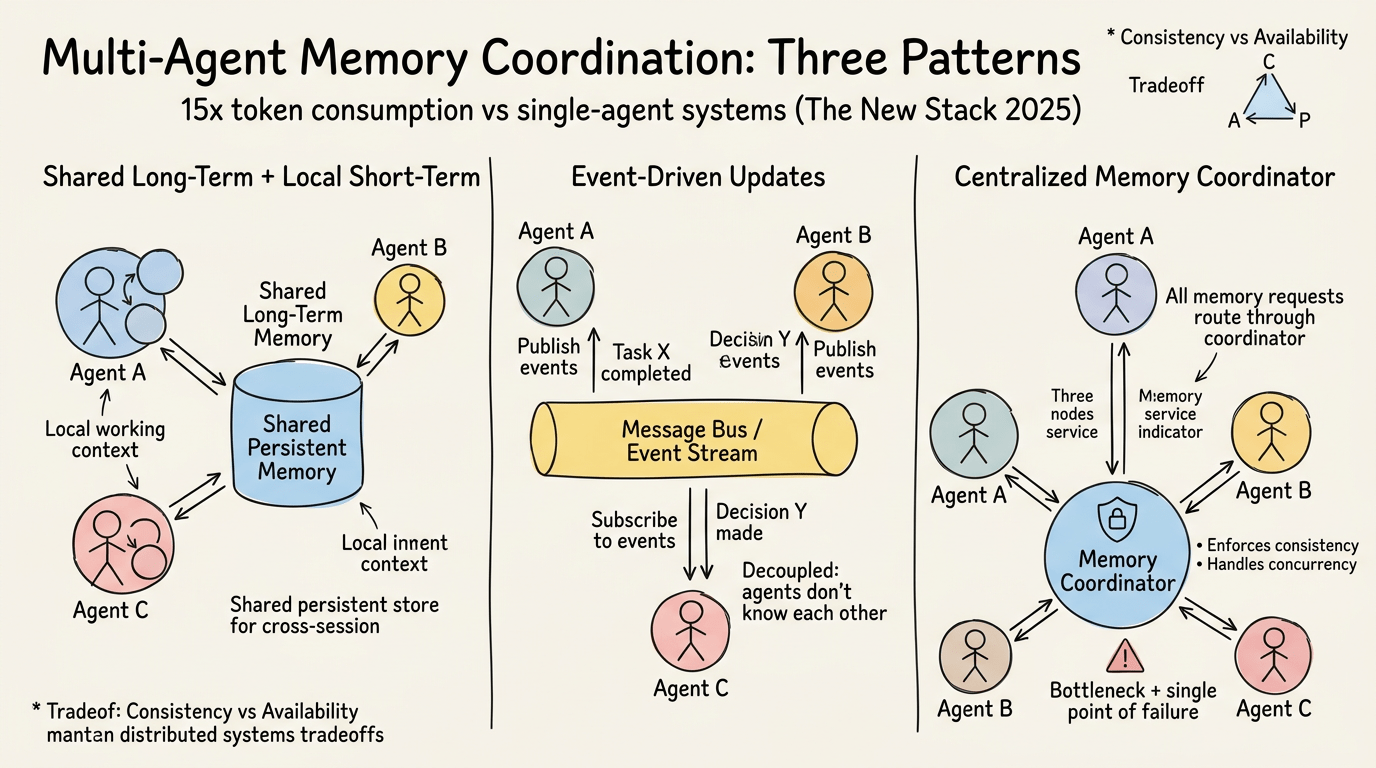
Thách thức khó nhất năm 2025 không phải quản lý memory cho một agent duy nhất. Nó là phối hợp memory qua nhiều agent chạy song song.
Chẳng hạn, theo phân tích của The New Stack về hệ thống agentic memory, thiết lập multi-agent tiêu thụ khoảng 15 lần token hơn các cuộc trò chuyện single-agent. Vấn đề không chỉ là khối lượng mà là tính nhất quán. Agent A cập nhật shared state. Agent B đọc state cũ vì cache của nó chưa refresh. Agent C đưa ra quyết định dựa trên thông tin không đầy đủ vì memory update của Agent A chưa lan truyền.
Thực tế, bạn không còn quản lý một memory stack. Bạn đang quản lý một hệ thống phân tán với các thách thức cổ điển: eventual consistency, race condition, conflict resolution và CAP theorem. Bạn ưu tiên consistency (tất cả agent thấy cùng state, nhưng update chậm hơn)? Hay availability (agent tiến hành với state có thể cũ để tránh blocking)?
Các triển khai production năm 2025 đang hội tụ về một vài pattern:
Shared long-term memory với local short-term cache. Mỗi agent duy trì working context riêng (bộ nhớ ngắn hạn) nhưng đọc và ghi vào persistent store dùng chung (bộ nhớ dài hạn). Xung đột được giải quyết tại storage layer bằng last-write-wins, versioned update hoặc conflict-free replicated data type (CRDT).
Event-driven memory update. Agent publish event (“Task X hoàn thành,” “Quyết định Y đã đưa ra”) lên message bus. Agent khác subscribe các event liên quan và cập nhật local state tương ứng. Điều này tách rời agent chúng không cần biết về nhau, chỉ cần về các event mà chúng quan tâm.
Centralized memory coordinator. Một dịch vụ chuyên dụng quản lý tất cả memory read và write. Agent gửi yêu cầu đến coordinator, nơi thực thi chính sách consistency, xử lý đồng thời và đảm bảo không có hai agent làm hỏng cùng memory. Điều này đơn giản hóa logic agent nhưng tạo bottleneck và single point of failure.
Không cái nào hoàn hảo. Multi-agent memory coordination vẫn là một lĩnh vực nghiên cứu tích cực, với các paper mới được xuất bản hàng tháng. Khảo sát 2026 “Memory in the Age of AI Agents” được cập nhật vào tháng 1 để kết hợp công trình gần đây như Agentic Memory (quản lý long/short-term thống nhất), MemRL (agent tự tiến hóa qua runtime reinforcement learning) và EverMemOS (một hệ điều hành memory tự tổ chức cho suy luận dài hạn).
Production Pattern hoạt động
Những gì thực sự shipping năm 2025:
Hybrid storage backend. Vector database cho semantic retrieval, relational database cho structured state, key-value store cho fast lookup và graph database cho entity relationship. Mem0, công ty huy động 24 triệu USD vào tháng 10 năm 2025 và trở thành nhà cung cấp memory độc quyền của AWS, dùng chính xác cách tiếp cận hybrid này kết hợp vector, key-value và graph store để đạt độ chính xác cao hơn và latency thấp hơn các hệ thống single-backend.
Proactive compaction. Đừng chờ context window tràn. Chạy background process liên tục compact context khi agent làm việc. Google ADK kích hoạt tóm tắt bất đồng bộ khi đạt ngưỡng có thể cấu hình, nén các event cũ hơn qua sliding window và ghi tóm tắt trở lại như các event mới.
Decision-point checkpoint. Checkpoint khi agent cam kết với một đường đi, không phải ở mọi bước. Lưu state sau giai đoạn lập kế hoạch, sau phê duyệt user, sau hoàn thành milestone lớn. Điều này giữ khối lượng checkpoint có thể quản lý trong khi bảo toàn khả năng rollback khi mọi thứ sai.
Layered reset policy. Bộ nhớ ngắn hạn xóa sau mỗi tác vụ. Bộ nhớ dài hạn tồn tại qua các session nhưng được prune theo lịch hàng tuần hoặc hàng tháng (với lưu trữ cho compliance). External log là append-only và không bao giờ bị xóa, nhưng chúng không vào context của agent chúng dành cho con người, không phải model.
Explicit session boundary. Agents SDK của OpenAI, LangGraph và Agent Skills của Anthropic đều thực thi cô lập session. Mỗi session nhận một ID duy nhất. State không rò rỉ giữa các session. Reset rõ ràng, không phải vô tình. Điều này ngăn cơn ác mộng bảo mật khi User B thấy state còn sót lại từ session của User A.
Nhìn về Tương lai: Memory như Policy
Context window tiếp tục tăng. Gemini 2.0 shipping với 2 triệu token. GPT-5 có thể sẽ vượt quá con số đó. Nhưng raw capacity không giải quyết vấn đề kiến trúc. Như Anthropic nói tại AWS re:Invent 2025: “Claude đã đủ thông minh intelligence không phải bottleneck, context mới là.”
Biên giới năm 2026 không phải về nhét nhiều token hơn. Nó về memory policy: model được phép nhớ gì, bao lâu và dưới sự kiểm soát của ai. AI safety đang lặng lẽ trở thành memory policy.
User không muốn agent quên mọi thứ giữa các session. Họ cũng không muốn agent nhớ mọi thứ mãi mãi. Câu trả lời đúng phụ thuộc vào tác vụ, sở thích của user và ràng buộc quy định. Một agent hỗ trợ khách hàng nên nhớ vấn đề của user qua một ticket nhiều ngày. Nó không nên nhớ vấn đề mãi mãi. Một coding agent nên nhớ context dự án trong khi PR đang mở. Nó nên quên khi code merge.
Memory lifecycle management nhớ gì, giữ bao lâu, khi nào compact, khi nào xóa sẽ là thách thức vận hành quyết định của các hệ thống agent production. Công cụ đã tồn tại. LangGraph cho checkpoint. Mem0 và Letta cho persistent memory. Google ADK cho compaction. Redis và PostgreSQL cho storage. Những gì còn thiếu là kỷ luật: các chính sách, quản trị, audit trail chứng minh agent đã nhớ đúng thứ và quên những thứ nguy hiểm.
Cuối cùng, kiến trúc không chỉ là code. Nó là các quy tắc lifecycle giữ cho context không trở thành một trách nhiệm pháp lý.
Viết dựa trên nghiên cứu từ phân tích context engineering 2025 của Kubiya, nghiên cứu persistent memory của Mem0, báo cáo observational memory của VentureBeat, tài liệu checkpoint của LangGraph, pattern compaction context của Google ADK và khảo sát “Memory in the Age of AI Agents” (arXiv:2512.13564, cập nhật tháng 1 năm 2026). Xuất bản tháng 3 năm 2026.
Nguồn & Tham khảo
- Memory in the Age of AI Agents — arXiv (2025)
- Memory for AI Agents: A New Paradigm of Context Engineering — The New Stack (2025)
- Context Engineering Best Practices for Reliable AI in 2025 — Kubiya (2025)
- How to Fix Your Context — Drew Breunig (2025)
- Context Engineering: The Definitive 2025 Guide — FlowHunt (2025)
- Stateful vs Stateless AI Agents: Know Key Differences — Daffodil Software (2025)
- Stateful Agents: The Missing Link in LLM Intelligence — Letta (2025)
- ‘Observational memory’ cuts AI agent costs 10x and outscores RAG — VentureBeat (2025)
- Versioning, Rollback & Lifecycle Management of AI Agents — Medium / NJ Raman (2025)
- Mastering LangGraph Checkpointing: Best Practices for 2025 — SparkCo (2025)
- Context compression — Agent Development Kit (ADK) — Google (2025)
- Evaluating Context Compression for AI Agents — Factory.ai (2025)
- What Is AI Agent Memory? — IBM (2025)
- How to Build AI Agents with Redis Memory Management — Redis (2025)
- What Is Agent Memory? — MongoDB (2025)
- AI Memory Research: 26% Accuracy Boost for LLMs — Mem0 (2025)
- Sessions — OpenAI Agents SDK (2025)
- How to Reset LLM Context — Skywork (2025)
- Context Engineering – Short-Term Memory Management with Sessions — OpenAI Cookbook (2025)
- From Zero to Hero: AgentOps — Microsoft Community Hub (2025)
- Making Sense of Memory in AI Agents — Leonie Monigatti (2025)
- Memory – Docs by LangChain (2025)