Tuần trước, một team nhận requirement: “Build chatbot trả lời câu hỏi về sản phẩm cho khách hàng.” Chưa đầy 2 tiếng sau, đã có người mở Notion lên viết: “Mình cần dựng vector database, chọn embedding model, setup Pinecone…”
Nghe quen không? Năm 2015, mọi thứ phải microservices. Năm 2018, mọi thứ phải Kubernetes. Năm 2024, mọi thứ phải RAG.
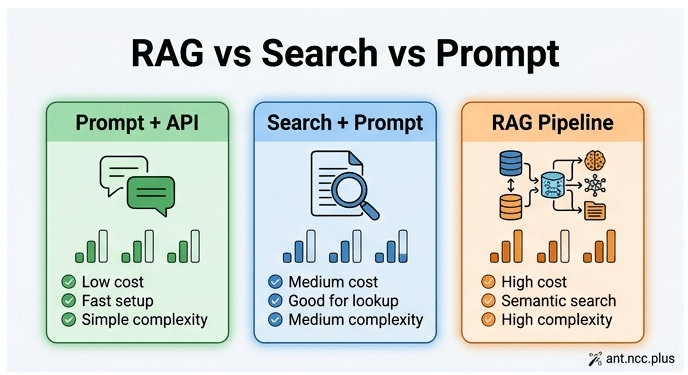
Vấn đề không phải ở chỗ RAG xấu. Tuy nhiên, nó đang trở thành câu trả lời mặc định cho mọi bài toán AI, kể cả những bài toán mà một cái search đơn giản + prompt engineering là xong việc. Và khi bạn chọn sai kiến trúc từ đầu, bạn không chỉ tốn tiền — bạn còn tốn thời gian, tăng độ phức tạp, và làm chậm cả team.
TL;DR:
- RAG không phải default cho mọi AI app
- Hãy đánh giá data, query pattern, accuracy, update frequency trước
- Nhiều bài toán chỉ cần prompt + search + orchestration
Bài này không phải để nói RAG dở. Thực tế, bài này để giúp bạn trả lời câu hỏi: “Liệu mình có thực sự cần RAG không, hay chỉ đang làm theo trend?” Câu hỏi quan trọng không phải là RAG có tốt không, mà là khi nào cần RAG trong kiến trúc AI app.
Tại sao RAG lại trở thành “default answer”
Lý do 1: Marketing từ vendor
Mở blog của Pinecone, Weaviate, hay Chroma ra là thấy toàn tutorial về RAG. Mở YouTube là thấy “Build RAG in 10 minutes.” Không phải họ sai — họ đang bán vector database, đương nhiên phải demo use case phù hợp. Tuy nhiên, khi mọi tutorial đều về RAG, developer dễ nghĩ rằng “đây là cách duy nhất.”
Lý do 2: Nỗi sợ hallucination
LLM trả lời sai là chuyện bình thường. Nhưng thay vì tối ưu prompt hoặc dùng structured output, nhiều team nghĩ ngay: “Phải có ground truth data → phải có vector DB → phải có RAG.” Trong khi đó, nhiều bài toán chỉ cần prompt rõ ràng hơn là đủ.
Lý do 3: Resume-driven development
Thẳng thắn mà nói, “build RAG pipeline với embedding + vector search” nghe cool hơn “viết prompt + gọi API.” Không ai muốn viết trong CV: “Tôi đã tối ưu 50 dòng prompt.” Thực tế, prompt tốt có thể thay thế cả một RAG pipeline — và save công ty $500/tháng. Chỉ là nó không sexy để khoe trên LinkedIn.
Lý do 4: Thiếu framework đánh giá
Hầu hết team không có checklist rõ ràng để quyết định kiến trúc AI. Họ chỉ nghe đâu RAG hay, thấy tutorial nhiều, rồi làm theo. Do đó, không ai dừng lại hỏi: “Liệu bài toán này có thực sự cần semantic search không?”
Ví dụ thực tế: một team build RAG cho internal FAQ của công ty. Họ dựng embedding pipeline, setup vector DB, viết retrieval logic… mất 3 tuần. Khi xong, họ mới nhận ra: FAQ chỉ có 20 câu hỏi. Nếu dùng search đơn giản + prompt, 2 ngày là xong.
Chi phí? Embedding API + vector DB hosting: $200/tháng. So với approach đơn giản: $30/tháng (chỉ tốn LLM calls). Gấp gần 7 lần, cho một bài toán không cần phức tạp đến vậy.
Câu chuyện thất bại thực tế
Một startup fintech quyết định build RAG cho hệ thống tư vấn tài chính. Họ có khoảng 500 tài liệu về sản phẩm đầu tư, nghĩ rằng RAG là lựa chọn đúng đắn.
Tuần 1-2: Setup infrastructure. Chọn embedding model, dựng Pinecone, viết chunking logic.
Tuần 3-4: Phát hiện chunking strategy không ổn. Documents về tài chính có nhiều bảng số liệu, chunk theo paragraph làm mất context. Kết quả là, họ phải viết lại logic chunk theo section.
Tuần 5-6: Retrieval accuracy thấp. Query “lãi suất gói A” trả về documents về gói B, C. Do đó, team phải tune lại top-k, thử reranking, điều chỉnh similarity threshold.
Tuần 7: Latency cao. Mỗi query mất 2-3 giây (embedding query + vector search + LLM). Khách hàng phàn nàn chậm.
Tuần 8: Tech lead ngồi lại review. Nhận ra: 80% câu hỏi của user là lookup queries đơn giản (“Lãi suất gói A?”, “Phí rút tiền?”). Chỉ 20% cần semantic search thực sự.
Quyết định: Rollback về Elasticsearch + prompt. Kết quả:
- Setup lại trong 3 ngày
- Latency giảm xuống 400ms
- Accuracy tăng (vì exact match tốt hơn cho lookup queries)
- Cost giảm từ $600/tháng xuống $150/tháng
Bài học: Họ đã tốn 8 tuần và gần $5000 để học được rằng bài toán của họ không cần RAG. Nếu có framework đánh giá từ đầu, họ đã tiết kiệm được 7 tuần.
Ba câu hỏi trước khi quyết định build RAG
Trước khi mở terminal gõ pip install langchain, hãy trả lời 3 câu hỏi này:
Câu hỏi 1: Dữ liệu của bạn thuộc loại nào?
Không phải mọi loại data đều cần embedding.
- Structured data (database records, API responses): Dùng SQL hoặc API call + prompt. Ví dụ: “Giá sản phẩm X là bao nhiêu?” → Query database, đưa kết quả vào prompt. Không cần vector search.
- Semi-structured (JSON, logs): Dùng search engine như Elasticsearch + prompt. Ví dụ: tìm log lỗi liên quan đến “payment timeout” → Elasticsearch query, format kết quả, đưa vào LLM.
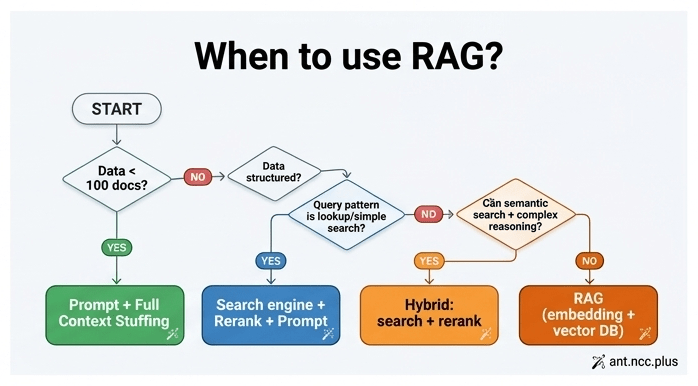
- Unstructured text (docs, PDFs): Đây mới là lúc cân nhắc RAG. Tuy nhiên, đừng vội — kiểm tra volume trước:
- < 100 documents: Có thể stuff toàn bộ vào context window. Claude 3.5 có 200K tokens, GPT-4 Turbo có 128K. Nếu tất cả docs của bạn fit vào đó, không cần RAG.
- 100-10K documents: Dùng search engine + rerank. Elasticsearch tìm top 20 results, LLM rerank lại, chọn top 5 đưa vào context.
- > 10K documents + query phức tạp: Lúc này RAG mới hợp lý.
Ví dụ: một startup có 50 trang internal wiki. Thay vì build RAG, họ convert toàn bộ wiki thành markdown, stuff vào context của Claude, xong. Chi phí: $0 infrastructure, chỉ tốn LLM calls.
Câu hỏi 2: Pattern truy vấn nào thực sự cần RAG?
Không phải mọi câu hỏi đều cần semantic search.
- Lookup queries (“Giá sản phẩm X?”, “Địa chỉ chi nhánh Y?”): Đây là exact match. Dùng search/API là đủ. Thực tế, RAG ở đây chỉ tăng latency không cần thiết.
- Aggregation queries (“So sánh 3 sản phẩm A, B, C”): Lấy structured data, đưa vào prompt, để LLM tổng hợp. Không cần embedding.
- Exploratory queries (“Tìm insight từ 1000 báo cáo khách hàng”, “Phân tích xu hướng từ research papers”): Đây mới là lúc RAG có giá trị. Bạn cần semantic search để tìm documents liên quan, rồi LLM reasoning trên đó.
Anti-pattern phổ biến: build RAG cho lookup queries. Một team e-commerce build RAG để trả lời “Sản phẩm X còn hàng không?” Kết quả: latency tăng từ 200ms lên 1.5s (vì phải embedding query + vector search), trong khi câu trả lời chỉ cần query database.
Câu hỏi 3: Yêu cầu về độ chính xác và tần suất update?
- Cần 100% chính xác (legal, medical, financial): RAG + citation, hoặc thậm chí deterministic system (rule-based). Không thể để LLM “đoán.”
- Cho phép sai 5-10% (recommendation, brainstorming, content generation): Prompt engineering đủ. Không cần phức tạp hóa.
- Data update hàng giờ/hàng ngày: Search API tốt hơn. Bạn không muốn phải re-embed toàn bộ corpus mỗi lần data thay đổi.
- Data update hàng tuần/hàng tháng: RAG hợp lý hơn. Embedding một lần, dùng lâu dài.
Ví dụ: một news aggregator cần trả lời câu hỏi về tin tức mới nhất. Nếu dùng RAG, mỗi lần có tin mới phải re-embed. Ngược lại, nếu dùng search API (như Algolia hoặc Elasticsearch), chỉ cần index mới là xong — nhanh hơn, rẻ hơn.
Decision framework: Khi nào dùng RAG, search hay prompt?
Đây là framework đơn giản để quyết định kiến trúc AI:
Ví dụ thực tế cho từng approach
- Prompt + context stuffing: Internal wiki < 50 pages. Convert sang markdown, stuff vào Claude 200K context. Xong.
- SQL + prompt: E-commerce product Q&A. User hỏi “Laptop nào dưới 20 triệu?”, query database, format kết quả, đưa vào prompt. LLM trả lời tự nhiên.
- Search + prompt: Customer support với 500 FAQ. Elasticsearch tìm top 10 câu hỏi liên quan, LLM chọn câu trả lời phù hợp nhất.
- RAG: Legal document analysis. 10,000+ hợp đồng, cần tìm điều khoản liên quan đến “liability” trong nhiều ngữ cảnh khác nhau. Semantic search + reasoning.
Khi nào dùng hybrid approach: Search + Rerank + Prompt
Có một middle ground mà nhiều team bỏ qua: search + rerank + prompt. Đây là lựa chọn tốt khi:
Khi nào dùng:
- Data volume trung bình (1K-10K documents)
- Query pattern vừa có exact match vừa có semantic search
- Cần balance giữa speed và accuracy
- Data update thường xuyên (không muốn re-embed)
Cách hoạt động:
- Elasticsearch tìm top 20 results dựa trên keyword matching
- LLM rerank 20 results này dựa trên semantic relevance với query
- Chọn top 5 results có score cao nhất
- Đưa 5 results này vào context của LLM để generate câu trả lời
Trade-off:
- Nhanh hơn RAG: Không cần embedding toàn bộ corpus, không cần maintain vector DB
- Chính xác hơn pure search: LLM rerank giúp hiểu semantic, không chỉ keyword matching
- Linh hoạt hơn: Dễ dàng update data mới mà không cần re-embed
Ví dụ thực tế:
Một platform customer support có 2000 FAQ. Một số câu hỏi cần exact match (“Giá gói Premium?”), một số cần semantic understanding (“Làm sao để nâng cấp tài khoản?”).
Approach:
# Step 1: Elasticsearch search
results = es.search(query, top_k=20)
# Step 2: LLM rerank
reranked = llm.rerank(query, results, top_k=5)
# Step 3: Generate answer
context = format_context(reranked)
answer = llm.generate(f"Context: {context}\nQuestion: {query}")Cost: $120/tháng (Elasticsearch + LLM calls)
Latency: 600ms average
Accuracy: 92% (so với 85% của pure search, 94% của RAG)
Trade-off đáng giá: Mất 2% accuracy so với RAG, nhưng tiết kiệm 60% cost và setup nhanh hơn 3 tuần.
RAG vs search + prompt: So sánh cost và độ phức tạp
Đây là con số thực tế (ước tính cho 10K queries/tháng):
| Approach | Setup time | Monthly cost | Maintenance effort |
|---|---|---|---|
| Prompt + API | 1-2 ngày | $50-100 | Thấp (chỉ tối ưu prompt) |
| Search + Prompt | 3-5 ngày | $100-200 | Trung bình (tune search query) |
| Hybrid (Search + Rerank) | 5-7 ngày | $150-250 | Trung bình (tune search + rerank) |
| RAG | 2-4 tuần | $300-800 | Cao (chunking, embedding, retrieval tuning) |
Để thấy rõ sự khác biệt, đây là code thực tế:
Approach 1: Prompt + API (đơn giản)
# Lấy data từ database
product = db.query(
"SELECT * FROM products WHERE id = ?",
product_id
)
# Đưa vào prompt
prompt = f"""
User hỏi: {user_query}
Thông tin sản phẩm: {json.dumps(product)}
Hãy trả lời câu hỏi của user dựa trên thông tin trên.
"""
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)Approach 2: RAG (phức tạp hơn nhiều)
# Embedding query
query_embedding = openai.embeddings.create(
model="text-embedding-3-small",
input=user_query
).data[0].embedding
# Vector search
results = pinecone_index.query(
vector=query_embedding,
top_k=10,
include_metadata=True
)
# Rerank results
reranked = cohere.rerank(
query=user_query,
documents=[r.metadata['text'] for r in results],
top_n=5
)
# Build context
context = "\n\n".join([doc.text for doc in reranked])
# Generate answer
prompt = f"""
Context: {context}
User hỏi: {user_query}
Trả lời dựa trên context trên.
"""
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)Nhìn vào code, bạn thấy rõ: RAG phức tạp gấp 3-4 lần. Và đây chỉ là code đơn giản hóa — chưa kể chunking strategy, error handling, monitoring, retry logic.
Trade-off cần nhớ:
Về mặt effort, RAG tốn nhiều hơn ở:
- Chunking strategy: Chia document thế nào? Overlap bao nhiêu?
- Embedding model: OpenAI? Cohere? Self-hosted?
- Vector DB tuning: Index type? Distance metric?
- Retrieval optimization: Top-k bao nhiêu? Rerank thế nào?
Trong khi đó, prompt + search tốn effort ở:
- Prompt engineering: Viết prompt rõ ràng, handle edge cases
- Search query optimization: Tune search parameters
Tuy nhiên, effort của approach thứ hai ít hơn nhiều.
Case study thực tế: một team chuyển từ RAG sang search + prompt cho bài toán customer support. Kết quả:
- Cost giảm từ $600/tháng xuống $180/tháng (giảm 70%)
- Response time giảm từ 2.5s xuống 0.8s (nhanh hơn 3x)
- Maintenance effort giảm từ 2 người xuống 0.5 người (developer chỉ cần check prompt thỉnh thoảng)
Lý do? Bài toán của họ chỉ cần exact match + một chút reasoning. RAG là overkill.
Tham khảo OpenAI embedding guide để hiểu rõ hơn về cách embedding hoạt động và khi nào nên dùng.
Khi nào RAG thực sự cần thiết
RAG phù hợp khi dữ liệu lớn, phi cấu trúc, cần semantic search, reasoning đa bước và phải truy vết nguồn trả lời.
Để cân bằng lại: RAG không phải xấu. Nó chỉ không phải default answer.
RAG là lựa chọn đúng khi:
- Volume lớn + semantic search phức tạp: 10K+ documents, query dạng “tìm tất cả nghiên cứu liên quan đến X nhưng không đề cập đến Y.” Exact match không đủ, cần semantic understanding.
- Domain-specific knowledge: Medical diagnosis support, legal contract analysis, technical documentation search. Cần trích xuất chính xác từ nguồn đáng tin cậy.
- Multi-hop reasoning: “Dựa trên báo cáo A, B, C, xu hướng chung là gì?” Điều này có nghĩa là bạn cần kết hợp thông tin từ nhiều documents khác nhau.
- Citation requirement: Phải truy vết được nguồn gốc thông tin. Với kiến trúc này, bạn có thể trả về chunk + metadata, user có thể verify.
Anti-pattern cần tránh:
- Build RAG vì “nghe đâu phải có vector DB”
- Build RAG cho data ít (< 100 docs), query đơn giản
- Build RAG khi chưa thử prompt engineering + search
RAG giống như một cái búa tốt. Tuy nhiên, nhiều team đang dùng nó để vặn vít — công cụ đúng, nhưng sai bài toán.
Xem thêm AWS guide về RAG để hiểu rõ hơn về kiến trúc này. Ngoài ra, bạn có thể so sánh các vector database phổ biến nếu quyết định đi theo hướng RAG.
Checklist trước khi build RAG
Trước khi quyết định kiến trúc AI, hãy chạy qua checklist này:
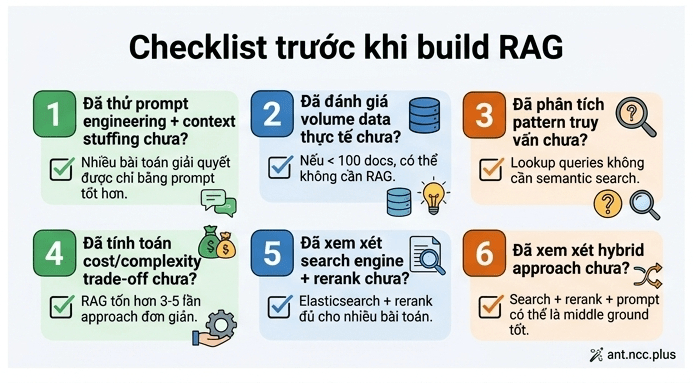
- [ ] Đã thử prompt engineering + context stuffing chưa? Nhiều bài toán giải quyết được chỉ bằng prompt tốt hơn.
- [ ] Đã đánh giá volume data thực tế chưa? Nếu < 100 docs, có thể không cần RAG.
- [ ] Đã phân tích pattern truy vấn chưa? Lookup queries không cần semantic search.
- [ ] Đã tính toán cost/complexity trade-off chưa? RAG tốn hơn 3-5 lần so với approach đơn giản.
- [ ] Đã xem xét search engine + rerank chưa? Elasticsearch + LLM rerank đủ cho nhiều bài toán.
- [ ] Đã xem xét hybrid approach chưa? Search + rerank + prompt có thể là middle ground tốt.
Call-to-action:
Nếu bạn đang build RAG, hãy dừng lại 1 ngày để review checklist này. Hỏi bản thân: “Liệu approach đơn giản hơn có giải quyết được không?”
Với team chưa bắt đầu, cách an toàn hơn là đi từ approach đơn giản nhất: Prompt + API. Khi approach đó không đủ, hãy thêm search. Sau đó, nếu bài toán vẫn cần semantic search phức tạp, lúc đó mới nghĩ đến hybrid hoặc RAG.
Nếu bài toán của bạn giải quyết được bằng 50 dòng code, đừng viết 5000 dòng chỉ vì nó nghe cool hơn. Kiến trúc tốt không phải kiến trúc có nhiều buzzword nhất — mà là kiến trúc ship nhanh nhất, maintain dễ nhất, và cost thấp nhất cho bài toán cụ thể của bạn.
Cuối cùng, đôi khi bài toán của bạn không cần vector database. Nó chỉ cần một cái prompt viết tốt.
FAQ
Khi nào không cần RAG?
Không cần RAG khi: (1) Data < 100 documents và fit vào context window, (2) Query pattern chủ yếu là lookup/exact match, (3) Data là structured/semi-structured (dùng SQL/API tốt hơn), (4) Data update thường xuyên (search API linh hoạt hơn), (5) Bạn chưa thử prompt engineering + search đơn giản.
Search + prompt khác gì RAG?
Search + prompt dùng keyword matching (Elasticsearch, Algolia) để tìm documents, rồi đưa vào LLM. Ngược lại, RAG dùng semantic search (embedding + vector DB) để tìm documents tương tự về nghĩa. Search nhanh hơn, rẻ hơn, nhưng kém chính xác với query phức tạp. Mặc dù vậy, RAG chính xác hơn với semantic queries, nhưng phức tạp và đắt hơn.
Data ít có nên dùng vector DB không?
Không. Nếu data < 100 documents, hãy stuff toàn bộ vào context window của LLM (Claude 200K, GPT-4 128K). Nếu 100-1000 documents, dùng search engine + rerank. Vector DB chỉ hợp lý khi > 10K documents và cần semantic search thực sự.
RAG có luôn chính xác hơn không?
Không. RAG chính xác hơn với exploratory queries và semantic search. Tuy nhiên, với lookup queries (exact match), search engine thường chính xác hơn. Hơn nữa, RAG cũng có thể trả về irrelevant chunks nếu chunking strategy không tốt. Độ chính xác phụ thuộc vào bài toán, không phải kiến trúc.