Khi “Prompt Thông Minh” Trở Thành Điểm Yếu Chết Người
Tôi còn nhớ rõ câu chuyện của một ngân hàng. Họ rất hào hứng với việc triển khai chatbot AI để tự động phê duyệt các hạn mức tín dụng nhỏ dưới 50 triệu. Cả team dành hàng tháng trời để tối ưu prompt, thử nghiệm các model khác nhau, và cuối cùng đạt được độ chính xác ấn tượng trên tập test – khoảng 97%. Hệ thống chạy ngon lành được vài tuần, cho đến khi có một khách hàng VIP khiếu nại vì bị từ chối mà không rõ lý do.
Lúc đó mới lòi ra vấn đề: không ai có thể giải thích được tại sao hệ thống đưa ra quyết định đó. Không có log đầy đủ về các yếu tố đầu vào, không có confidence score, không có cơ chế cho nhân viên can thiệp kịp thời. Kết quả? Không chỉ vi phạm nghiêm trọng quy định về giải thích quyết định tín dụng, mà còn gây tổn thất uy tín khủng khiếp. Hệ thống phải gỡ bỏ khẩn cấp, và dự án thất bại thảm hại.
Nhưng đó không phải là câu chuyện duy nhất. Một người phụ trách hệ thống AI phân loại đơn khiếu nại cho một ngân hàng lớn. Khi có khách hàng khiếu nại lên cơ quan quản lý, cả team không thể tìm ra lý do tại sao đơn bị phân loại sai. Không có audit trail, không có log. Anh ấy phải thức trắng 3 đêm để lần mò lại từng dòng code, và cuối cùng cũng không tìm ra nguyên nhân. Bài học đắt giá: khi bạn không thể giải thích được quyết định của AI, bạn đang đặt cả sự nghiệp của mình vào rủi ro.
Câu chuyện này khiến tôi suy nghĩ nhiều: Chúng ta đang đầu tư vào việc khiến AI “thông minh” hơn, hay vào việc khiến hệ thống “đáng tin cậy” hơn? Trong các lĩnh vực nhạy cảm như tài chính, y tế, hay chính phủ, tôi nhận ra một điều: độ tin cậy – được xây dựng từ khả năng audit, giải thích và kiểm soát – mới là thứ tạo ra giá trị lâu dài, không phải độ thông minh thuần túy.
Takeaway đầu tiên: Ưu tiên thiết kế cho sự minh bạch và kiểm soát ngay từ đầu, trước khi bạn nghĩ đến việc tối ưu hiệu suất hay độ chính xác. Trust me, bạn sẽ không muốn học bài học này bằng cách trải nghiệm thất bại như team ngân hàng kia đâu.
Vẽ Bản Đồ Triển Khai AI: Đâu Là Đất Lành, Đâu Là Vùng Cấm?
Sau nhiều năm làm việc với các hệ thống nghiệp vụ nhạy cảm, tôi rút ra một nguyên tắc đơn giản: ranh giới an toàn không nằm ở công nghệ AI bạn dùng, mà nằm ở mức độ rủi ro và trách nhiệm pháp lý của quyết định mà hệ thống đưa ra. Hãy cùng tôi vẽ bản đồ này ra, bạn sẽ thấy rõ đâu là nơi AI tỏa sáng, và đâu là nơi nó nên đứng lại.
Vùng Xanh – AI Làm Tốt Hơn, Con Người Ra Lệnh Cuối Cùng
Đây là những khu vực mà AI thực sự phát huy sức mạnh, nhưng luôn nhớ: con người vẫn là người ra quyết định cuối cùng.
- Search & Discovery: AI giỏi việc lục lọi trong kho tài liệu khổng lồ. Ví dụ, trong một công ty luật, AI có thể tìm nhanh các điều khoản pháp lý liên quan đến một vụ kiện cụ thể từ hàng nghìn văn bản. Luật sư vẫn phải đọc và quyết định xem có áp dụng không. Tôi thấy Elasticsearch với AI-powered search làm việc này khá hiệu quả.
- Summarization & Synthesis: AI tóm tắt báo cáo 100 trang thành 1 trang cho bác sĩ đánh giá nhanh? Tuyệt vời! Nhưng bác sĩ vẫn phải đọc bản tóm tắt đó và tự đưa ra chẩn đoán của mình. Đây là use-case mà các model như GPT-4 hay Claude tỏ ra cực kỳ hữu ích.
- Anomaly & Pattern Detection: Hệ thống ngân hàng dùng AI để gắn cờ các giao dịch chuyển khoản khả nghi. Tuy nhiên, nhân viên tuân thủ mới là người quyết định có báo cáo hay không. Các giải pháp AML (Anti-Money Laundering) hiện đại đều theo mô hình này.
- Assistant & Information Retrieval: AI đề xuất các bước xử lý theo quy trình cho nhân viên tổng đài khi khách hàng gọi đến. Nhân viên vẫn chọn làm theo hay không.
Lý do những khu vực này an toàn? Đơn giản thôi: con người giữ toàn quyền kiểm soát và chịu trách nhiệm cuối cùng dựa trên đầu ra có thể kiểm chứng của AI. AI chỉ là công cụ hỗ trợ ra quyết định, không phải người ra quyết định.
Vùng Đỏ – AI Không Được Quyết Định, Chỉ Được Hỗ Trợ
Đây là những vùng đất nguy hiểm. Đưa AI vào đây mà thiếu kiểm soát thì giống như giao xe tải cho một đứa trẻ lái vậy.
- Approval & Authorization: Phê duyệt tín dụng, cấp phép xây dựng, duyệt chi ngân sách lớn. Tại sao nguy hiểm? Vì thiếu accountability – khi xảy ra sai sót, bạn không thể đổ lỗi cho AI được. Luật pháp không công nhận AI là pháp nhân có trách nhiệm.
- Enforcement & Sanction: Áp dụng chế tài, khóa tài khoản người dùng, phạt vi phạm hành chính. Nguy hiểm ở chỗ thiếu human judgment – AI không hiểu được hoàn cảnh đặc biệt, tình tiết giảm nhẹ, hay yếu tố nhân văn.
- Diagnosis & Critical Decision: Chẩn đoán bệnh, kết luận điều tra hình sự, phân loại mức độ rủi ro an ninh quốc gia. Ở đây, explainability là vấn đề sống còn. Bác sĩ không thể nói với bệnh nhân: “Máy tính bảo bạn bị ung thư, tôi không biết tại sao.”
Bài học từ IBM Watson Health là minh chứng rõ ràng cho việc này.
Takeaway quan trọng: Hãy lập bản đồ use-case của bạn ngay bây giờ. Nếu nó rơi vào Vùng Đỏ, thiết kế hệ thống bắt buộc phải có human-in-the-loop như một bước nghiệp vụ chính thức, không phải tùy chọn hay “nice-to-have”.
4 Nguyên Tắc Thiết Kế Cho Hệ Thống AI Đáng Tin Cậy
Okay, vậy chúng ta đã biết đâu là vùng an toàn và vùng nguy hiểm. Giờ đến phần thú vị: làm thế nào để thiết kế một hệ thống AI mà bạn thực sự dám triển khai trong môi trường nhạy cảm? Theo quan điểm của tôi, có 4 nguyên tắc thiết kế – thiếu một trong số này, hệ thống của bạn sẽ lung lay.
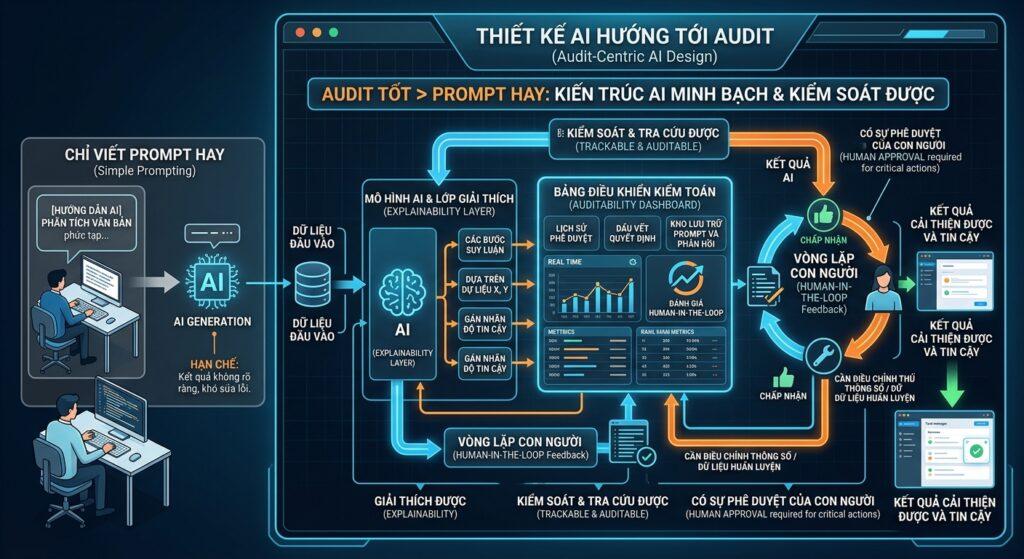
1. Auditability (Tính Kiểm Toán) – Mọi Thứ Phải Được Ghi Lại
Nguyên tắc đầu tiên và quan trọng nhất: nếu không ghi lại được, bạn sẽ không thể giải thích khi có sự cố.
Trong hệ thống của tôi, mọi interaction với AI đều phải được log đầy đủ: – Prompt/input nguyên bản (kể cả metadata) – Model version và parameters – Raw output từ model – Confidence score hoặc các metrics liên quan – Timestamp chính xác đến mili giây – User ID của người tương tác – Session ID duy nhất cho mỗi “cuộc trò chuyện”
Tại sao cần thiết? Khi có sự cố (và chắc chắn sẽ có), bạn cần truy vết được chính xác điều gì đã xảy ra. Không có audit trail, bạn sẽ mất hàng giờ, thậm chí ngày để lần mò lại, và có thể không bao giờ tìm ra câu trả lời thuyết phục khi khách hàng hoặc cơ quan chức năng hỏi “Tại sao lại quyết định như vậy?”. Hơn nữa, các quy định như GDPR Article 22 hay HIPAA đều yêu cầu khả năng giải thích quyết định tự động hóa.
Triển khai thực tế thế nào? Tôi thường dùng structured logging (JSON format) và đẩy về hệ thống trung tâm như Elasticsearch hoặc DataDog. Mỗi log entry đều có trace ID để bạn có thể reconstruct toàn bộ flow xử lý. OpenTelemetry là công cụ tuyệt vời cho việc này.
2. Explainability (Tính Giải Thích) – Không Chấp Nhận Hộp Đen
Hộp đen (black-box) chỉ tốt cho máy bay, không tốt cho hệ thống phần mềm nghiệp vụ. Nguyên tắc thứ hai: hệ thống phải có khả năng giải thích tại sao nó đưa ra kết quả đó.
Điều này không có nghĩa bạn phải hiểu toàn bộ neural network. Nhưng ít nhất, bạn cần: – Với model phân loại: biết được feature ảnh hưởng nhất đến quyết định (dùng SHAP hoặc LIME) – Với RAG system: biết được đoạn văn bản nguồn được dùng để trả lời – Với recommendation system: biết được lịch sử tương tác nào ảnh hưởng đến đề xuất
Ví dụ thực tế: Trong hệ thống phân loại đơn khiếu nại, mỗi đề xuất phân loại đều kèm theo: “Dựa vào các từ khóa ‘phí giao dịch’, ‘thẻ tín dụng’, ‘không thông báo’ trong nội dung đơn, hệ thống đề xuất phân loại vào nhóm ‘Khiếu nại phí dịch vụ’ với độ tin cậy 87%”.
Lợi ích kép: Không chỉ giúp nhân viên tin tưởng vào đề xuất của AI hơn, mà còn tạo cơ hội để họ học hỏi và cải thiện quy trình thủ công. Interpretable Machine Learning là cuốn sách tôi recommend cho mọi người.
3. Human-in-the-Loop (Con Người Trong Vòng Lặp) – Thiết Kế Sẵn, Không Phải Vá Sau
Đây là nguyên tắc mà nhiều team bỏ qua hoặc làm nửa vời. Human-in-the-loop không phải là “có nhân viên ngồi đó theo dõi”, mà là thiết kế con người như một bước xử lý bắt buộc trong luồng nghiệp vụ.
Workflow chuẩn nên trông như thế này:
[Input từ khách hàng]
→ [AI Process & Recommend]
→ [Human Review & Approve/Reject/Modify]
→ [Final Action & Feedback loop]Điểm then chốt: bước human review không phải là bottleneck, mà là quality gate. Nó được thiết kế để:
– Xử lý các trường hợp confidence score thấp (dưới ngưỡng bạn định nghĩa)
– Bổ sung ngữ cảnh nghiệp vụ mà AI không biết
– Xử lý ngoại lệ và edge cases
– Là lớp phòng thủ cuối cùng trước khi quyết định được thực thiVí dụ trong thực tế: Một ngân hàng triển khai hệ thống AI đề xuất hạn mức tín dụng. Thay vì auto-approve, hệ thống gửi đề xuất cho nhân viên quan hệ khách hàng. Nhân viên này có thể điều chỉnh dựa trên hiểu biết về khách hàng (ví dụ: biết khách hàng sắp nhận thừa kế lớn). Quyết định cuối cùng vẫn là của con người, AI chỉ giúp họ ra quyết định nhanh hơn và nhất quán hơn.
4. Privacy & Data Governance (Quyền Riêng Tư & Quản Trị Dữ Liệu) – Bằng Design
Nguyên tắc cuối cùng nhưng không kém phần quan trọng: bảo mật và quyền riêng tư phải được tích hợp ngay từ thiết kế, không phải thêm vào sau.Trong môi trường nhạy cảm, bạn không thể dùng public API của OpenAI hay Google cho dữ liệu bệnh án hay thông tin tài chính được. Cần:
– Xử lý dữ liệu tại chỗ (on-premise hoặc private cloud)
– Mã hóa dữ liệu ở cả trạng thái nghỉ (at-rest) và truyền tải (in-transit)
– Có policy rõ ràng về vòng đời dữ liệu (data lifecycle)
– Tuân thủ các quy định như Luật An Ninh Mạng hay Thông tư 20/2017/TT-BYT
Triển khai thực tế: Dùng private LLM như Llama 2, Vicuna hoặc các model mã nguồn mở khác, deploy trên hạ tầng riêng. Kết hợp với Vault của HashiCorp để quản lý secret và Open Policy Agent để kiểm soát truy cập.
4 Câu Hỏi Kiểm Tra Nhanh Trước Khi Triển Khai:
Trước khi bạn triển khai bất kỳ hệ thống AI nào cho nghiệp vụ nhạy cảm, hãy tự hỏi:
1. Bạn có log được đầy đủ prompt, output, metadata và ai đã dùng không? → Nếu không, bạn không thể giải thích khi có sự cố.
2. Bạn có giải thích được tại sao AI đưa ra kết quả này cho một nhân viên cấp dưới trong 1 phút không? → Nếu không, bạn đang dùng hộp đen.
3. Nếu AI sai, có con người nào trong luồng nghiệp vụ chặn được lỗi đó trước khi gây hại không? → Nếu không, bạn đang đặt khách hàng vào rủi ro.
4. Dữ liệu nhạy cảm nhất của bạn có bao giờ ra khỏi hệ thống nội bộ không? → Nếu có, bạn đang vi phạm quy định bảo mật.
Nếu có bất kỳ câu trả lời “Không” nào, dừng lại. Đừng triển khai cho đến khi bạn giải quyết được những lỗ hổng đó.
Bài Toán Thực Tế: AI Phân Loại Đơn Khiếu Nại Tài Chính
Để minh họa rõ hơn sự khác biệt giữa “tối ưu prompt” và “ưu tiên audit”, hãy cùng tôi xem xét một bài toán thực tế mà hầu như ngân hàng nào cũng gặp: tự động hóa việc phân loại đơn khiếu nại từ khách hàng.
Scenario: Ngân hàng nhận hàng nghìn đơn khiếu nại mỗi ngày: khiếu nại phí dịch vụ, lỗi giao dịch, thẻ tín dụng bị tính sai lãi… Mục tiêu là phân loại chúng để định tuyến đến đúng bộ phận xử lý, giảm thời gian xử lý từ vài ngày xuống vài giờ.
Cách Tiếp Cận A: Tối Ưu “Prompt Hay” Để Đạt Độ Chính Xác Cao
Đây là cách mà nhiều team đam mê công nghệ thường làm:
– Tập trung toàn lực vào việc tinh chỉnh prompt: thử hàng chục template khác nhau
– Thử nghiệm các model lớn hơn, đắt hơn (GPT-5.4 → GPT-5.5 → Claude Opus 4.7)
– Mục tiêu duy nhất: đạt accuracy >95% trên tập test
– Kết quả sau 3 tháng: Model chạy tốt trên dữ liệu test với accuracy 96.5%
Nghe có vẻ ấn tượng, nhưng đây là những điểm yếu chết người mà họ không nhìn thấy:
1. Không có audit trail: Khi model phân loại sai (3.5% trường hợp), không ai biết nguyên nhân từ đâu. Lỗi do prompt không rõ ràng? Do training data bias? Do model hallucination? Không có log, không có câu trả lời.
2. Black-box decision: Nhân viên nhận được đơn đã bị phân loại sai, nhưng không hiểu tại sao nó bị phân loại như vậy. Họ không thể điều chỉnh hay sửa chữa – hệ thống là hộp đen.
3. Không có human review: Đơn bị phân loại sai đi thẳng đến bộ phận sai. Ví dụ: đơn khiếu nại phí giao dịch bị gửi nhầm sang bộ phận thẻ tín dụng. Kết quả: khách hàng phải chờ thêm vài ngày, thậm chí vài tuần, gây bức xúc và mất niềm tin.
Hệ quả thực tế: Sau 2 tháng triển khai, tỷ lệ khiếu nại của khách hàng về việc xử lý chậm *tăng* 15%. Đội ngũ CSKH phải làm việc cật lực để xin lỗi và khắc phục. Cuối cùng, hệ thống bị gỡ bỏ.
Cách Tiếp Cận B: Ưu Tiên “Audit Tốt” và Kiểm Soát
Cách tiếp cận mà tôi khuyên các bạn nên áp dụng – có phần “chậm” hơn ban đầu, nhưng bền vững hơn về lâu dài:
1. Prompt đơn giản, rõ ràng: Thay vì tối ưu phức tạp, chúng tôi dùng prompt đơn giản: “Phân loại đơn khiếu nại này vào một trong các nhóm sau: [danh sách nhóm]. Trả về tên nhóm và confidence score.”
2. Logging đầy đủ ngay từ đầu: Mọi đơn, mọi prompt, mọi output đều được ghi lại đầy đủ vào hệ thống trung tâm. Mỗi đơn có unique ID để trace.
3. Workflow với human-in-the-loop được thiết kế sẵn: AI chỉ đề xuất phân loại. Một nhóm nhân viên (có thể là thực tập sinh hoặc nhân viên mới) xác nhận hoặc sửa lại đề xuất đó trước khi định tuyến. Quan trọng: đơn có confidence score dưới 80% được đưa lên đầu danh sách review.
4. Dashboard giám sát real-time: Manager có thể xem ngay: tỷ lệ đề xuất đúng/sai của AI theo thời gian, các nhóm bị sai nhiều nhất, các từ khóa thường gây nhầm lẫn.
Kết quả ban đầu có thể khiến bạn thất vọng: Độ chính xác chỉ khoảng 85-90%, thấp hơn cách tiếp cận A. Nhưng hãy nhìn vào những gì chúng tôi có:
1. Mọi lỗi đều có thể truy vết và học hỏi: Khi model sai, chúng tôi biết chính xác nó sai ở đâu, tại sao, và có thể điều chỉnh prompt hoặc training data cho lần sau.
2. Khách hàng không bao giờ nhận dịch vụ sai do lỗi AI: Vì có con người kiểm tra lại trước khi định tuyến. Chất lượng dịch vụ được đảm bảo 100%.
3. Hệ thống có thể cải tiến liên tục: Dựa vào dữ liệu audit, sau 3 tháng, độ chính xác của AI tăng từ 85% lên 94% – và quan trọng hơn, độ chính xác sau khi human review là 100%.
4. Chi phí vận hành thấp hơn: Nhân viên review chỉ mất 10-15% thời gian so với việc phân loại thủ công hoàn toàn, nhưng chất lượng đồng đều hơn nhiều.
Bài học rút ra: Trong ngắn hạn, cách tiếp cận A có vẻ “thông minh” hơn. Nhưng trong dài hạn, cách tiếp cận B tạo ra một hệ thống bền vững, có thể quản lý được, và liên tục cải thiện – đây mới là mục tiêu thực sự trong môi trường nghiệp vụ nhạy cảm.
Từ Nhận Thức Sang Hành Động: Chiến Lược Rollout Dựa Trên Rủi Ro
Sau tất cả những phân tích và ví dụ trên, tôi muốn bạn ghi nhớ một thông điệp then chốt: Đừng đặt câu hỏi “Làm sao để AI của chúng ta thông minh hơn?”. Hãy đặt câu hỏi “Làm sao để hệ thống của chúng ta đủ minh bạch và kiểm soát được để chúng ta dám triển khai AI?”
Sự thành công trong lĩnh vực nhạy cảm được xây bằng audit trail, không phải bằng những prompt tinh vi. Và để biến nhận thức này thành hành động cụ thể, tôi đề xuất một lộ trình 4 bước mà tôi gọi là Risk-Based Rollout Strategy:
Bước 1: Bắt Đầu Ở Vùng An Toàn (Pilot)
Đừng nhảy ngay vào use-case phức tạp nhất. Hãy chọn một use-case thuộc Vùng Xanh rõ ràng, ít rủi ro, như:
– Công cụ tìm kiếm nội bộ tài liệu quy trình
– Hệ thống tóm tắt báo cáo cuộc họp
– Tool extract thông tin từ form nhập liệu
Mục tiêu của bước này: Làm quen với công nghệ AI và – quan trọng hơn – xây dựng nền tảng logging/audit cho toàn bộ hệ thống sau này. Đây là bước bạn được phép sai, vì hậu quả thấp.
Bước 2: Củng Cố Nền Tảng Kiểm Soát
Trước khi mở rộng sang các use-case quan trọng hơn, hãy đảm bảo bạn đã có:
– Hệ thống log tập trung với đầy đủ metadata
– Cơ chế giải thích đầu ra cơ bản (như confidence score, source citation)
– Một quy trình xử lý rõ ràng khi AI đưa ra kết quả sai hoặc không chắc chắn
– Dashboard giám sát cơ bản cho team quản lý
Nếu thiếu một trong những thứ này, đừng tiến sang bước 3. Trust me, bạn sẽ hối hận nếu bỏ qua bước củng cố nền tảng.
Bước 3: Mở Rộng Với Human-in-the-Loop
Khi nền tảng đã vững, bạn có thể đưa AI vào các bước nghiệp vụ quan trọng hơn, như:
– Đề xuất phân loại đơn từ (như ví dụ trên)
– Gắn cờ giao dịch bất thường
– Đề xuất hướng xử lý theo quy trình
Điều kiện tiên quyết: Đã thiết kế sẵn một bước xác nhận của con người trong luồng công việc. Không có điều này, không triển khai.
Bước 4: Liên Tục Đánh Giá và Điều Chỉnh
AI không phải là sản phẩm “set and forget”. Hãy coi nó như một “nhân viên mới” cần được đào tạo và giám sát liên tục:
– Sử dụng dashboard giám sát hàng tuần để phát hiện vấn đề
– Dựa vào dữ liệu audit để cải thiện prompt, model và quy trình
– Điều chỉnh ngưỡng confidence score dựa trên thực tế vận hành
– Cập nhật training data định kỳ để tránh bias
Lời kêu gọi hành động cuối cùng: Hãy chia sẻ bài viết này với team kỹ thuật và sản phẩm của bạn. Nhưng đừng dừng lại ở việc chia sẻ. Hãy bắt đầu cuộc thảo luận không phải bằng “Chúng ta sẽ dùng model nào?” hay “Làm sao để prompt hiệu quả?”, mà bằng “Chúng ta sẽ thiết kế hệ thống thế nào để luôn kiểm soát được AI, bất kể nó thông minh đến đâu?”
Bởi vì trong thế giới nghiệp vụ nhạy cảm, một hệ thống đáng tin cậy 80% còn giá trị hơn một hệ thống thông minh 95% nhưng không thể kiểm soát. Và đó mới là thứ khách hàng, đối tác, và quan trọng nhất là luật pháp thực sự cần từ bạn.