Có lần tôi ngồi họp với phòng đào tạo một trường đại học, họ khoe mới mua được license ChatGPT Enterprise và đang muốn dùng để hỗ trợ sinh viên. Thế rồi một câu hỏi đơn giản: “Học phí kỳ này của tôi là bao nhiêu?” – ChatGPT trả lời đại khái dựa trên dữ liệu công khai, trong khi thực tế mỗi sinh viên có mức học phí khác nhau tùy vào chương trình, học bổng. Họ nhận ra: LLM phổ thông biết rất nhiều thứ chung chung, nhưng không biết gì về “nội bộ” của trường mình.
Đó là lúc RAG (Retrieval-Augmented Generation) trở nên có giá trị thực sự. Thay vì để LLM tự “đoán”, RAG chèn thêm một lớp truy xuất thông tin ở giữa – câu hỏi của sinh viên được tìm kiếm trong kho tài liệu nội bộ của trường trước, rồi mới đẩy kết quả đó cho LLM tổng hợp câu trả lời. Không chỉ chính xác hơn, RAG còn trả lời kèm nguồn trích dẫn – biết câu trả lời lấy từ quy chế trang mấy, điều cực kỳ quan trọng trong môi trường học thuật.
Bài này tôi sẽ dẫn bạn qua 5 bước để xây hệ thống RAG cho trường đại học, từ đánh giá ban đầu đến vận hành production – dựa trên case study tham khảo từ Đại học Bang Georgia, Mississippi State và nhiều trường khác.
RAG hoạt động như thế nào?
Khi sinh viên đặt câu hỏi, hệ thống RAG không để LLM tự trả lời từ dữ liệu huấn luyện cũ. Thay vào đó, nó tìm kiếm các đoạn văn bản liên quan nhất từ kho tài liệu nội bộ (quy chế, thông báo, hồ sơ), rồi đẩy các đoạn đó vào context của LLM để tổng hợp câu trả lời có nguồn gốc rõ ràng. Kết quả: ít hallucination hơn, có thể truy xuất nguồn, và phù hợp với dữ liệu thực tế của từng trường.
Bước 1: Đánh giá sẵn sàng – Đừng vội code, hãy vạch bản đồ trước
Tôi thấy nhiều team nhảy ngay vào code, ba tháng sau mới phát hiện dữ liệu chưa số hóa, hoặc không có nhân sự vận hành. Bước đánh giá này tuy khô khan nhưng quyết định 50% thành công. Hãy kiểm tra 4 mảng:
Dữ liệu
Câu hỏi đầu tiên không phải là “dùng framework nào” mà là “dữ liệu của tôi trông như thế nào?”
Tôi từng gặp một trường có đến 80% quy chế đào tạo vẫn là file PDF scan từ những năm 2000 – chất lượng thấp, không có text layer, một số bị nghiêng. Lẫn trong đó là các file Word có encoding khác nhau (UTF-8 lẫn ANSI), vài bảng biểu Excel không có header rõ ràng, và một số thông báo dạng ảnh chụp màn hình. Đây là “dữ liệu hỗn tạp” theo nghĩa thực sự – và hệ thống RAG sẽ thất bại nếu bạn không xử lý chúng trước.
Công cụ tốt để giải quyết: MinerU hỗ trợ OCR đa ngôn ngữ (109 ngôn ngữ), tự động nhận dạng bảng và chuyển sang HTML, công thức toán sang LaTeX. Dữ liệu đầu vào tốt là điều kiện cần – không có cách nào vá bằng thuật toán.
Nhân sự
Cần ít nhất 1 người biết Python ở mức thực chiến – tức là có thể đọc doc, gọi API REST, viết script xử lý file, debug lỗi thư viện. Không cần biết PyTorch hay train model, nhưng phải quen với requests, FastAPI ở mức cơ bản, và làm việc được trên môi trường Linux/terminal. Cộng thêm 1 người am hiểu nghiệp vụ (phòng đào tạo, thư viện) để xác định use-case và đánh giá chất lượng kết quả.
Hạ tầng & Ngân sách
Tôi phân tích kỹ ở Bước 2, nhưng sơ bộ: nếu ngân sách dưới $10k/năm, hãy nghiêng về Local LLM. Nếu cần triển khai nhanh trong 1-2 tháng và có budget, Cloud là điểm khởi đầu hợp lý.
Pháp lý & Bảo mật
Ở Việt Nam, dữ liệu sinh viên (điểm số, học phí, hồ sơ cá nhân) được bảo vệ theo các quy định nội bộ và ngày càng được siết chặt. Ở Mỹ có FERPA, ở châu Âu có GDPR – đều quy định rõ: dữ liệu nhạy cảm của sinh viên A không được để lộ sang sinh viên B, kể cả gián tiếp. Bảo mật phải được thiết kế từ đầu, không phải “gắn thêm sau”.
Mini case study – Bước 1: Trường Đại học A (15.000 sinh viên, ngân sách IT hạn chế) bắt đầu bằng cách audit toàn bộ kho tài liệu. Kết quả: 60% là PDF có thể đọc được, 30% là PDF scan cần OCR, 10% là file Word định dạng lộn xộn. Họ quyết định pilot với 60% dữ liệu sạch trước – thay vì cố xử lý hết – để ra sản phẩm nhanh, thu feedback, rồi mới mở rộng dần.
Đầu ra bước 1: Báo cáo readiness (chất lượng dữ liệu, nhân sự, hạ tầng, rủi ro pháp lý) + chọn 1 use-case pilot cụ thể (ví dụ: chatbot trả lời về quy chế đào tạo cho sinh viên khoa CNTT).
Bước 2: Nên dùng Cloud hay Local LLM? Và tại sao câu trả lời thường là cả hai
Nhiều người nói với tôi: “Dùng cloud cho nhanh, đắt một chút cũng được.” Tôi không phản đối cái logic đó – nhưng “một chút” đó đôi khi là con số khiến dự án chết yểu sau 1 năm.
Cloud vs Local LLM – So sánh chi phí thực tế
| Hạng mục (quy mô 1 triệu request/tháng) | Cloud LLM (GPT-4, Claude) | Local LLM (Llama 3, Mistral) |
|---|---|---|
| Chi phí suy luận (token) | $3.000 – $15.000/tháng | $0 |
| Data transfer | $500 – $2.000/tháng | $0 (mạng nội bộ) |
| Phần cứng (GPU server) | $0 | $3.000 – $8.000 (một lần) |
| Ước tính TCO năm đầu | $54.000 – $264.000 | $8.000 – $18.000 |
| Bảo mật dữ liệu | Dữ liệu gửi ra ngoài | Dữ liệu ở trong trường |
Một sinh viên xây chatbot RAG bằng LangChain + GPT-4 từng chia sẻ: chi phí tăng từ $20/tháng lên $300/tháng khi chỉ có 50 người dùng. Ở quy mô trường đại học với hàng ngàn sinh viên, con số đó nhân lên rất nhanh.
Có người phản bác: “Nhưng Local LLM chất lượng tệ hơn, không đáng đổi.” Điều này từng đúng. Nhưng Llama 3 hay Qwen thế hệ mới đã thu hẹp khoảng cách rất nhiều với GPT-3.5. Với các tác vụ tra cứu quy chế, hỏi đáp hành chính thông thường – chiếm 80-90% workload thực tế – Local LLM đủ dùng.
Kiến trúc hybrid – lựa chọn thực dụng nhất: Dùng Local LLM (Llama 3.1 8B + Ollama) cho phần lớn câu hỏi thông thường. Chỉ escalate lên Cloud API khi gặp câu hỏi đa ngôn ngữ phức tạp, phân tích sâu, hoặc khi traffic tăng đột biến mùa tuyển sinh.
Chọn Vector Database
Nếu trường đã có PostgreSQL, dùng pgvector – đơn giản nhất, không cần hạ tầng mới. Cần standalone thì Chroma (nhẹ, phù hợp pilot) hoặc Qdrant (tốt hơn khi scale). Milvus mạnh nhưng phức tạp hơn để vận hành.
Chọn Framework
| Framework | Điểm mạnh | Phù hợp khi nào |
|---|---|---|
| LangChain (~125k ⭐) | Agent phức tạp, kết nối nhiều tool | Trợ lý ảo có thể gọi API điểm danh, gửi email tự động |
| LlamaIndex (~41k ⭐) | Lập chỉ mục sâu, API đơn giản | Cổng tra cứu thư viện, hỏi đáp quy chế – đây là điểm khởi đầu tôi hay khuyên |
| Haystack (~20k ⭐) | Pipeline có thể kiểm toán, production-grade | Hệ thống xử lý hồ sơ y tế, pháp chế, yêu cầu audit trail |
Mini case study – Bước 2: Trường Đại học B (20.000 sinh viên, team IT 5 người) ban đầu dùng GPT-4 API, chi phí leo thang lên $4.500/tháng sau 3 tháng. Họ chuyển sang hybrid: Llama 3.1 8B chạy trên 2 server GPU thuê lại ($600/tháng) xử lý 85% request, chỉ gọi Claude API cho 15% câu hỏi phức tạp. Chi phí ổn định ở $900/tháng – tiết kiệm 80% so với trước.
Đầu ra bước 2: Sơ đồ kiến trúc + danh sách tech stack (LLM, vector DB, framework, embedding model).
Bước 3: Làm thế nào để xây data pipeline đúng cách? (Đây là nơi hầu hết dự án thất bại thầm lặng)
Embedding model và LLM đều có giới hạn context window, nên phải “cắt” (chunk) tài liệu thành các mảnh nhỏ. Cách bạn cắt ảnh hưởng trực tiếp đến độ chính xác của toàn bộ hệ thống – và đây là bước nhiều team xem nhẹ nhất.
Các chiến lược chunking
| Chiến lược | Nguyên lý | Độ chính xác | Dùng khi nào |
|---|---|---|---|
| Fixed-size | Cắt theo số token cố định (vd: 500) | ~50% | Tài liệu ngắn, hành chính đơn giản |
| Recursive | Cắt theo cấu trúc câu/đoạn văn | Trung bình | Cẩm nang sinh viên, quy chế |
| Semantic | Cắt tại điểm thay đổi ngữ nghĩa | Tốt | Diễn đàn, nội dung người dùng tạo |
| Adaptive | Kết hợp nhiều phương pháp tùy ngữ cảnh | ~87% | Luận văn, tài liệu khoa học chuyên sâu |
Nghiên cứu từ môi trường y khoa cho thấy adaptive chunking đạt precision 0.50, recall 0.88, F1 0.64 – cao hơn hẳn fixed-size (0.17 / 0.40 / 0.24) (nguồn: PMC, Comparative Evaluation of Advanced Chunking for RAG in LLMs for Clinical Decision Support). Tưởng tượng bạn cắt ngang một điều khoản quan trọng trong quy chế – hệ thống sẽ không tìm ra nó dù sinh viên hỏi đúng từ khóa.
Lời khuyên thực tế: Bắt đầu với recursive chunking cho tài liệu hành chính (quy chế, thông báo). Chuyển sang semantic hoặc adaptive khi xử lý luận văn, bài báo khoa học có công thức và bảng số liệu.
Metadata là chìa khóa bảo mật
Mỗi chunk sau khi tạo cần được gắn metadata: khoa, loai_tai_lieu, nam_hoc, muc_truy_cap (public / sinh_vien / giang_vien / admin). Metadata này không chỉ giúp filtering trong retrieval – nó là cơ chế bảo mật đầu tiên ngăn dữ liệu của người này xuất hiện trong kết quả của người khác.
Mini case study – Bước 3: Trường Đại học C xử lý kho 50.000 tài liệu gồm PDF scan, Word và HTML. Họ dùng MinerU để chuẩn hóa tất cả sang Markdown, sau đó áp dụng recursive chunking cho quy chế và semantic chunking cho tài liệu nghiên cứu. Kết quả pilot: độ chính xác câu hỏi về quy chế đạt 91%, phản hồi trong 2-3 giây. Cùng bộ dữ liệu đó, nếu dùng fixed-size chunking, con số chỉ là khoảng 55-60%.
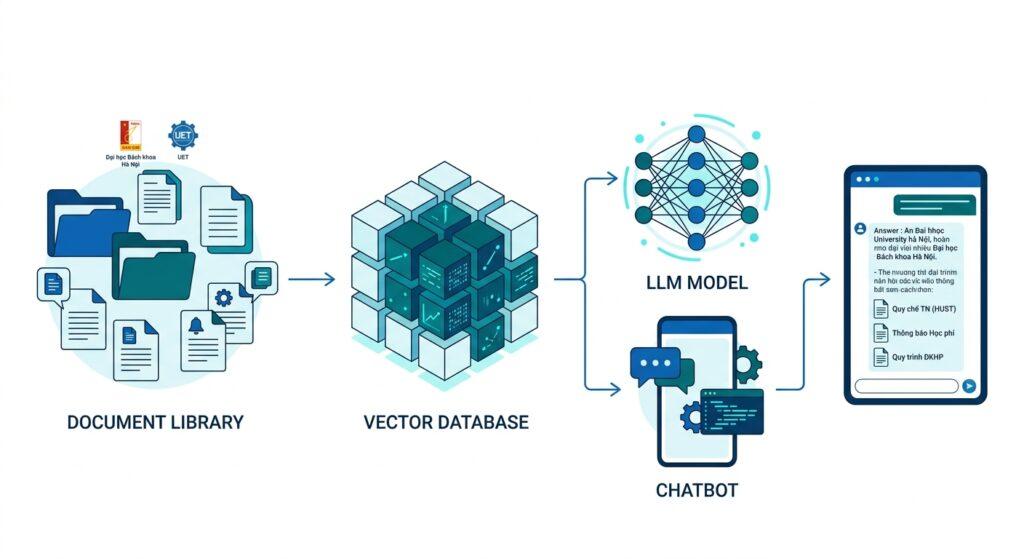
Đầu ra bước 3: Vector database với dữ liệu pilot đã được index, kèm schema metadata rõ ràng.
Bước 4: Triển khai pilot – Thử trên quy mô nhỏ, học từ người dùng thật
Đừng roll out toàn trường ngay. Chọn 1 khoa, 50-100 sinh viên, chạy thử 4-6 tuần. Pilot không phải là bước “kiểm tra xem có lỗi không” – nó là nơi bạn học được những thứ không thể đoán trước.
Kiểm soát truy cập trong retrieval (RBAC)
Đây là điểm nhiều team bỏ qua đến khi xảy ra sự cố. Khi sinh viên A hỏi “điểm môn Giải tích của tôi là bao nhiêu?”, hệ thống phải đảm bảo chỉ truy xuất dữ liệu của sinh viên A – dù hồ sơ sinh viên B có “similarity score” cao hơn.
Ba nguyên tắc bảo mật cần áp dụng từ bước này:
- Không log câu hỏi nguyên bản có thể chứa thông tin cá nhân (tên, mã số SV). Chỉ log hash hoặc metadata ẩn danh để debug.
- Mã hóa PII ngay từ bước embedding – trước khi dữ liệu đi vào vector store, mask các trường nhạy cảm (họ tên, mã SV, điểm số) bằng token placeholder.
- Compound metadata filter khi query:
{ "$and": [{"truong_id": "X"}, {"ma_sv": "ABC123"}, {"quyen": {"$in": ["public", "sinh_vien"]}}] }– thiếu bất kỳ điều kiện nào cũng đủ để lộ dữ liệu chéo.
Đánh giá chất lượng
Chuẩn bị 20-30 câu test bao phủ: câu đơn giản, câu cần tổng hợp nhiều nguồn, câu về số liệu cụ thể. Đặc biệt để ý câu hỏi mà hệ thống trả lời sai nhưng tự tin – đây là “hallucination” nguy hiểm nhất. Yêu cầu LLM luôn trích dẫn nguồn cụ thể (tên tài liệu, điều khoản); nếu câu trả lời không có source, coi là đáng ngờ.
Mini case study – Bước 4: Trong pilot tại một khoa với 80 sinh viên, câu hỏi được hỏi nhiều nhất không phải về quy chế mà là “deadline nộp đơn xin miễn giảm học phí”. Thông tin này nằm rải rác trong nhiều thông báo khác nhau, không có văn bản tập trung. Team phải bổ sung thêm loại tài liệu này vào pipeline – điều họ không nghĩ đến trước pilot. Đây chính là lý do pilot quan trọng hơn lý thuyết.
Đầu ra bước 4: Báo cáo pilot (metrics độ chính xác, latency, feedback người dùng) + danh sách vấn đề cần xử lý trước khi scale.
Bước 5: Vận hành production – Từ prototype đến hệ thống đáng tin cậy
Pilot thành công không có nghĩa production sẽ ngon. Hệ thống production cần thêm các lớp bền vững.
Evaluation liên tục với RAGAS
Dùng RAGAS để đánh giá định kỳ (hàng tuần hoặc hàng tháng) theo 3 chỉ số: faithfulness (câu trả lời có trung thực với nguồn không?), relevance (nguồn có liên quan đến câu hỏi không?), answer correctness. Có metrics thì mới biết hệ thống đang tốt lên hay xuống cấp khi thêm dữ liệu mới.
Tối ưu retrieval
Hybrid search (kết hợp semantic search + keyword BM25) thường cho kết quả tốt hơn chỉ dùng một phương pháp. Với tài liệu quy chế, từ khóa chính xác (“Điều 15”, “Khoản 3”) quan trọng không kém ngữ nghĩa. Nếu muốn tăng độ chính xác, thêm reranking bằng Cross-Encoder model sau bước retrieval sơ bộ – tốn thêm ~200ms latency nhưng đáng.
Cập nhật dữ liệu
Dữ liệu đại học thay đổi liên tục: quy chế mới, thông báo học phí, lịch thi. Cần pipeline cập nhật bán tự động: khi phòng đào tạo upload tài liệu mới, pipeline tự động re-index vào vector store. Không có cơ chế này, chatbot sẽ trả lời thông tin cũ trong khi website trường đã cập nhật – mất lòng tin ngay lập tức.
Chuyển giao vận hành
Đây là bước nhiều dự án quên. Khi team xây xong và chuyển giao cho IT vận hành, phải có: runbook xử lý sự cố, hướng dẫn cập nhật dữ liệu, dashboard monitoring (latency, error rate, cost nếu dùng cloud), và contact người có thể hỗ trợ khi cần. Tôi từng thấy hệ thống chạy tốt 3 tháng rồi chết âm thầm vì không ai biết xử lý khi vector DB đầy dung lượng.
Đầu ra bước 5: Hệ thống production với monitoring, runbook vận hành, và kế hoạch cập nhật dữ liệu định kỳ.
Câu hỏi thường gặp
RAG có thể thay thế hoàn toàn bộ phận hỗ trợ sinh viên không?
Không hoàn toàn. RAG rất tốt cho câu hỏi dựa trên tài liệu (quy chế, thủ tục, thông tin chung). Nhưng các tình huống cần đồng cảm, tư vấn cá nhân sâu, hoặc quyết định phức tạp vẫn cần con người. RAG là công cụ hỗ trợ, giúp nhân viên tập trung vào những việc thực sự cần họ.
Cần bao nhiêu dữ liệu để bắt đầu pilot?
50-200 tài liệu liên quan đến use-case cụ thể là đủ để thấy kết quả. Chất lượng quan trọng hơn số lượng – 100 tài liệu sạch tốt hơn 1.000 tài liệu hỗn tạp.
Làm sao phát hiện hệ thống RAG đang hallucinate?
Yêu cầu LLM luôn trích dẫn nguồn cụ thể (tên tài liệu, điều khoản, trang). Câu trả lời không có source là tín hiệu đáng ngờ. Dùng RAGAS để đo faithfulness định kỳ và so sánh theo thời gian.
Nên dùng embedding model nào cho tiếng Việt?
Bắt đầu với text-embedding-3-small của OpenAI (rẻ, tốt) hoặc bge-m3 (đa ngôn ngữ, miễn phí, chạy local). Với tài liệu tiếng Việt chuyên ngành, bge-m3 thường cho kết quả tốt hơn các model chỉ được optimize cho tiếng Anh.
Kết luận
Xây hệ thống RAG cho trường đại học không phải chuyện thuần kỹ thuật. Nó đòi hỏi hiểu nghiệp vụ giáo dục, nhạy cảm với ràng buộc bảo mật dữ liệu sinh viên, và kỷ luật trong vận hành lâu dài. Lộ trình 5 bước trên đúc kết từ những dự án thực – cả thành công lẫn thất bại.
Điều quan trọng nhất tôi muốn bạn mang về: hãy bắt đầu từ Bước 1 – đánh giá thực trạng. Nhiều team hào hứng với công nghệ và nhảy vào Bước 3, Bước 4 rồi vấp ngã ở điều tưởng như đơn giản nhất: dữ liệu không sạch, không có người vận hành.
RAG không biến LLM thành siêu trí tuệ. Nó biến LLM thành đồng nghiệp đáng tin cậy – biết đúng những gì trường bạn có, trả lời có trách nhiệm, và biết giới hạn của mình.