Prompt vs Context Engineering
Prompt của bạn đã ổn rồi. Nhưng agent vẫn fail.
Bạn đã thấy pattern này: dành hàng giờ chỉnh sửa system prompt, test với cả tá kịch bản khác nhau, rồi đưa lên production. Sau đó một user gặp trường hợp ngoại lệ và agent tự tin đưa ra quyết định sai. Không phải vì hướng dẫn của bạn chưa rõ ràng, mà vì model không thấy được trạng thái tài khoản của user, không thấy bản cập nhật policy mới nhất, hoặc không thấy output của bước chạy cách đây ba mươi giây. Prompt chỉ nói với model phải làm gì. Chẳng ai nói với nó đang nhìn thấy gì.
Tháng 6/2025, Andrej Karpathy đăng bài trở thành một trong những quan điểm được chia sẻ nhiều nhất trong cộng đồng AI engineering: “Mọi người thường nghĩ prompt là mô tả tác vụ ngắn gọn. Nhưng thực tế, trong mọi ứng dụng LLM công nghiệp, context engineering mới là nghệ thuật và khoa học tinh tế về việc điền vào context window đúng thông tin cho bước tiếp theo.” CEO Shopify Tobi Lütke hưởng ứng quan điểm này vài ngày sau, gọi context engineering là “kỹ năng cốt lõi” để xây dựng với LLM. Thuật ngữ lan nhanh vì nó đặt tên cho thứ mà các practitioner đã làm hàng tháng trời mà chưa có từ ngữ chính xác để mô tả.
Bài viết này truy vết sự chuyển đổi từ prompt engineering sang context engineering, điều gì đã thay đổi, tại sao thay đổi, và nó có ý nghĩa gì với cách bạn xây dựng ứng dụng LLM hiện tại.
Prompt Engineering Đã Đúng ở Điểm Nào?
Trước tiên, hãy ghi nhận những gì xứng đáng. Prompt engineering là kỷ thuật đầu tiên để làm việc với LLM, và nó mang lại kết quả thực sự.
Từ 2022 đến 2024, các kỹ thuật như chain-of-thought prompting, few-shot examples, và role-based system prompts đã biến các language model khó đoán thành công cụ thực sự hữu ích. Các team học được rằng thêm cụm “think step by step” có thể cải thiện độ chính xác toán học lên hơn 40%. Họ học được rằng sự khác biệt giữa chatbot tầm thường và chatbot tốt thường nằm ở ba ví dụ được chọn kỹ trong system prompt. Với các tác vụ một lượt tương tác – tóm tắt, phân loại, sinh code từ spec rõ ràng prompt engineering hoạt động tốt.
Tuy nhiên, vấn đề không phải là prompt engineering sai. Mà là các tác vụ trở nên khó hơn.
Tại Sao Prompt Ngừng Hoạt Động?
Các vết nứt xuất hiện khi các team chuyển từ demo sang production, và từ tác vụ một lượt sang agent chạy quy trình nhiều bước.
Hãy xem xét những gì một AI agent thực sự cần để xử lý case hỗ trợ khách hàng: tin nhắn của user, lịch sử tài khoản, sản phẩm họ đang hỏi, chính sách hoàn tiền hiện tại của công ty bạn (vừa thay đổi thứ Ba tuần trước), ba tin nhắn trước đó trong cuộc hội thoại này, và output của lệnh tool vừa kiểm tra trạng thái đơn hàng. Đó là sáu loại thông tin khác nhau, mỗi loại từ một nguồn khác nhau, mỗi loại có yêu cầu độ tươi (freshness) khác nhau. Chẳng có prompt nào có thể giải quyết vấn đề này. Prompt chỉ là một lớp trong một kiến trúc thông tin lớn hơn nhiều.
Cụ thể, dữ liệu chứng minh điều này. Chroma Research đã test 18 frontier models bao gồm GPT-4.1, Claude 4, và Gemini 2.5 và phát hiện hiệu suất suy giảm toàn diện khi độ dài context tăng lên. Độ chính xác giảm 20-50% khi chuyển từ 10K lên 100K+ tokens, với một số model rơi từ 90% xuống 51% độ chính xác trong các bài test đối thoại nhiều lượt. Tệ hơn, họ phát hiện đường cong attention hình chữ U: model chú ý mạnh ở đầu và cuối context window, với độ chính xác giảm hơn 30% cho thông tin nằm ở giữa.
Hơn nữa, ném thêm token vào cũng chẳng giúp gì. Một nghiên cứu riêng năm 2025 phát hiện độ chính xác LLM giảm 24,2% khi thông tin liên quan được nhúng trong context dài hơn, ngay cả khi tất cả các token không liên quan đã bị mask và model chỉ chú ý đến bằng chứng và câu hỏi. Model có quyền truy cập đúng thông tin. Nó chỉ không thể sử dụng hiệu quả.
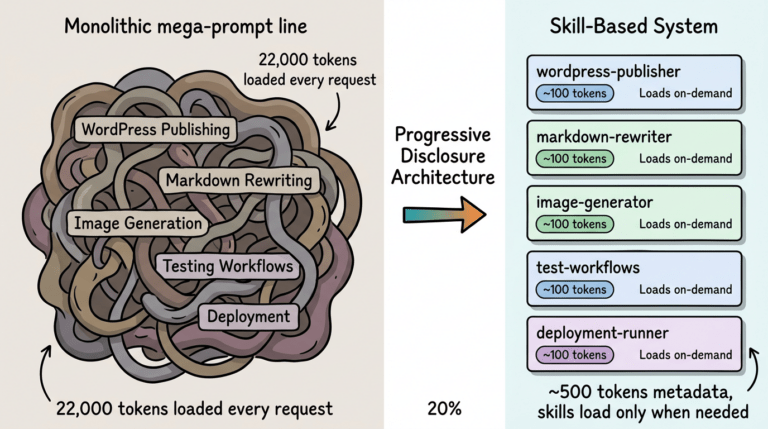
Progressive disclosure giải quyết vấn đề này bằng cách load context theo từng lớp thay vì dump tất cả cùng lúc.
Đây là vấn đề cơ bản mà prompt engineering không thể giải quyết: vấn đề không phải là bạn nói cho model phải làm gì, mà là thông tin nào model có thể thấy và nó có thể suy luận tốt như thế nào trên đó.
Context Engineering Thực Sự Là Gì?
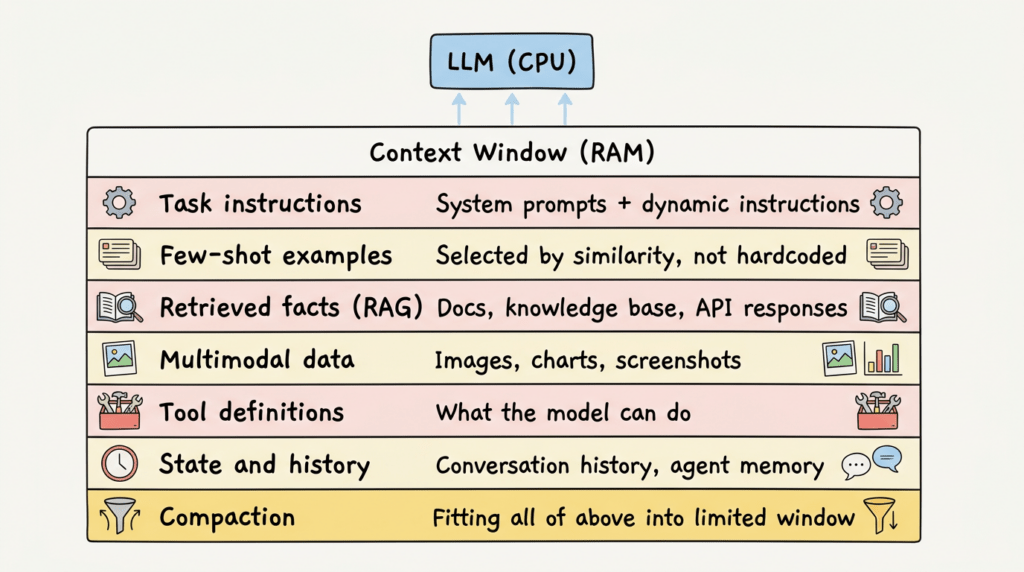
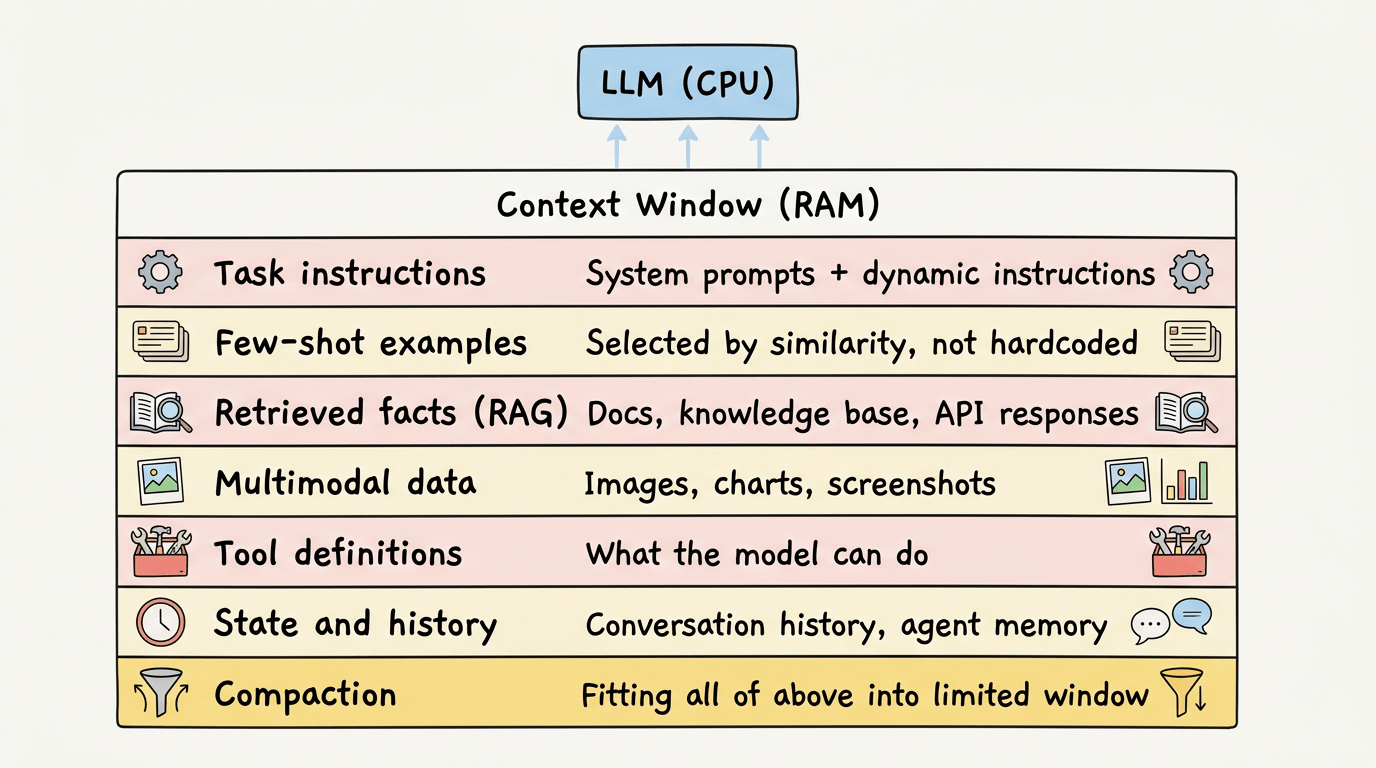
Mô hình tư duy của Karpathy hữu ích ở đây: hãy nghĩ LLM như CPU, và context window như RAM. Prompt engineering là về việc viết hướng dẫn tốt hơn cho CPU. Context engineering là về việc quản lý những gì trong RAG, cái gì load, khi nào, theo thứ tự nào, và cái gì bị loại bỏ khi không gian cạn.
Trong thực tế, context engineering có nghĩa là thiết kế toàn bộ pipeline thông tin cung cấp cho LLM của bạn. Chẳng hạn, Karpathy chia thành bảy thành phần:
- Task instructions: system prompt, đúng, nhưng cũng là các hướng dẫn động thay đổi dựa trên trạng thái hiện tại
- Few-shot examples: được chọn dựa trên độ tương đồng với input hiện tại, không phải hardcode
- Retrieved facts (RAG): các tài liệu, knowledge base entries, API responses được lấy tại thời điểm inference
- Multimodal data: ảnh, biểu đồ, screenshots khi chúng mang thông tin mà text không thể
- Tool definitions: những gì model có thể làm, mô tả đủ chính xác để model biết khi nào dùng từng tool
- State and history: lịch sử hội thoại, bộ nhớ agent, outputs từ các bước trước
- Compaction: nhét tất cả những thứ trên vào một cửa sổ giới hạn mà không mất những gì quan trọng
Sự chuyển đổi là từ viết một prompt sang thiết kế một hệ thống. Một prompt engineer viết hướng dẫn tốt. Một context engineer xây dựng pipeline tập hợp đúng 50K tokens từ một kho tiềm năng 5 triệu tokens, mỗi lần model cần đưa ra quyết định.
Bằng Chứng Rằng Context Thắng Fine-Tuning
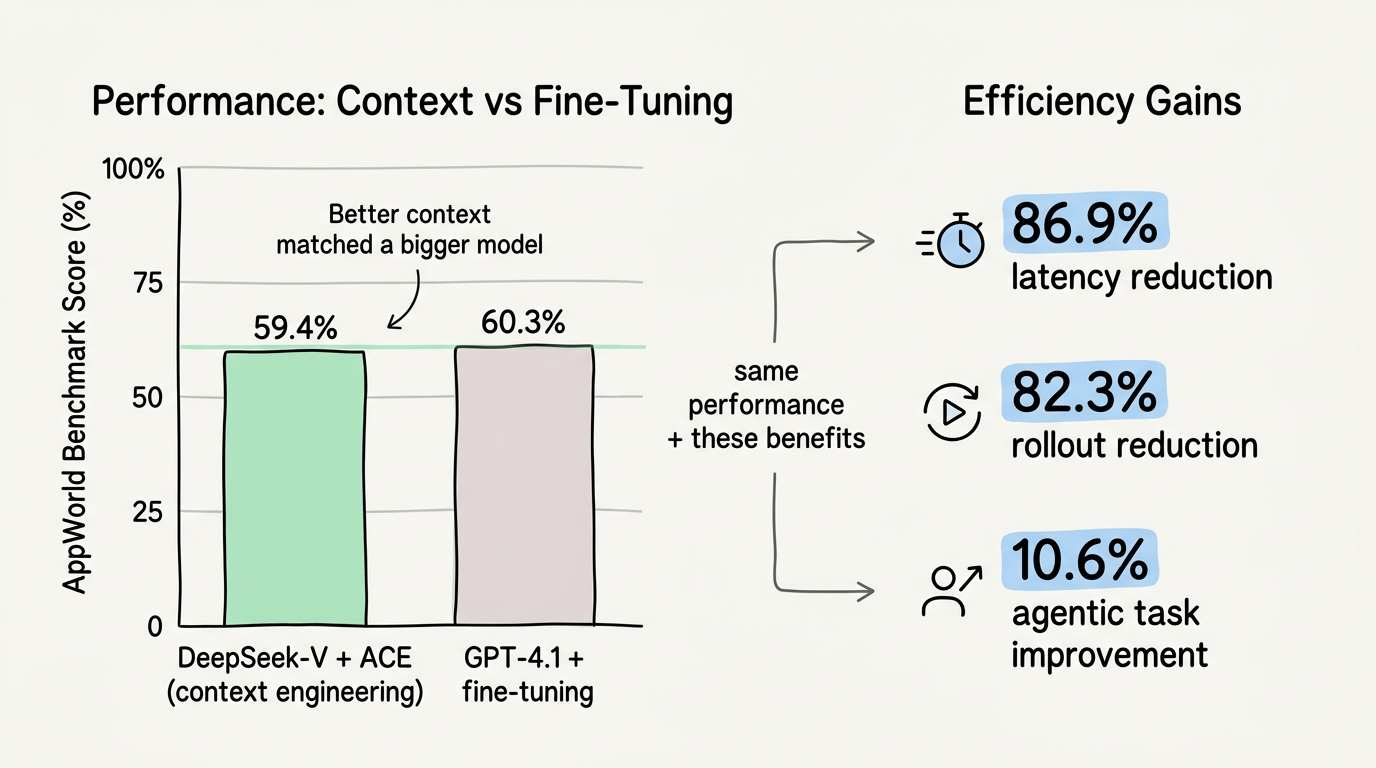
Nếu bạn nghi ngờ việc quản lý context quan trọng đến vậy, hãy nhìn vào những gì Stanford, SambaNova, và UC Berkeley công bố tháng 10/2025. Framework ACE (Agentic Context Engineering) của họ cải thiện hiệu suất LLM bằng cách chỉnh sửa và phát triển input context thay vì cập nhật model weights.
Do đó, kết quả ấn tượng: cải thiện 10,6% trên các tác vụ agentic và 8,6% trên suy luận tài chính, với độ trễ trung bình giảm 86,9% so với các phương pháp fine-tuning. Trên bảng xếp hạng AppWorld benchmark, phương pháp của họ dùng model open-source nhỏ hơn (DeepSeek-V) đạt 59,4%, ngang với hệ thống GPT-4.1 production-grade của IBM ở 60,3%.
Đọc lại câu đó. Context tốt hơn thắng model lớn hơn.
Ngoài ra, hiệu quả cũng tăng đáng kể. So với các phương pháp tối ưu context trước đó, ACE giảm độ trễ rollout 82,3% và cần ít hơn 75,1% rollouts. So với các phương pháp dynamic cheatsheet, nó giảm độ trễ thích ứng 91,5% và cắt chi phí token 83,6%.
Đây không phải kết quả đơn lẻ. Báo cáo State of Agent Engineering của LangChain, khảo sát 1.340 chuyên gia trong ngành cuối năm 2025, phát hiện 57% tổ chức hiện có AI agents trong production. Nhưng 32% nói chất lượng là rào cản hàng đầu và hầu hết lỗi chất lượng xuất phát từ quản lý context kém, không phải khả năng LLM. Các model đủ tốt rồi. Các context pipeline thì chưa.
Làm Thế Nào Áp Dụng Context Engineering Trong Thực Tế?
Lý thuyết thì hay. Đây là context engineering trông như thế nào trong thực tế.
Pattern Context Phân Lớp
Ví dụ, thay vì một system prompt nguyên khối, bạn xây dựng context theo các lớp kết hợp lúc runtime:
- Base layer: Định nghĩa vai trò, ràng buộc cốt lõi, định dạng output. Ổn định trên mọi request.
- Session layer: Profile user, sở thích, lịch sử hội thoại. Thay đổi mỗi phiên.
- Task layer: Tài liệu truy xuất, tool outputs, hướng dẫn bước hiện tại. Thay đổi mỗi lượt.
- Ephemeral layer: Scratchpad cho suy luận trung gian của model. Bỏ sau khi dùng.
Điều quan trọng, mỗi lớp có tần suất cập nhật riêng và nguồn chân lý riêng. Chẳng hạn, base layer có thể thay đổi hàng tháng. Task layer thay đổi vài giây một lần. Hệ thống của bạn cần quản lý chúng độc lập.
Pattern Truy Xuất Có Chọn Lọc
RAG (Retrieval Augmented Generation) là kỹ thuật context engineering phổ biến nhất, nhưng RAG ngây thơ, truy xuất top-K chunks và dump vào, chạy thẳng vào vấn đề context rot. Ngược lại, các phương pháp tốt hơn dùng:
- Query decomposition: Chia câu hỏi phức tạp thành các sub-queries, mỗi cái truy xuất context có mục tiêu
- Relevance filtering: Chấm điểm các chunks truy xuất và bỏ bất kỳ thứ gì dưới ngưỡng thay vì lấp đầy cửa sổ
- Source diversity: Đảm bảo context truy xuất bao phủ nhiều khía cạnh của câu hỏi, không phải năm chunks nói cùng một thứ
Hơn 60% doanh nghiệp hiện đang xây dựng hệ thống truy xuất AI, nhưng những tổ chức thấy cải thiện chất lượng thực sự là những tổ chức coi truy xuất như một vấn đề kỹ thuật, không phải một toggle cấu hình.
Pattern Nén Context
Khi bạn có 200K tokens thông tin liên quan và một context window 128K, phải bỏ gì đó. Tuy nhiên, truncation ngây thơ mất thông tin quan trọng. Thay vào đó, các kỹ thuật nén context bao gồm:
- Summarization chains: Tóm tắt các lượt hội thoại cũ hơn trong khi giữ nguyên các lượt gần đây
- Priority scoring: Gán trọng số cho các loại context khác nhau và bỏ các mục ưu tiên thấp nhất trước
- Hierarchical context: Lưu thông tin chi tiết trong bộ nhớ truy cập được bằng tool, giữ tóm tắt trong context chính
Điều quan trọng, những gì bạn loại khỏi context quan trọng không kém những gì bạn đưa vào. Bởi vì, các model thấy thông tin không liên quan không chỉ bỏ qua nó chúng thực sự bị nhiễu bởi nó, như nghiên cứu của Chroma chỉ ra.
Pattern Quản Lý State
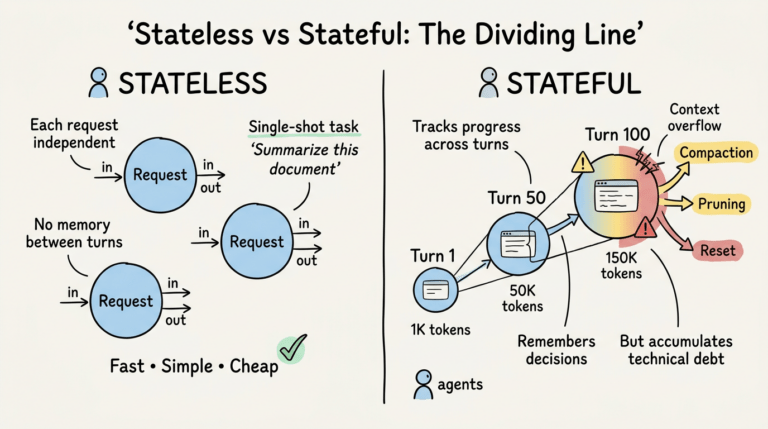
Với các agent chạy quy trình nhiều bước, context engineering có nghĩa là quản lý state giữa các bước:
- Carry forward: Outputs nào từ bước 3 mà bước 7 cần thấy?
- Memory consolidation: Sau 20 bước, kết quả trung gian nào vẫn quan trọng?
- Error context: Khi một bước fail, retry hoặc fallback cần context gì?
Đây là nơi “engineering” trong context engineering thực sự xuất hiện. Cụ thể, bạn đang thiết kế luồng dữ liệu giữa các bước, quyết định lưu gì so với bỏ gì, xử lý lỗi một cách graceful, những vấn đề mà backend engineers đã giải quyết hàng thập kỷ, áp dụng cho orchestration LLM. Context as architecture khám phá sâu hơn về cách thiết kế memory systems cho agents.
Khi Nào Prompt Engineering Là Đủ (Và Khi Nào Không)
Không phải mọi tích hợp LLM đều cần context pipeline. Đây là cách phân biệt:
Prompt engineering đủ khi:
- Tác vụ của bạn là một lượt (classify cái này, tóm tắt cái kia, generate cái này)
- Tất cả thông tin model cần fit trong một system prompt tĩnh
- Model không cần dữ liệu runtime từ các hệ thống bên ngoài
- Bạn đang xây prototype hoặc công cụ nội bộ với input dự đoán được
Bạn cần context engineering khi:
- Agent của bạn chạy quy trình nhiều bước, trong đó các bước sau phụ thuộc vào outputs của bước trước
- Model cần thông tin thời gian thực (dữ liệu user, tài liệu gần đây, API responses)
- Bạn thấy lỗi mặc dù hướng dẫn rõ ràng, vì model thiếu thông tin, không phải thiếu guidance
- Context window của bạn đang đầy và bạn cần quyết định giữ gì và bỏ gì
- Bạn chuyển từ demo sang production và chất lượng giảm ở quy mô lớn
Khi nào đầu tư vào pipeline đầy đủ: Nếu hệ thống của bạn thực hiện nhiều hơn một lần gọi LLM cho mỗi request của user, hoặc nếu nó truy xuất bất kỳ dữ liệu bên ngoài nào tại thời điểm inference, bạn đã đang làm context engineering. Câu hỏi là bạn đang làm một cách chủ ý hay vô tình.

Chuyển Từ Prompts sang Context: Bắt Đầu Từ Đâu
Bạn không cần kiến trúc lại mọi thứ cùng lúc. Thay vào đó, đây là lộ trình di chuyển thực tế:
Tuần 1: Audit context hiện tại của bạn. Với mỗi lần gọi LLM trong hệ thống, log toàn bộ nội dung context window. Đo: bao nhiêu là static so với dynamic? Bao nhiêu thực sự liên quan đến tác vụ hiện tại? Hầu hết các team phát hiện 40-60% context của họ là boilerplate hiếm khi thay đổi.
Tuần 2: Tách các lớp của bạn. Tiếp theo, chia system prompt nguyên khối thành base, session, và task layers. Chỉ riêng việc này thường phát hiện bugs bạn sẽ tìm thấy thông tin hardcoded lẽ ra phải dynamic, và thông tin dynamic lẽ ra phải static.
Tuần 3: Thêm truy xuất có chọn lọc. Sau đó, nếu bạn dùng RAG, thêm relevance scoring và filtering. Nếu bạn không dùng RAG, xác định ba cases hàng đầu mà agent của bạn fail vì thiếu thông tin runtime, và xây dựng retrieval cho chúng.
Tuần 4: Đo lường và theo dõi. Cuối cùng, track context utilization (bạn dùng bao nhiêu phần trăm cửa sổ?), context relevance (bao nhiêu phần trăm những gì bạn gửi thực sự quan trọng?), và context freshness (thông tin có hiện tại không?). Ba chỉ số này sẽ thúc đẩy tối ưu hóa của bạn trong nhiều tháng.
Các tổ chức đưa agents lên production không phải là những tổ chức có prompts thông minh nhất. Thực tế, theo dữ liệu của LangChain, 89% các team có production agents đã triển khai observability họ có thể thấy những gì trong context window và model dùng nó như thế nào.
Kỹ Năng Tích Lũy
Prompt engineering là kỹ năng viết. Context engineering là kỹ năng hệ thống.
Đó là sự khác biệt có ý nghĩa cho sự nghiệp và team của bạn. Cụ thể, viết một prompt tốt là hành động một lần. Thiết kế một context pipeline truy xuất đúng thông tin, nén thông minh, quản lý state giữa các bước, và thích ứng với yêu cầu mới, đó là công việc kỹ thuật tích lũy. Hơn nữa, mỗi cải thiện cho context layer của bạn khiến mọi prompt downstream hiệu quả hơn. Đồng thời, mỗi nguồn dữ liệu mới bạn tích hợp khiến agent của bạn xử lý được các kịch bản mà trước đây không thể.
Các công ty đang chi 37 tỷ đô la cho AI tổng quát năm 2025, tăng từ 11,5 tỷ năm 2024. Tuy nhiên, mức tăng 3,2x đó không dành cho các nhà viết prompt. Thay vào đó, nó dành cho cơ sở hạ tầng, hệ thống truy xuất, context pipelines, evaluation frameworks, observability tooling. Các team coi context như một kỷ luật kỹ thuật, không phải bài tập copywriting, là những team đang ship agents thực sự hoạt động.
Prompt giúp bạn bắt đầu. Context giữ bạn trong production.
Đọc Tiếp Series Context Engineering
Bài viết này là P1 trong series Context Engineering:
- P1: Từ Prompt đến Context (bài này)
- P2: Progressive Disclosure — Tại sao agent chết đắm trong context của chính nó
- P3: Từ RAG đến Agentic RAG — Khi truy xuất học cách suy nghĩ
- P4: Context as Architecture — Tại sao AI agent quên những điều quan trọng
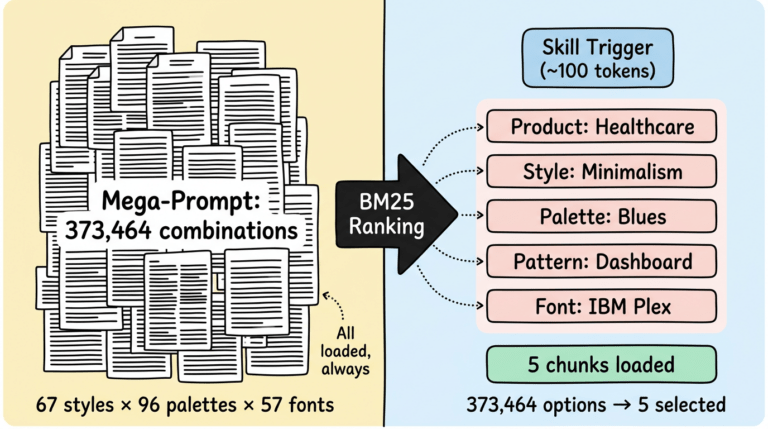
- P5: Agent Skills — Tại sao Claude Code khai tử mega-prompt
Viết dựa trên nghiên cứu từ Stanford ACE framework (Tháng 10/2025), nghiên cứu context rot của Chroma Research (Tháng 7/2025), báo cáo State of Agent Engineering của LangChain (Tháng 12/2025), và các bình luận từ Andrej Karpathy và Tobi Lütke. Xuất bản Tháng 3/2026.
Nguồn & Tham khảo
- Andrej Karpathy về context engineering — X/Twitter (Tháng 6/2025)
- Tobi Lütke về context engineering — X/Twitter (Tháng 6/2025)
- Context Rot — Chroma Research (Tháng 7/2025)
- ACE: Agentic Context Engineering — Stanford, SambaNova, UC Berkeley (Tháng 10/2025)
- State of Agent Engineering — LangChain (Tháng 12/2025)
- Context Engineering — Simon Willison (Tháng 6/2025)
- Context Engineering: Bringing Engineering Rigor — Addy Osmani / O’Reilly (2025)
- What Is Context Engineering — Gartner (2025)
- Context Engineering Guide — Prompting Guide (2025)