1. Bài Toán Tìm Kiếm Gần Đúng Và Giới Hạn Của Hashing Truyền Thống
Trong nhiều bài toán hiện đại như tìm kiếm văn bản, gợi ý sản phẩm hay so khớp ảnh, ta không cần tìm kết quả giống hệt, mà là kết quả gần giống nhất. Đây là bài toán Approximate Nearest Neighbor (ANN) trên không gian dữ liệu có số chiều lớn.
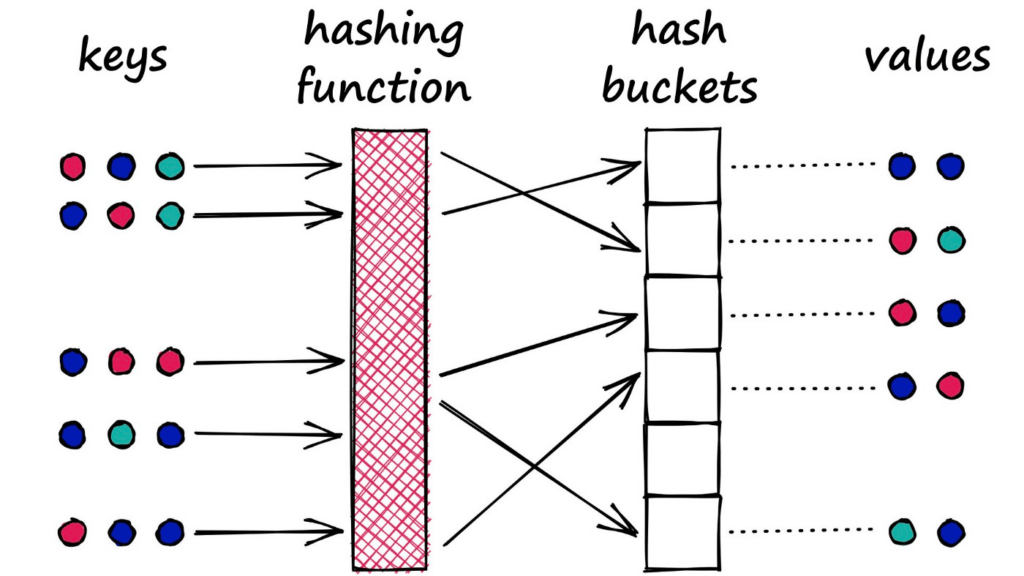
Hashing truyền thống được thiết kế với mục tiêu phân tán dữ liệu đều vào các bucket, nên các phần tử tương tự nhau không có đảm bảo rơi vào cùng một bucket. Khi số chiều tăng cao, việc tính toán khoảng cách giữa mọi cặp điểm trở nên rất tốn kém – hiện tượng này thường được gọi là lời nguyền số chiều (curse of dimensionality). Locality-Sensitive Hashing ra đời để giải quyết chính xác vấn đề này.
2. Ý Tưởng Cốt Lõi Của Locality-Sensitive Hashing
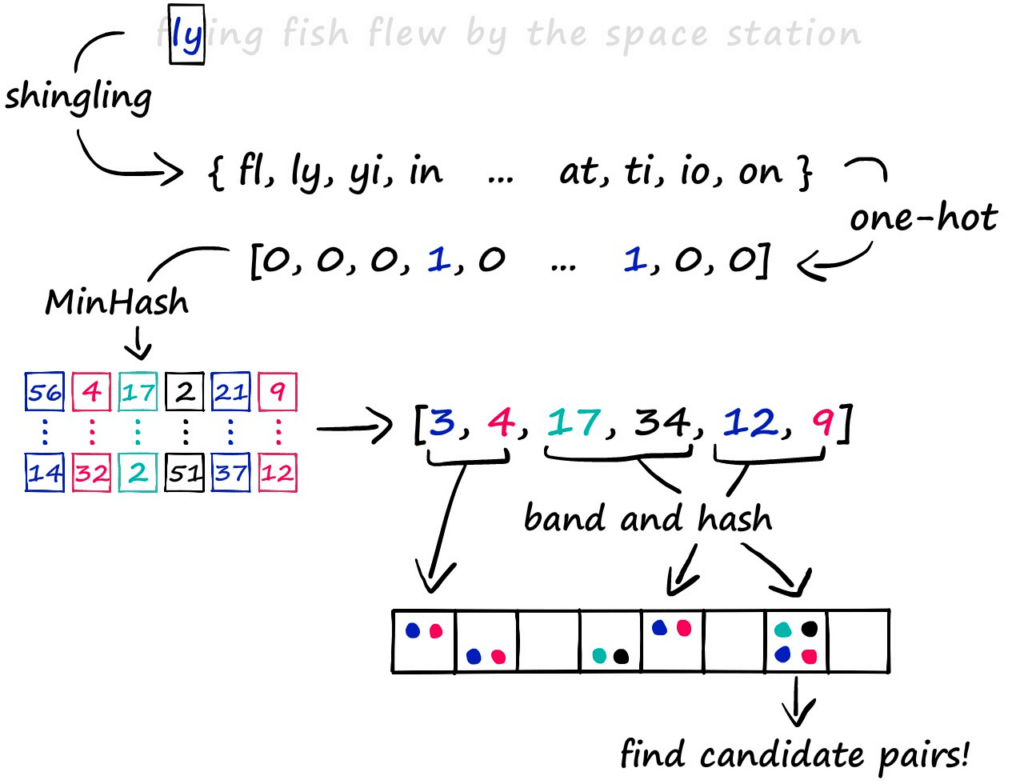
LSH đảo ngược triết lý của hashing truyền thống. Thay vì cố gắng phân tán dữ liệu, LSH thiết kế các hàm băm sao cho:
Các điểm gần nhau trong không gian có xác suất cao rơi vào cùng một bucket.
LSH sử dụng nhiều hàm băm và nhiều bảng băm song song. Mỗi hàm băm ánh xạ một điểm dữ liệu thành một khóa, thường dựa trên phép chiếu ngẫu nhiên. Khi truy vấn, thay vì tìm kiếm toàn bộ không gian, ta chỉ cần kiểm tra các điểm nằm trong cùng bucket với truy vấn.
Tùy theo loại khoảng cách, có các biến thể LSH phổ biến:
- Cosine similarity (phổ biến trong xử lý văn bản, embedding)
- Euclidean distance (không gian số liên tục)
- Jaccard similarity (tập hợp, shingling)
Cách tiếp cận này đánh đổi độ chính xác tuyệt đối để đổi lấy tốc độ vượt trội.
3. Đánh Giá, Trade-off Và Ứng Dụng
LSH giúp giảm đáng kể độ phức tạp tìm kiếm, từ việc phải so sánh với toàn bộ dữ liệu xuống chỉ còn một tập con nhỏ. Tuy nhiên, nó không đảm bảo luôn tìm được hàng xóm gần nhất chính xác, mà chỉ là xấp xỉ với xác suất cao.
Các trade-off chính của LSH bao gồm:
- Số lượng hàm băm: nhiều hơn → chính xác hơn nhưng tốn bộ nhớ
- Số bảng băm: nhiều hơn → tăng khả năng tìm đúng nhưng chậm hơn
- Độ rộng bucket: ảnh hưởng trực tiếp đến recall và precision
LSH được ứng dụng rộng rãi trong:
- Hệ thống gợi ý (recommendation systems)
- Tìm kiếm tương tự trong embedding (NLP, image search)
- Phát hiện trùng lặp và near-duplicate
- Xử lý dữ liệu lớn nơi brute-force không khả thi
Kết Luận
Locality-Sensitive Hashing là một kỹ thuật quan trọng giúp đưa bài toán tìm kiếm gần đúng từ lý thuyết vào thực tế. Bằng cách chấp nhận kết quả xấp xỉ, LSH cho phép hệ thống xử lý hiệu quả các tập dữ liệu lớn và có số chiều cao. Trong kỷ nguyên big data và embedding, LSH đóng vai trò là một trong những nền tảng cốt lõi cho các hệ thống tìm kiếm và gợi ý hiện đại.