Việc xây dựng API là một phần cốt lõi trong phát triển phần mềm hiện đại. Thật thú vị khi mọi thứ hoạt động trơn tru. Nhưng sớm hay muộn, các vấn đề hiệu suất sẽ bắt đầu xuất hiện — phản hồi chậm, timeout, máy chủ bị quá tải — và đột nhiên, chẳng người dùng nào muốn dùng API của bạn nữa.
Khi API của bạn bắt đầu trở nên “chậm chạp”, khiến trải nghiệm người dùng bị ảnh hưởng, hệ thống quá tải và việc gỡ lỗi trở thành một cơn ác mộng.
Giải pháp cho vấn đề hiệu suất này là gì?
Dưới đây những chiến lược đã được kiểm chứng có thể giúp tăng hiệu suất API mà không cần viết lại toàn bộ hệ thống. Dưới đây là 5 trong số đó:
1. Caching: Tăng Tốc Với Bộ Nhớ
Cốt lõi của việc caching là tránh việc lặp lại công việc.
Thay vì mỗi lần client yêu cầu, bạn lại truy vấn database, bạn sẽ lưu tạm dữ liệu trong bộ nhớ (cache). Lần sau, nếu client cần cùng dữ liệu, API sẽ lấy dữ liệu từ cache; vì vậy, tốc độ phản hồi sẽ nhanh hơn rất nhiều so với việc truy vấn trực tiếp vào database; hơn nữa, cách tiếp cận này còn giúp giảm độ trễ và tối ưu tài nguyên hệ thống
⚙️Cách hoạt động:
- Khi có request, kiểm tra xem dữ liệu đã nằm trong cache chưa.
- Nếu có → trả về ngay (cache hit).
- Nếu không → lấy từ database, trả về cho client, và lưu vào cache (cache miss).

🌏Ví dụ thực tế:
Một số nền tảng lớn như Facebook và LinkedIn phục vụ hàng triệu người dùng mỗi giây sử dụng cơ chế caching. Kiến trúc Facebook sử dụng Memcached để lưu trữ các dữ liệu profile người dùng đã được render sẵn, trong khi LinkedIn sử dụng cache với chính sách TTL-based cache invalidation để luôn luôn đảm bảo dữ liệu là mới nhất.
💡Một số lưu ý:
- Việc invalidation cache (khi nào làm mới hoặc xóa cache cũ) khá phức tạp.
- Nếu lạm dụng, dễ khiến hệ thống trả về dữ liệu lỗi thời (stale).
2. Cân Bằng Tải (Load Balancing): Mở Rộng, Tăng khả năng xử lý.
Khi một máy chủ không đủ khả năng xử lý lưu lượng lớn người dùng truy cập cùng một lúc, việc cần làm là scale out — chạy API trên nhiều máy chủ khác nhau.
Việc scale out hệ thống mang đến một thách thức: Làm sao để phân phát các request đi đến cho các máy chủ phù hợp?
Đây là lúc Load Balancer xuất hiện.
⚙️Cách hoạt động:
- Load balancer nằm giữa client và các máy chủ.
- Nó chuyển tiếp request theo các quy tắc như “round-robin”, “ít kết nối nhất”, hoặc theo vị trí địa lý.
- Nếu một server gặp trục trặc, nó sẽ tự động chuyển hướng đến máy chủ khỏe mạnh khác, luôn giữ cho hệ thống luôn chạy.

💪Lợi ích:
- Tránh tình trạng một máy chủ trở thành nút cổ chai.
- Cải thiện hiệu suất và tính sẵn sàng (availability).
💡Lưu ý:
- Load balancer hiệu quả nhất khi API “stateless” — tức là không lưu trữ trạng thái (state) riêng cho mỗi người dùng hoặc session. Nếu không, request có thể “rơi” vào server không có ngữ cảnh phù hợp.
- Một số lựa chọn phổ biến: Nginx, HAProxy, AWS ELB, Traefik.
3. Xử Lý Bất Đồng Bộ (Async Processing): xử lý mọi thứ đồng thời.
Không phải mọi request đều cần được xử lý đồng bộ (synchronous).
Đôi khi, sẽ thông minh hơn là tiếp nhận request, đẩy nó vào queue, và trả về phản hồi ngay lập tức — đặc biệt nếu công việc mất thời gian như gửi email, xử lý ảnh, hay phân tích.
Đây là lúc asynchronous (async) bước vào.
⚙️Cách hoạt động:
- API nhận request, trả lời ngay (acknowledge).
- Đẩy tác vụ vào hàng đợi message queue như Kafka hoặc RabbitMQ.
- Một worker background sẽ lấy nhiệm vụ từ queue và xử lý nó độc lập.

💪Lợi ích:
- API trả lời nhanh hơn.
- Thích hợp cho tác vụ chạy lâu hoặc nền (background).
- Ngăn ngừa tài nguyên máy chủ bị “hút cạn”.
💡Cân nhắc:
- Người dùng cần cách để kiểm tra trạng thái hoặc nhận thông báo khi tác vụ hoàn thành.
- Cần đảm bảo retry (thử lại) và xử lý lỗi trong phần background worker.
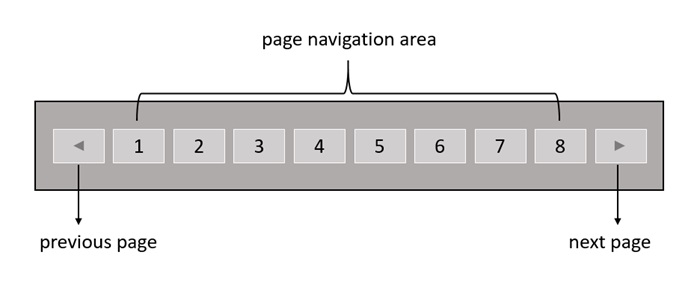
4. Phân Trang (Pagination): Trả Dữ Liệu Theo Từng Phần, Không Buffets.
Trả hàng nghìn bản ghi trong một phản hồi API? Điều đó dễ làm server quá tải, tăng độ trễ mạng, và gây khó chịu cho client.
Đây là lúc Pagination giúp giới hạn lượng dữ liệu trả về mỗi lần.
⚙️Cách hoạt động:
- Client gửi các tham số như
page=1vàlimit=20. - API trả về “miếng” dữ liệu tương ứng.
- Client có thể yêu cầu trang tiếp theo khi cần.
💪Lợi ích:
- Giảm kích thước payload.
- Cải thiện cảm nhận hiệu suất từ phía UI (cập nhật nhanh hơn).
- Giảm áp lực cho cả server và client.
🔑Một số cách phổ biến:
- Offset-based pagination (theo trang + giới hạn),
- Cursor-based pagination (tốt hơn khi quy mô lớn).
5. Connection Pooling: Tái Sử Dụng Kết Nối Cơ Sở Dữ Liệu
Mỗi API call rất có thể liên quan đến truy vấn database.
Nếu bạn tạo một kết nối mới đến database mỗi lần, đó là cách lãng phí — giống như mở vòi nước mới cho mỗi lần uống.
Connection pooling giúp giữ một “bể” các kết nối sẵn sàng đến database.
⚙️Cách hoạt động:
- Khi có request, sử dụng một kết nối sẵn có từ pool.
- Sau khi truy vấn xong, kết nối được trả lại pool chứ không đóng.
- Nếu tất cả kết nối đang bận, request sẽ chờ một kết nối rảnh.

💪Lợi ích:
- Tiết kiệm thời gian và tài nguyên hệ thống.
- Xử lý nhiều người dùng đồng thời hiệu quả hơn.
- Giảm tải lên database.
Công cụ / Framework hỗ trợ: Hầu hết framework web / ORM đều hỗ trợ connection pooling (ví dụ: HikariCP, SQLAlchemy pool, pgbouncer cho PostgreSQL).
reference: API Performance Improvement Tips – by Saurabh Dashora