Lời Mở Đầu: Tại Sao Phải Hiểu Internals?
Nhiều kỹ sư dùng Kafka chỉ qua lớp abstraction: publish, consume, done. Tuy nhiên, khi hệ thống đi vào production, những câu hỏi khó bắt đầu xuất hiện mà không có câu trả lời rõ ràng nếu bạn chưa hiểu bên trong.
Chẳng hạn, “Tại sao Consumer lag tăng đột biến?” là một triệu chứng mà nguyên nhân gốc rễ thường nằm ở cách Partition được phân bổ. Tương tự, “Tại sao thêm Consumer vào Group không giúp gì?” liên quan trực tiếp đến giới hạn số lượng Partition. Ngoài ra, việc chọn sai số Partition ngay từ đầu còn là một quyết định không thể đảo ngược. Câu trả lời cho tất cả những vấn đề trên đều nằm sâu bên trong kiến trúc lưu trữ của Kafka. Bài này sẽ đưa bạn vào bên trong — đến tận cấp độ file trên ổ cứng. Nếu bạn chưa đọc Bài 1: Apache Kafka Là Gì?, hãy xem qua trước để nắm nền tảng về Event-Driven Architecture.
1. Kiến Trúc Tổng Thể — Nhìn Từ Trên Cao
┌─────────────────────────────────────────────────────────────────┐
│ KAFKA CLUSTER │
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Broker 1 │ │ Broker 2 │ │ Broker 3 │ │
│ │ │ │ │ │ │ │
│ │ payment_events-P0 (Leader) │ │ │ │
│ │ payment_events-P1 (Follower) │ │payment_events-P1(Leader)│
│ │ order_events-P0 (Follower) │ │order_events-P0(Leader) │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
│ │
│ Controller (KRaft): Broker 1 (elected) │
└─────────────────────────────────────────────────────────────────┘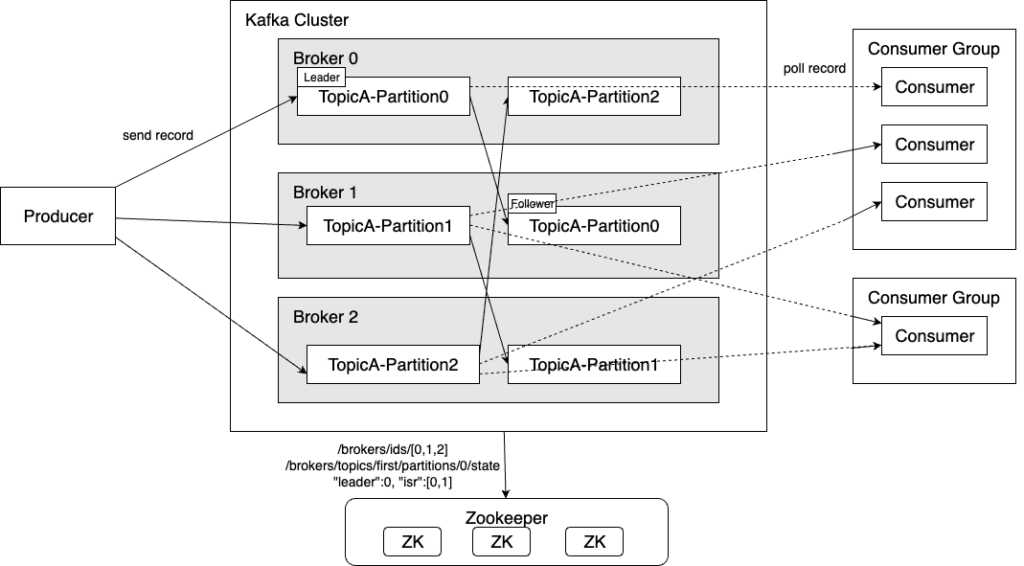
Kafka Cluster là một tập hợp các Broker — mỗi Broker là một process Java chạy trên một server vật lý hoặc VM. Điểm quan trọng cần nắm ngay từ đầu là chúng không chia sẻ state qua database chung; thay vào đó, state được đồng bộ qua log nội bộ của KRaft, giúp loại bỏ sự phụ thuộc vào Zookeeper trong các phiên bản mới.
2. Topic và Partition — Logic vs Vật Lý
Topic: Lớp Abstraction Cho Developer
Topic là một tên gọi logic cho một luồng dữ liệu — giống như bạn đặt tên bảng trong database. Khi Producer ghi vào topic payment_events, nó không cần biết dữ liệu thực sự nằm ở đâu trên disk. Tuy nhiên, phía sau lớp abstraction đó là cơ chế phân phối vật lý phức tạp hơn nhiều so với những gì bạn thấy.
Partition: Đơn Vị Scale-Out Thực Sự
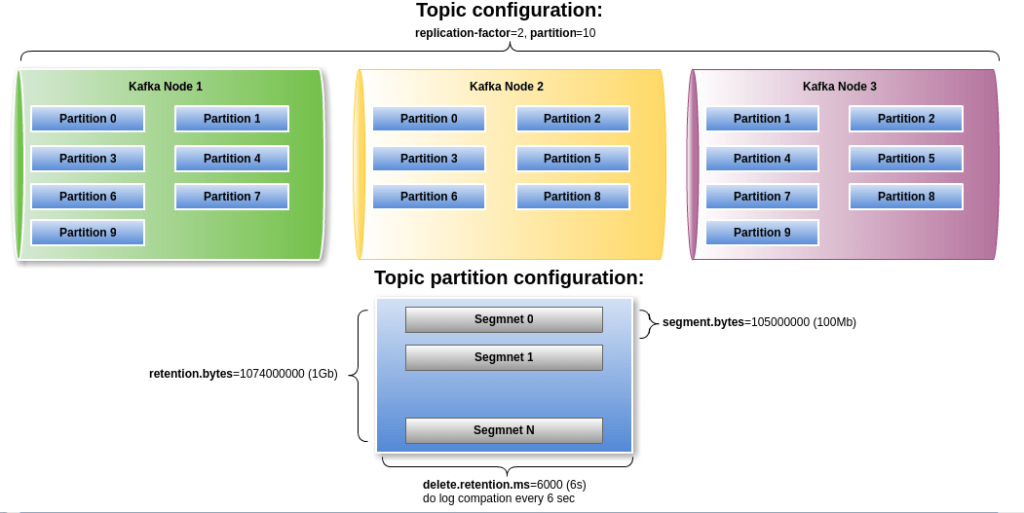
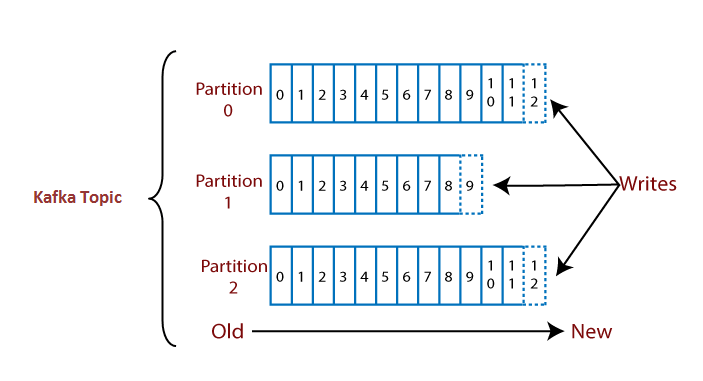
Mỗi Topic được chia thành N Partition (cấu hình khi tạo topic). Đây là điểm mấu chốt quyết định khả năng scale của toàn hệ thống:
Topic: payment_events (3 partitions)
│
├── Partition-0 ──► Broker 1, Disk: /kafka/data/payment_events-0/
├── Partition-1 ──► Broker 2, Disk: /kafka/data/payment_events-1/
└── Partition-2 ──► Broker 3, /kafka/data/payment_events-2/Do đó, throughput tổng thể của một Topic là tổng throughput của tất cả Partition chạy song song:
1 Partition: 100MB/s × 1 = 100MB/s
3 Partition: 100MB/s × 3 = 300MB/s (song song trên 3 Broker)Lưu Ý Quan Trọng: Không Thể Giảm Partition
⚠️ Sau khi tạo Topic, bạn có thể tăng số Partition nhưng KHÔNG THỂ GIẢM. Kafka dùng hàm hash trên key của message để quyết định message đi vào Partition nào:
Partition = hash(key) % numPartitions. Nếu giảm Partition, tất cả consumer đang giữ offset của Partition bị xóa sẽ trỏ đến dữ liệu sai — gây ra tình trạng mất dữ liệu về mặt logic.
Message Routing: Message Đi Vào Partition Nào?
// Producer tự chỉ định Partition:
ProducerRecord<String, String> record =
new ProducerRecord<>("payment_events", "user-789", payload);
// key = "user-789" → hash → Partition 1 (luôn luôn)
// Đảm bảo ordering cho cùng một user| Tình huống | Cơ chế routing |
|---|---|
| Key = null | Round-robin (phân phối đều) |
| Key != null | murmur2(key) % numPartitions |
| Tự chỉ định partition | Chỉ định trực tiếp |
| Custom Partitioner | Implement Partitioner interface |
3. Segment Files — Bí Mật Dưới Đáy Ổ Cứng
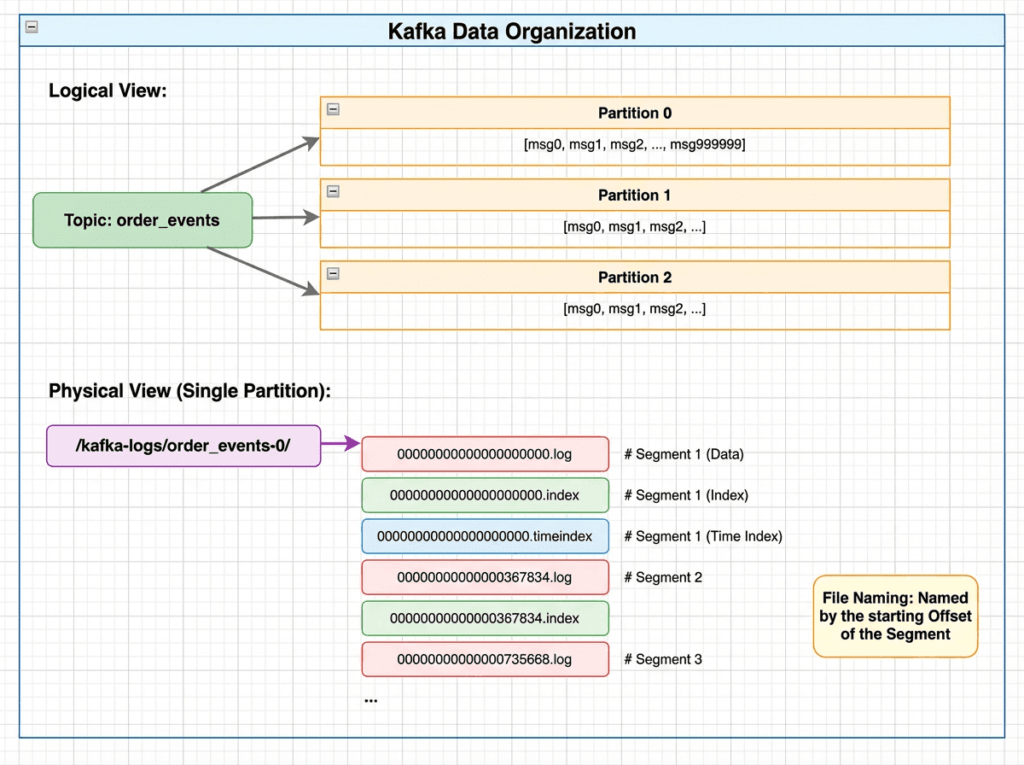
Đây là phần mà 90% kỹ sư dùng Kafka không biết. Hãy SSH vào Kafka server và xem:
$ ls -la /kafka/data/payment_events-0/
# Output thực tế:
00000000000000000000.log # Message data (0 → 999999)
00000000000000000000.index # Offset → Byte position index
00000000000000000000.timeindex # Timestamp → Offset index
00000000001000000.log # Message data (1000000 → 1999999)
00000000001000000.index
00000000001000000.timeindex
00000000002000000.log # Active segment (đang ghi)
00000000002000000.index
00000000002000000.timeindex
leader-epoch-checkpointTên file chính là Base Offset — offset đầu tiên của segment đó. Kafka quản lý nhiều segment thay vì một file khổng lồ nhằm cho phép xóa dữ liệu cũ theo cơ chế retention mà không cần scan toàn bộ partition.
3.1 File .log — Append-Only Message Store
┌─────────────────────────────────────────────────────────┐
│ .log file structure │
├──────────┬──────────┬───────────┬────────────────────────┤
│ Offset │ Size │ Timestamp │ Message Payload │
│ (8 bytes)│ (4 bytes)│ (8 bytes) │ (variable) │
├──────────┼──────────┼───────────┼────────────────────────┤
│ 2000000 │ 145 │ 171234... │ {"orderId":"abc"...} │
│ 2000001 │ 89 │ 171234... │ {"orderId":"def"...} │
│ 2000002 │ 203 │ 171234... │ {"orderId":"ghi"...} │
└──────────┴──────────┴───────────┴────────────────────────┘3.2 File .index — Tại Sao Kafka Tìm Message O(log n)?
.index file (sparse index):
┌─────────────────────┬─────────────────────┐
│ Relative Offset │ Physical Byte Pos │
├─────────────────────┼─────────────────────┤
│ 0 (=2000000) │ 0 │
│ 512 (=2000512) │ 74368 │
│ 1024 (=2001024) │ 148992 │
└─────────────────────┴─────────────────────┘Khi Consumer yêu cầu offset 2000700, Kafka thực hiện theo 2 bước. Đầu tiên, binary search trong .index để tìm entry gần nhất — cụ thể là offset 512 tại byte 74368. Tiếp theo, Kafka đọc .log từ byte 74368 và scan tuần tự để tìm offset 2000700. Nhờ đó, tổng chi phí chỉ là O(log n) cho binary search cộng O(k) với k là khoảng cách nhỏ — cực kỳ nhanh mà không cần load toàn bộ file vào memory.
3.3 Vòng Đời Của Segment — Retention vs Compaction
Kafka có 2 chiến lược quản lý dữ liệu cũ, mỗi chiến lược phù hợp với một use case khác nhau:
┌─────────────────────────────────────────────────────┐
│ 1. Time/Size-based Retention (log.retention.hours) │
│ │
│ Segment 1 [offset 0-999999] → Xóa sau 7 ngày │
│ Segment 2 [offset 1M-1.999M] → Xóa sau 7 ngày │
│ Segment 3 [offset 2M-...] → Active, đang ghi │
│ │
│ Dùng cho: Event log, audit trail │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ 2. Log Compaction (cleanup.policy=compact) │
│ │
│ Trước: key="user-1":v1, key="user-1":v2, key="user-1":v3│
│ Sau: key="user-1":v3 (chỉ giữ version mới nhất) │
│ │
│ Dùng cho: State store, CDC, config snapshot │
└─────────────────────────────────────────────────────┘4. Offset — Hệ Tọa Độ GPS Của Kafka
Partition 0:
Offset: 0 1 2 3 4 5 6 7 8 9
│ │ │ │ │ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼
[M0] [M1] [M2] [M3] [M4] [M5] [M6] [M7] [M8] [M9]
Consumer A (billing-group): đã đọc đến offset 6
Consumer B (analytics-group): đã đọc đến offset 9
Consumer C (audit-group): đã đọc đến offset 2Ba consumer đọc cùng một Partition nhưng hoàn toàn độc lập nhờ cơ chế offset riêng biệt. Đây là điều RabbitMQ không làm được — bởi vì trong RabbitMQ, message bị xóa sau khi một consumer đọc xong, khiến các consumer khác không thể replay lại dữ liệu.
Offset Được Lưu Ở Đâu?
Offset của mỗi Consumer Group được lưu trong một topic đặc biệt của Kafka: __consumer_offsets. Đây là một internal compacted topic với key là tổ hợp (groupId, topic, partition) và value là committed offset. Ngoài ra, cơ chế này còn cho phép Kafka tự động phục hồi offset sau khi Consumer restart mà không cần bất kỳ external storage nào. Tham khảo thêm cơ chế này trong tài liệu Consumer Configuration của Apache Kafka.
5. Broker và Controller — Nhạc Trưởng Của Cluster
Từ Zookeeper Đến KRaft (Kafka 3.3+)
Kiến trúc cũ (Zookeeper mode):
┌──────────────────┐ ┌──────────────────┐
│ Kafka Cluster │────►│ Zookeeper Cluster │
│ (3 Brokers) │ │ (3 nodes) │
└──────────────────┘ └──────────────────┘
Cần vận hành 2 cluster riêng biệt. Phức tạp!
Kiến trúc mới (KRaft mode):
┌────────────────────────────────────────────┐
│ Kafka Cluster │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Broker+ │ │ Broker+ │ │ Broker │ │
│ │Controller│ │Controller│ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
│ Controller đã tích hợp trong Broker! │
└────────────────────────────────────────────┘Sự chuyển đổi từ Zookeeper sang KRaft không chỉ đơn giản hóa vận hành mà còn cải thiện đáng kể thời gian recovery khi Broker gặp sự cố. Cụ thể, KRaft sử dụng Raft consensus algorithm — tương tự etcd trong Kubernetes — để bầu chọn Controller mà không cần hệ thống ngoài.
Vai Trò Của Controller
Controller (được bầu chọn qua Raft consensus) đảm nhận bốn nhiệm vụ cốt lõi. Về Partition Leader Election, Controller quyết định Broker nào làm Leader cho từng Partition. Về ISR Management, nó theo dõi danh sách In-Sync Replicas để đảm bảo durability. Thêm vào đó, Controller còn chịu trách nhiệm Broker Health Monitoring — phát hiện Broker chết và trigger re-election kịp thời. Cuối cùng, toàn bộ Topic/Partition Metadata được duy trì bởi Controller và phân phối đến tất cả Broker trong cluster.
6. Tổng Hợp — Đường Đi Của Một Message
Producer ghi message M vào topic "order_events", key="order-123"
Step 1: Routing
─────────────
hash("order-123") % 3 = 1 → Partition 1
Step 2: Leader Discovery
────────────────────────
Partition 1 Leader = Broker 2
Step 3: Network Write
──────────────────────
Producer → Broker 2 (TCP, port 9092)
Step 4: Disk Write
──────────────────
Broker 2 → append M vào /kafka/data/order_events-1/00000...45000.log
→ update .index với (offset=45001, bytePos=38291)
Step 5: Replication
───────────────────
Broker 2 (Leader) → Broker 1, Broker 3 (Followers pull data)
Step 6: ACK về Producer
────────────────────────
Khi đủ ISR xác nhận → ACK gửi về ProducerToàn bộ flow này diễn ra trong vài milliseconds trong điều kiện bình thường. Tuy nhiên, nếu một Broker trong ISR bị chậm, độ trễ ACK sẽ tăng theo — đây là lý do việc monitor ISR lag là chỉ số quan trọng nhất trong Kafka production. Để đi sâu hơn vào cơ chế Replication và ISR, hãy đọc Bài 3: Kafka Producer Nâng Cao — Throughput, Batching, Acks, Idempotent và Exactly-Once.
Kết Luận & Takeaway
Topic (tên logic)
└── Partition 0, 1, 2... (đơn vị scale-out)
└── Segment files (chia nhỏ để quản lý)
├── .log (raw message data, append-only)
├── .index (offset → byte position)
└── .timeindex (timestamp → offset)Ba điều bạn cần nhớ từ bài này: Đầu tiên, số Partition là mức độ song song tối đa của Consumer Group — chọn quá ít sẽ tạo bottleneck không thể khắc phục sau này. Thứ hai, Segment giúp Log Retention và Compaction hiệu quả vì Kafka xóa cả file thay vì xóa từng dòng riêng lẻ. Thứ ba, file .index là lý do Kafka tra cứu offset nhanh O(log n) dù có hàng tỷ message trên disk.
Bài tiếp theo: Bài 3: Kafka Producer Nâng Cao — Throughput, Batching, Acks, Idempotent và Exactly-Once.
💬 Câu hỏi thảo luận: Tại sao Kafka không cho phép giảm số Partition sau khi đã tạo? Gợi ý: nghĩ về
hash(key) % numPartitionsvà Consumer đang giữ offset ở Partition bị xóa. Thả đáp án bên dưới!