Lời Mở Đầu: Câu Hỏi Đúng Trước Khi Chọn Công Nghệ
Chào mừng bạn đến với series “Kafka 101 — Từ Zero đến Thực chiến Production”. Đây là series được thiết kế để đưa bạn từ người chưa biết gì về Kafka đến kỹ sư có thể thiết kế và vận hành một Kafka Cluster thực thụ ở môi trường doanh nghiệp. Nếu bạn chưa đọc phần giới thiệu series, hãy xem qua Tổng quan series Kafka 101 để nắm được lộ trình học tập.
Tuy nhiên, trước khi mở terminal để cài Kafka, tôi muốn hỏi bạn một câu quan trọng hơn: “Hệ thống của bạn đang gặp vấn đề gì?” Đây không phải câu hỏi mang tính giới thiệu — đây là cách một Architect tư duy. Công nghệ chỉ là công cụ, và do đó mỗi công cụ giải quyết một bài toán cụ thể. Vậy Kafka giải quyết bài toán gì? Hãy cùng mổ xẻ từ nền tảng.
1. Bức Tranh Toàn Cảnh: Hệ Thống Đồng Bộ Hoạt Động Như Thế Nào?
Hãy xây dựng một nền tảng E-commerce đơn giản. Khi người dùng nhấn “Đặt hàng”, luồng xử lý tiêu biểu với REST API trông như sau:
Client Request
│
▼
┌──────────────┐
│ Order Service│ ──(1) POST /inventory/reserve──► Inventory Service
│ │ ◄──────── 200 OK ──────────────┘
│ │
│ │ ──(2) POST /payment/charge────► Payment Service
│ │ ◄──────── 200 OK ──────────────┘
│ │
│ │ ──(3) POST /notification/send─► Notification Service
│ │ ◄──────── 200 OK ──────────────┘
└──────────────┘
│
▼
200 OK ──► ClientMô hình này hoạt động tốt khi bạn có vài trăm người dùng đồng thời. Tuy nhiên, khi Flash Sale nổ ra với 10,000 người đồng thời nhấn “Mua”, kiến trúc này bộc lộ các điểm gãy cực kỳ nguy hiểm mà chúng ta sẽ phân tích ngay sau đây.
2. Giải Phẫu “Thảm Họa” — 4 Điểm Gãy Chết Người Của REST Đồng Bộ
2.1 Thread Blocking Cascade — Hiệu Ứng Domino
Mỗi request HTTP đến Order Service cần chiếm một thread từ thread pool để chờ response từ service phía sau. Cụ thể, thread đó sẽ bị “đóng băng” (block) cho đến khi có response trả về — và đây chính là vấn đề cốt lõi.
Thread Pool của Order Service (giả sử 200 threads)
╔══════════════════════════════════════════════╗
║ Thread-001: Đang chờ Notification Service... ║ (blocked - 2.3s)
║ Thread-002: Đang chờ Notification Service... ║ (blocked - 1.8s)
║ Thread-003: Đang chờ Payment Service......... ║ (blocked - 0.5s)
║ ... ║
║ Thread-200: Đang chờ Notification Service... ║ (blocked - 3.1s)
╚══════════════════════════════════════════════╝
↑
Thread-201: Request mới ── XẾP HÀNG, TIMEOUT → 503Notification Service gửi email qua SMTP server bên thứ 3 như SendGrid hay Mailchimp. Nếu SMTP server phản hồi chậm 3 giây thay vì 100ms, toàn bộ 200 threads của Order Service bị chiếm giữ bởi các request đang chờ. Kết quả là Order Service sập — không phải vì nó bị lỗi logic, mà vì một service phụ trợ gửi email bị chậm. Đây chính là hiệu ứng Domino kinh điển trong kiến trúc đồng bộ.
2.2 Connection Pool Exhaustion — Cạn Kiệt Tài Nguyên
Connection Pool (Order → Notification): Max 50 connections
├── 50 connections: Đang mở, tất cả bị block chờ SMTP
└── Request thứ 51: SQLException: Connection pool exhaustedKhi Connection Pool cạn kiệt, Order Service không thể mở kết nối mới đến bất kỳ upstream nào — kể cả Database để lưu đơn hàng. Ngoài ra, vấn đề này còn lan rộng sang các service khác trong cùng cluster, khiến chúng cũng bắt đầu cạn tài nguyên theo cơ chế tương tự, tạo thành một vòng xoáy sụp đổ khó kiểm soát.
2.3 Distributed Transaction — Cơn Ác Mộng Rollback
Xét tình huống thực tế: Inventory đã trừ kho (commit thành công), nhưng Payment Service sập giữa chừng. Lúc này bạn buộc phải gọi lại Inventory để hoàn kho — trong khi Inventory Service cũng đang chịu tải nặng. Nếu lần gọi rollback này cũng fail, dữ liệu trở nên không nhất quán mãi mãi và không có cách tự động phục hồi.
Giải pháp Two-Phase Commit (2PC) qua HTTP tồn tại nhưng có chi phí khổng lồ:
| Vấn đề | 2PC | Saga Pattern |
|---|---|---|
| Blocking | Toàn hệ thống block trong phase 2 | Không block |
| Độ phức tạp | Coordinator-based, single point of failure | Phức tạp logic |
| Performance | Rất chậm ở tải cao | Tốt hơn |
| Rollback | Atomic nhưng slow | Eventual consistency |
Tuy nhiên, cả hai giải pháp trên đều không giải quyết triệt để vấn đề khi áp dụng trong môi trường REST đồng bộ thuần túy. Đó là lý do Saga Pattern kết hợp Kafka lại trở thành tiêu chuẩn trong kiến trúc microservices hiện đại.
2.4 Coupling Ngầm — Sự Phụ Thuộc Vô Hình
Khi Order Service gọi thẳng vào Notification Service, chúng trở nên tight-coupled không chỉ về data mà còn về nhiều chiều khác nhau. Về mặt runtime, Order Service chỉ healthy khi tất cả downstream service cùng healthy. Thêm vào đó, mỗi khi thay đổi API của Notification Service, toàn bộ Order Service buộc phải test lại từ đầu. Đặc biệt, việc scale Notification Service cũng không giúp ích gì cho Order Service đang bị block — đây là điểm mà nhiều team không nhận ra cho đến khi đã quá muộn.
3. Kafka Và Triết Lý Event-Driven — Tư Duy Thay Đổi Mọi Thứ
Kafka không chỉ là một công cụ message queue. Thực ra, nó đòi hỏi bạn thay đổi căn bản cách tư duy về hệ thống — từ việc ra lệnh sang việc thông báo sự kiện.
Từ “Ra Lệnh” Sang “Thông Báo Sự Kiện”
| Kiến trúc | Tư duy | Ví dụ |
|---|---|---|
| REST Sync | Command: “Inventory, trừ kho item-789 đi!” | Order Service biết và điều khiển Inventory |
| Event-Driven | Event: “Đơn hàng #1234 vừa được tạo.” | Order Service không quan tâm ai làm gì tiếp theo |
Sự thay đổi tư duy này nghe đơn giản nhưng thực ra rất sâu sắc. Khi Order Service phát ra event thay vì ra lệnh trực tiếp, nó không còn phụ thuộc vào sự tồn tại hay trạng thái của bất kỳ service nào khác. Do đó, toàn bộ chain of failure được cắt đứt ngay tại nguồn.
Luồng Xử Lý Với Kafka
Client Order Service Kafka Broker
│ │ │
│── POST /orders ────────►│ │
│ │──PRODUCE ───────────►│
│ │ "ORDER_CREATED" │ (≤ 10ms)
│◄─────── 200 OK ─────────│ │
│ │ │
│ │ ┌────────┘
│ │ CONSUME│ Inventory Service
│ │ │ Payment Service
│ │ │ Notification Service
│ │ │ Analytics Service
│ │ └─── (Tự xử lý theo tốc độ của mình)Order Service giờ đây chỉ làm đúng 2 việc: lưu đơn hàng vào DB và ghi event ORDER_CREATED vào Kafka. Sau đó nó trả về 200 OK trong < 10ms mà không cần biết, không cần quan tâm Notification Service đang sập hay Inventory đang lag. Đó là Decoupling thực sự — và đó cũng là lý do Kafka được các công ty như LinkedIn, Netflix, Uber áp dụng ở quy mô hàng tỷ events mỗi ngày.
4. Kafka Không Phải RabbitMQ — Đây Là Sự Khác Biệt Quyết Định
Đây là câu hỏi tôi hay gặp nhất trong các buổi phỏng vấn Senior Engineer:
“Kafka và RabbitMQ khác nhau thế nào? Khi nào dùng cái nào?”

┌─────────────────────────────────────────────────────────┐
│ RabbitMQ: Smart Broker │
│ │
│ Producer ──► [Queue] ──► Consumer (ACK) ──► DELETE ✗ │
│ │
│ • Broker theo dõi trạng thái từng message │
│ • Message xóa sau khi Consumer ACK │
│ • Thiết kế cho Point-to-Point, Request-Reply │
│ • Tối ưu cho: Task Queue, Job Processing │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ Apache Kafka: Distributed Log │
│ │
│ Producer ──► [Partition Log] ──► Consumer A │
│ │ ──► Consumer B │
│ │ ──► Consumer C (sau 7 ngày)│
│ RETAINED │
│ │
│ • Broker chỉ lưu log, Consumer tự track offset │
│ • Message KHÔNG xóa sau khi đọc │
│ • Thiết kế cho Event Streaming, Data Pipeline │
│ • Tối ưu cho: Real-time processing, Event Sourcing │
└─────────────────────────────────────────────────────────┘| Tiêu chí | RabbitMQ | Apache Kafka |
|---|---|---|
| Mô hình lưu trữ | Message bị xóa sau ACK | Log append-only, retention theo thời gian |
| Thứ tự message | Per-queue | Per-partition (đảm bảo tuyệt đối) |
| Replay dữ liệu | ❌ Không thể | ✅ Có thể rewind về bất kỳ offset nào |
| Throughput | ~50k msg/s | ~1M+ msg/s per partition |
| Use case | Job queue, task distribution | Event streaming, data pipeline, CDC |
| Consumer model | Push | Pull |
| Routing | Flexible (Exchanges, Bindings) | Topic-based |
Ngoài ra, một điểm khác biệt quan trọng mà ít tài liệu đề cập là khả năng Consumer Group Isolation của Kafka: nhiều Consumer Group có thể đọc cùng một topic một cách hoàn toàn độc lập, trong khi mỗi group tự duy trì offset riêng. Tính năng này không có trong RabbitMQ và đây là yếu tố quyết định khi bạn cần nhiều team độc lập cùng consume một luồng dữ liệu.
Chọn Đúng Công Cụ Cho Đúng Bài Toán
Khi nào dùng RabbitMQ? Nên chọn RabbitMQ cho email queue, background job, và workflow với logic routing phức tạp cần Exchanges/Bindings.
Khi nào dùng Kafka? Hãy chọn Kafka cho event streaming, real-time analytics, audit log, CDC (Change Data Capture), và microservices integration ở quy mô lớn. Tham khảo thêm tài liệu chính thức của Apache Kafka để hiểu sâu hơn về các use case được khuyến nghị.
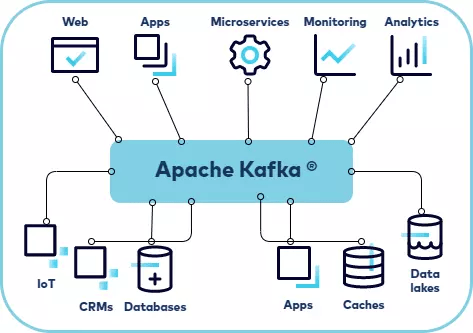
5. Kafka Trong Bức Tranh Hệ Thống Lớn
┌──────────────────────────────────────────────────────────────────┐
│ KAFKA CLUSTER (Event Backbone) │
│ │
│ Topics: order-events │ payment-events │ inventory-events │ ... │
└────────────────────────────────┬─────────────────────────────────┘
▲ Produce │ Consume
│ │
┌─────────────────┐ ┌────────▼────────────────────────────────┐
│ Microservices │ │ Consumers │
│ ─ Order Svc │ │ ─ Billing Service (xử lý thanh toán) │
│ ─ Payment Svc │ │ ─ Notification Service (gửi email/SMS) │
│ ─ Inventory Svc │ │ ─ Analytics Engine (Kafka Streams) │
│ ─ Shipping Svc │ │ ─ Data Warehouse Connector (Kafka Connect│
└─────────────────┘ │ ─ Fraud Detection (ML Model) │
└─────────────────────────────────────────┘Kafka Như Xương Sống Dữ Liệu
Nhờ kiến trúc này, Kafka trở thành xương sống dữ liệu (Data Backbone) của toàn hệ thống. Mỗi thay đổi trạng thái nghiệp vụ đều được phát ra dưới dạng event — bất kỳ service nào cần đều tự đăng ký đọc mà không cần phối hợp với producer.
Lợi Ích Về Tổ Chức Engineering
Hơn nữa, khi một service mới cần onboard vào hệ thống, team đó chỉ cần subscribe thêm một topic mà không cần chạm vào bất kỳ service hiện tại nào. Đây là điểm mạnh về mặt tổ chức engineering mà REST/gRPC không thể cung cấp. Để hiểu cách các component bên trong Kafka vận hành, hãy đọc tiếp Bài 2: Giải Phẫu Kiến Trúc Kafka — Broker, Topic, Partition, Segment, Offset Từ Lý Thuyết Đến Ổ Cứng.
6. Khi Nào KHÔNG Dùng Kafka?
Là một Architect, biết khi nào không nên dùng một công nghệ quan trọng không kém biết khi nào nên dùng. Đây là điều mà nhiều tài liệu bỏ qua nhưng lại rất thiết thực trong công việc hàng ngày.
Những Trường Hợp Không Phù Hợp
Trường hợp đầu tiên cần tránh là dự án nhỏ hoặc Monolith: chi phí vận hành Kafka Cluster — bao gồm broker, ZooKeeper/KRaft, monitoring stack — quá lớn so với lợi ích đem lại. Thay vào đó, Redis Pub/Sub hoặc RabbitMQ là lựa chọn hợp lý hơn nhiều.
Tiếp theo, nếu hệ thống yêu cầu Request-Reply đồng bộ — chẳng hạn check tồn kho trước khi cho phép thêm vào giỏ hàng — thì REST hoặc gRPC phù hợp hơn, vì Kafka không được thiết kế cho các luồng cần kết quả tức thì.
Ngoài ra, Kafka cũng không phải công cụ lý tưởng cho bài toán low-latency single message: dù throughput rất cao, latency cho từng message đơn lẻ lại không phải điểm mạnh của nó.
Những Trường Hợp Nên Dùng Kafka
Ngược lại, Kafka tỏa sáng khi hệ thống cần xử lý hơn 10,000 events/giây, cần nhiều consumer cùng đọc một stream dữ liệu, hoặc cần replay dữ liệu lịch sử cho audit và reprocessing. Bên cạnh đó, nếu bạn đang xây dựng pipeline ETL real-time hay cần decoupling hoàn toàn giữa các microservices trong một hệ thống phân tán quy mô lớn, Kafka là lựa chọn hàng đầu.
Kết Luận & Takeaway
| Vấn đề REST Sync | Giải pháp Kafka Event-Driven |
|---|---|
| Thread blocking | Producer trả về ngay, không chờ |
| Cascade failure | Service lỗi không ảnh hưởng chain |
| Distributed transaction | Eventual consistency qua Saga |
| Tight coupling | Loose coupling qua event contract |
| Không thể replay | Retention + offset rewind |
Bài học cốt lõi: Kafka không phải “RabbitMQ mạnh hơn”. Thực ra, đây là một paradigm shift hoàn toàn — từ Command-Driven sang Event-Driven. Khi bạn nội tâm hóa được tư duy này, thiết kế hệ thống của bạn sẽ thay đổi theo hướng bền vững và dễ scale hơn rất nhiều.
Bài tiếp theo: Bài 2: Giải Phẫu Kiến Trúc Kafka — Broker, Topic, Partition, Segment, Offset Từ Lý Thuyết Đến Ổ Cứng. Chúng ta sẽ đi sâu vào cơ chế bên trong giúp Kafka lưu hàng tỷ events trên đĩa cứng mà vẫn cực nhanh.
💬 Góc thảo luận: Trong hệ thống của bạn, đã bao giờ một service phụ trợ như gửi SMS hay email làm “kéo sập” cả luồng chính chưa? Bạn đã giải quyết nó như thế nào trước khi biết đến Kafka? Chia sẻ kinh nghiệm bên dưới nhé!