Lời Mở Đầu: Nghịch Lý Lớn Nhất Của Kafka
Trên thực tế, đây là một câu hỏi tôi thường đặt ra trong các buổi tech talk:
“Kafka ghi dữ liệu ra ổ cứng. MySQL cũng ghi ra ổ cứng. Nhưng Kafka đẩy được 1 triệu message/giây trong khi MySQL thường maxout ở vài nghìn writes/giây. Tại sao?”
Tuy nhiên, câu trả lời không nằm ở phần cứng hay RAM. Nó nằm ở cách Kafka tận dụng tối đa các tính năng của Linux kernel theo cách mà hầu hết ứng dụng không làm.
Xem thêm trong series:
- Kafka HA — Replication, ISR và Leader Election (Bài trước)
- Setup Kafka Cluster — Docker Compose và KRaft (Bài tiếp)
1. Sequential I/O — Biến Điểm Yếu Của Đĩa Thành Sức Mạnh
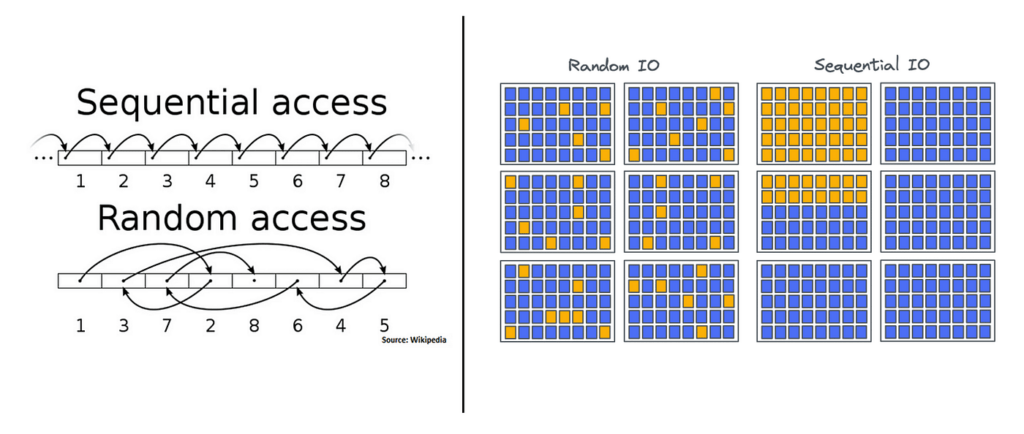
1.1 Random Access vs Sequential Access
Ổ HDD (Hard Disk Drive) — Vật lý học quyết định tất cả:
Random Access: Ghi vào địa chỉ ngẫu nhiên
┌────────────────────────────────────────────┐
│ Write to sector 1234 → Head move: 8ms │
│ Write to sector 78901 → Head move: 12ms │
│ Write to sector 345 → Head move: 9ms │
│ Throughput: ~100-150 IOPS │
└────────────────────────────────────────────┘
Sequential Access: Ghi nối tiếp
┌────────────────────────────────────────────┐
│ Write to sector 1000 │
│ Write to sector 1001 → Head KHÔNG di │
│ Write to sector 1002 chuyển │
│ Throughput: ~100-200 MB/s │
└────────────────────────────────────────────┘Benchmark thực tế:
| Loại truy cập | HDD | SSD NVMe |
|---|---|---|
| Random 4K Write | ~100 IOPS = 0.4 MB/s | ~500K IOPS = 2 GB/s |
| Sequential Write | ~150 MB/s | ~3 GB/s |
| Tỉ lệ Seq/Rand | 375x | 6x |
HDD: Sequential nhanh hơn Random 375 lần. Do đó, MySQL phải random access để update B-tree index. Kafka chỉ cần append-only sequential → Kafka win!
1.2 Kafka Append-Only Log — Thiết Kế Sinh Ra Để Nhanh
MySQL UPDATE một record:
1. B-tree traversal (random read): tìm page
2. Read page vào buffer pool (random read)
3. Modify page in memory
4. Write-Ahead Log (sequential write) ✓
5. Flush dirty page về disk (random write) ✗
Total: Nhiều random I/O
Kafka WRITE một message:
1. Append vào đuôi file .log (sequential write) ✓
2. Update .index sparse index (sequential write) ✓
Total: Chỉ sequential I/OĐây không phải Kafka mạnh hơn MySQL. Nói cách khác, đây là sự khác biệt của immutable log vs mutable state — hai paradigm hoàn toàn khác nhau.
2. OS Page Cache — Kafka Mượn Bộ Nhớ Của Linux
2.1 Page Cache Là Gì?
Khi bạn đọc file trên Linux, OS không đọc thẳng từ disk mỗi lần. Thay vào đó, OS sẽ cache nội dung file trong RAM (Page Cache). Lần đọc tiếp theo → served từ RAM, không chạm disk.
Linux Memory Map (Server 64GB RAM):
┌────────────────────────────────────────┐
│ Application Memory (JVM Heap): 6GB │
│ OS Page Cache: 56GB │ ← Kafka tận dụng đây!
│ OS Overhead: 2GB │
└────────────────────────────────────────┘2.2 Kafka Không Dùng JVM Heap Để Cache Data
Trên thực tế, đây là thiết kế thiên tài của Kafka founders:
Ứng dụng Java thông thường:
Data → JVM Heap (Java objects)
→ Garbage Collection phải scan toàn bộ Heap
→ GC Pause: từ vài ms đến vài giây (Stop-the-world)
→ Với 32GB Heap → GC Pause có thể lên đến 30+ giây!
Kafka:
Data → Write to disk (OS Page Cache trong suốt quá trình)
→ Kafka JVM Heap chỉ cần 4-6GB (cho metadata, connection handling)
→ Không có GC Pause lớn!
→ Linux quản lý 56GB Page Cache hiệu quả hơn JVM rất nhiều2.3 Write Path Với Page Cache
Producer → Kafka Broker
Bước 1: Kafka nhận bytes từ network socket
Bước 2: write() syscall → OS copy bytes vào Page Cache
(Không đi xuống disk ngay!)
Bước 3: Kafka trả ACK về Producer
(Sau khi data an toàn trong Page Cache + ISR replicated)
Bước 4: OS tự flush Page Cache xuống disk sau
(Async, theo dirty_expire_centisecs cấu hình)
Độ trễ: Kafka chỉ chờ Page Cache write (~μs) + network replication
Không chờ disk write (~ms)2.4 Read Path Với Page Cache — The Magic
Consumer (thường đọc recent data):
Case 1: Data vừa ghi (còn trong Page Cache)
Consumer read() → OS Page Cache HIT → Return ngay từ RAM
Latency: < 1ms, không chạm disk!
Case 2: Data cũ (đã bị evict khỏi Page Cache)
Consumer read() → Page Cache MISS → OS fetch từ disk → Cache → Return
Latency: 5-10ms (SSD) hoặc 10-50ms (HDD)
Thực tế: Consumer thường đọc recent data (lag thấp)
→ Gần như 100% Page Cache HIT
→ Consumer đọc từ RAM tốc độ!3. Zero-Copy — Kỹ Thuật Tiết Kiệm CPU 50%
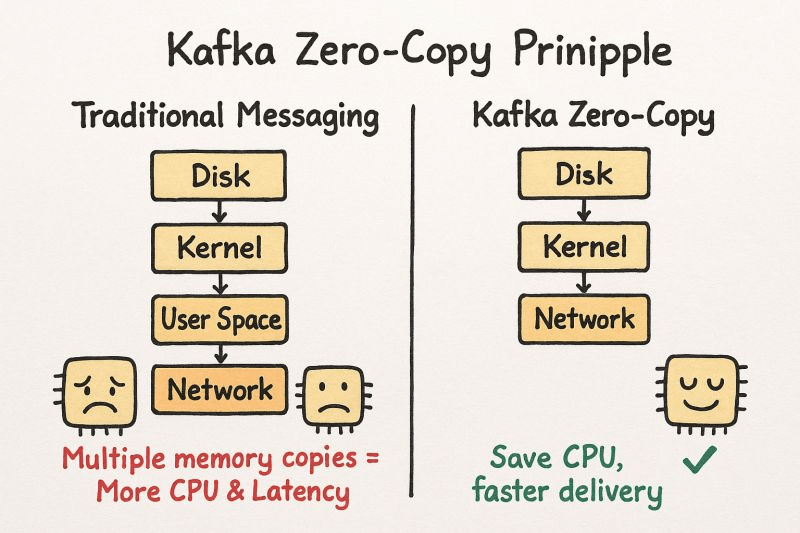
3.1 Luồng Truyền Data Thông Thường (Không Zero-Copy)
Disk → Broker App → Consumer
Bước 1: read() syscall → OS copy data từ disk vào Page Cache [kernel space]
Bước 2: OS copy data từ Page Cache → App Buffer (Kafka JVM) [user space]
← Context switch: kernel → user
Bước 3: App copy data từ App Buffer → Socket Buffer [user space]
Bước 4: OS copy data từ Socket Buffer → NIC Buffer [kernel space]
← Context switch: user → kernel
Tổng cộng:
4 lần copy (2 trong kernel, 2 trong user space)
2 lần context switch CPU (tốn kém!)
CPU usage: cao3.2 Zero-Copy Với sendfile() Syscall
Disk → Consumer (via Kafka) với Zero-Copy
Bước 1: Kafka gọi FileChannel.transferTo() (Java NIO)
→ Dịch xuống sendfile() syscall của Linux
Bước 2: OS thực hiện DMA (Direct Memory Access):
Page Cache → NIC Buffer (TRỰC TIẾP, không qua App!)
Tổng cộng:
2 lần copy (cả 2 trong kernel, app không tham gia)
0 lần context switch thêm
CPU usage: giảm 50%+So sánh trực quan:
Traditional:
Disk ──→ [Kernel Buffer] ──→ [App Buffer] ──→ [Socket Buffer] ──→ NIC
↑ ↑
Context Switch Context Switch
Zero-Copy (sendfile):
Disk ──→ [Kernel Buffer] ─────────────────────────────────────→ NIC
(DMA Transfer, không qua App)3.3 Tác Động Thực Tế Của Zero-Copy
Benchmark: Gửi 1GB file từ disk ra network
Traditional copy:
- CPU time: ~3.2 giây
- Throughput: ~312 MB/s
- CPU usage: 100% một core
Zero-copy (sendfile):
- CPU time: ~0.8 giây
- Throughput: ~1.25 GB/s (4x nhanh hơn!)
- CPU usage: ~15%Điều kiện Zero-Copy hoạt động: Data phải đi trực tiếp từ disk/Page Cache ra network mà KHÔNG bị transform. Đây là lý do Kafka không mã hóa data ở tầng Broker (end-to-end encryption phải được xử lý ở Producer/Consumer). Nếu Broker phải decrypt/re-encrypt, Zero-Copy bị bypass.
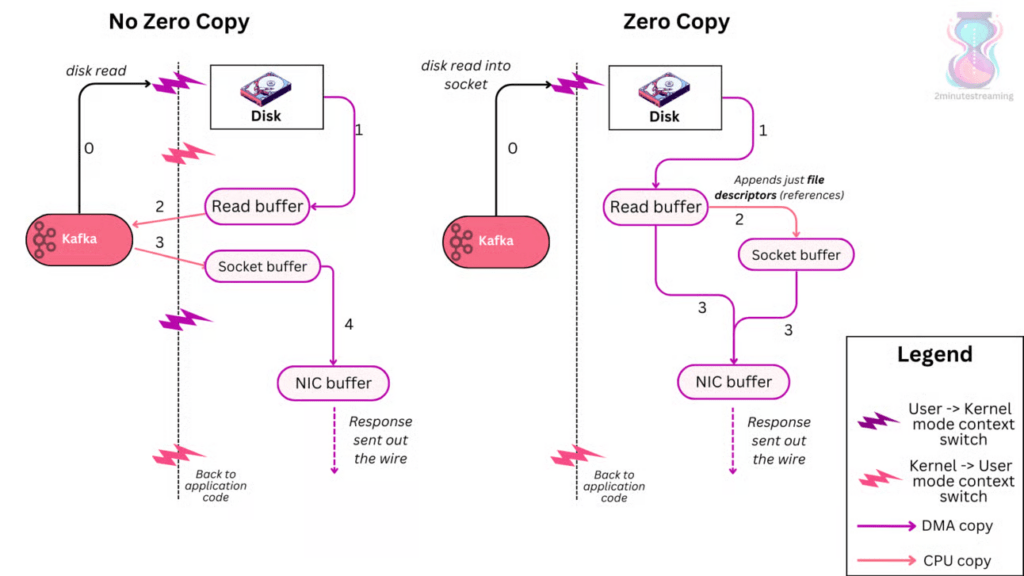
4. Tổng Hợp — Vì Sao Kafka Nhanh Như Vậy?
┌─────────────────────────────────────────────────────────────────┐
│ Kafka Performance Stack │
│ │
│ 1. Sequential I/O → Tận dụng max throughput của disk │
│ 2. OS Page Cache → Đọc/ghi từ RAM, không từ disk │
│ 3. Zero-copy (sendfile) → Giảm 50% CPU khi gửi data ra mạng │
│ 4. Batching + Compression→ Giảm network I/O │
│ 5. Sparse Index → O(log n) lookup, không scan toàn bộ │
│ 6. Partition parallelism → Linear scale-out │
└─────────────────────────────────────────────────────────────────┘5. Hướng Dẫn Chọn Hardware Cho Kafka Production
Dựa trên những cơ chế trên, ta rút ra được “công thức hardware” cho Kafka:
5.1 RAM — Quan Trọng Nhất
RAM = JVM Heap + OS Page Cache + OS overhead
Khuyến nghị:
JVM Heap: 6GB (đừng dùng nhiều hơn, GC sẽ lag)
Page Cache: ≥ 32GB (nhiều hơn càng tốt)
OS overhead: 2GB
→ Tổng tối thiểu: 64GB RAM
→ Lý tưởng: 128GB+ RAM cho production cluster5.2 Disk — Quan Trọng Thứ Hai
Sequential throughput là điều quan trọng, không phải IOPS random.
Lựa chọn tốt:
- SSD NVMe: Sequential write 3 GB/s, latency thấp → Tốt nhất
- SSD SATA: Sequential write 500 MB/s → Ổn cho trung bình
- HDD 7200rpm: Sequential write 150 MB/s → Đủ dùng, rẻ
KHÔNG cần:
- NVMe U.2 đắt tiền (overkill, Kafka không cần random IOPS cao)
Số lượng disk:
- Nhiều disk riêng biệt tốt hơn 1 disk to (JBOD, không RAID)
- Kafka tự replicate, không cần RAID1/5
- Cấu hình: log.dirs=/mnt/disk1,/mnt/disk2,/mnt/disk35.3 Network
Kafka là I/O bound về network (replication + producer/consumer):
Minimum: 1 Gbps NIC
Production: 10 Gbps NIC (nếu replication factor=3, network traffic x3)
High-end: 25 Gbps hoặc bonding
Tính toán network bandwidth:
Write throughput: 500 MB/s
Replication factor: 3
→ Total outbound: 500 × 3 = 1.5 GB/s = 12 Gbps
→ Cần NIC 25 Gbps!5.4 CPU
Kafka là I/O bound, không phải CPU bound.
CPU chỉ cần cho: SSL/TLS encryption, data compression, metadata.
Khuyến nghị:
- 16-32 cores (cho production)
- Không cần overclock hay high-end CPU
- Tiết kiệm chi phí: chọn RAM + Network + Disk tốt hơn là CPU mạnh6. Linux OS Tuning Cho Kafka
# /etc/sysctl.conf
# Page Cache: Giảm swappiness (không để Linux swap Page Cache ra disk)
vm.swappiness = 1
# Page Cache: Tăng ngưỡng dirty page trước khi flush
vm.dirty_background_ratio = 5 # Flush khi 5% RAM là dirty pages
vm.dirty_ratio = 60 # Block writes khi 60% RAM là dirty
# Network: Tăng socket buffer
net.core.rmem_max = 134217728 # 128MB receive buffer
net.core.wmem_max = 134217728 # 128MB send buffer
net.ipv4.tcp_rmem = 4096 65536 134217728
net.ipv4.tcp_wmem = 4096 65536 134217728
# File descriptors: Kafka mở rất nhiều file
# /etc/security/limits.conf
kafka soft nofile 100000
kafka hard nofile 100000
# Filesystem: Dùng XFS, mount với noatime
# /etc/fstab
/dev/nvme0n1 /kafka/data xfs defaults,noatime 0 0Kết Luận & Takeaway
Kafka nhanh = Sequential I/O + Page Cache + Zero-copy + Batching
Hardware cho Kafka (ưu tiên):
1. RAM (64-128GB+) → Page Cache lớn hơn = ít hit disk hơn
2. Network (10Gbps+) → Replication không bottleneck
3. Disk (SSD hoặc nhiều HDD) → Sequential throughput cao
4. CPU (bình thường là đủ)
OS Tuning bắt buộc:
vm.swappiness=1, nofile=100000, filesystem=XFS/EXT4+noatimeXem thêm trong series:
- Kafka HA — Replication, ISR và Leader Election (Bài trước)
- Setup Kafka Cluster — Docker Compose và KRaft (Bài tiếp)
💬 Câu hỏi thực tế: Nếu deploy Kafka trên Kubernetes với Persistent Volume từ AWS EBS (Network Attached Storage), Zero-Copy có còn hoạt động không? Và Sequential I/O bị ảnh hưởng thế nào? Đây là câu hỏi hay trong phỏng vấn Infra/Platform Engineering!