Lời Mở Đầu: Tại Sao “Không Bao Giờ Mất Data” Là Bài Toán Khó?
Trên thực tế, trong môi trường cloud production, các sự cố phần cứng không phải ngoại lệ — chúng là tất yếu. AWS SLA cho EC2 là 99.99% uptime, nghĩa là có thể downtime ~52 phút/năm. Một ổ SSD NVMe có tỷ lệ lỗi ~0.5-1% mỗi năm. Với cluster 50 nodes, bạn có thể gặp ổ đĩa hỏng mỗi 1-2 tháng.
Vì vậy, câu hỏi đặt ra là: Khi server bị tắt đột ngột, ổ đĩa cháy, network bị partition — data trong Kafka có mất không?
Câu trả lời hoàn toàn phụ thuộc vào cách bạn cấu hình Replication.
Xem thêm trong series:
- Kafka Consumer — Group, Rebalance và Offset (Bài trước)
- Hiệu Năng Kafka: Zero-Copy, Page Cache và I/O (Bài tiếp)
1. Mô Hình Leader-Follower — Nền Tảng Của HA
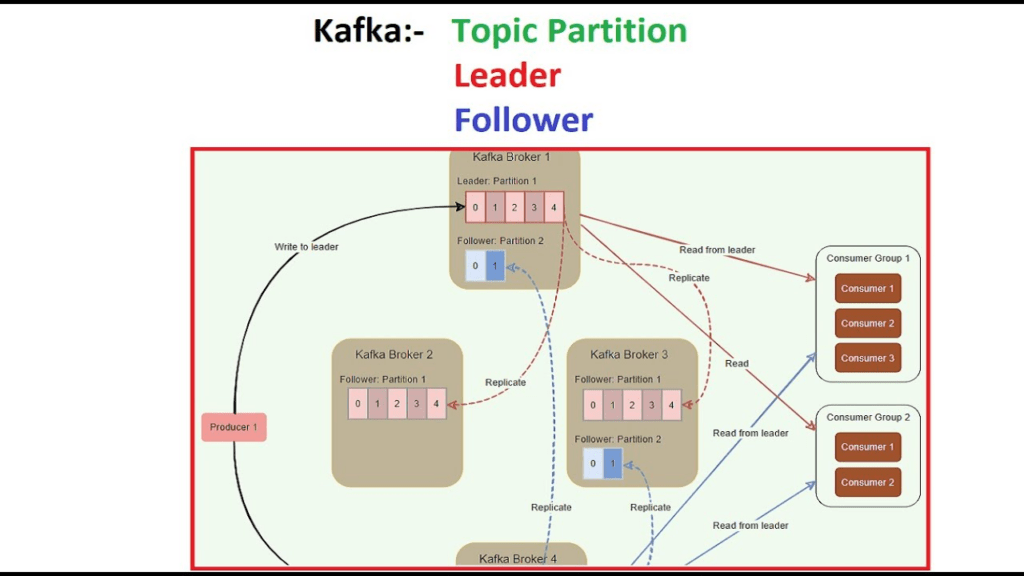
1.1 Replication Factor: Quyết Định Số Phận Data
Tạo Topic với Replication Factor = 3:
$ kafka-topics.sh --create \
--topic payment-events \
--partitions 3 \
--replication-factor 3 \
--bootstrap-server localhost:9092
Kafka sẽ tạo:
payment-events-P0: Leader→Broker1, Follower→Broker2, Follower→Broker3
payment-events-P1: Leader→Broker2, Follower→Broker3, Follower→Broker1
payment-events-P2: Leader→Broker3, Follower→Broker1, Follower→Broker2
→ Mỗi Broker có 1 Leader và 2 Follower (phân tán đều)
→ Nếu Broker1 chết, P0 vẫn sống nhờ Broker2 hoặc Broker3 lên thay1.2 Quy Tắc Đọc/Ghi — Chỉ Leader
Producer ──WRITE──► Leader (Broker 1)
Consumer ──READ───► Leader (Broker 1)
Follower (Broker 2) ──FETCH (pull)──► Leader
Follower (Broker 3) ──FETCH (pull)──► Leader
→ Kafka KHÔNG cho đọc từ Follower (mặc định)
(Khác với Cassandra, MongoDB read preference có thể từ replica)
Lý do: Đảm bảo read-your-writes consistency.
Nếu đọc từ Follower đang lag → đọc data cũ!
Ngoại lệ: Từ Kafka 2.4+, cho phép Consumer đọc từ Follower trong
cùng Availability Zone để giảm cross-AZ bandwidth cost
(cần cấu hình: replica.selector.class)2. ISR (In-Sync Replicas) — Đội Cận Vệ Tinh Nhuệ
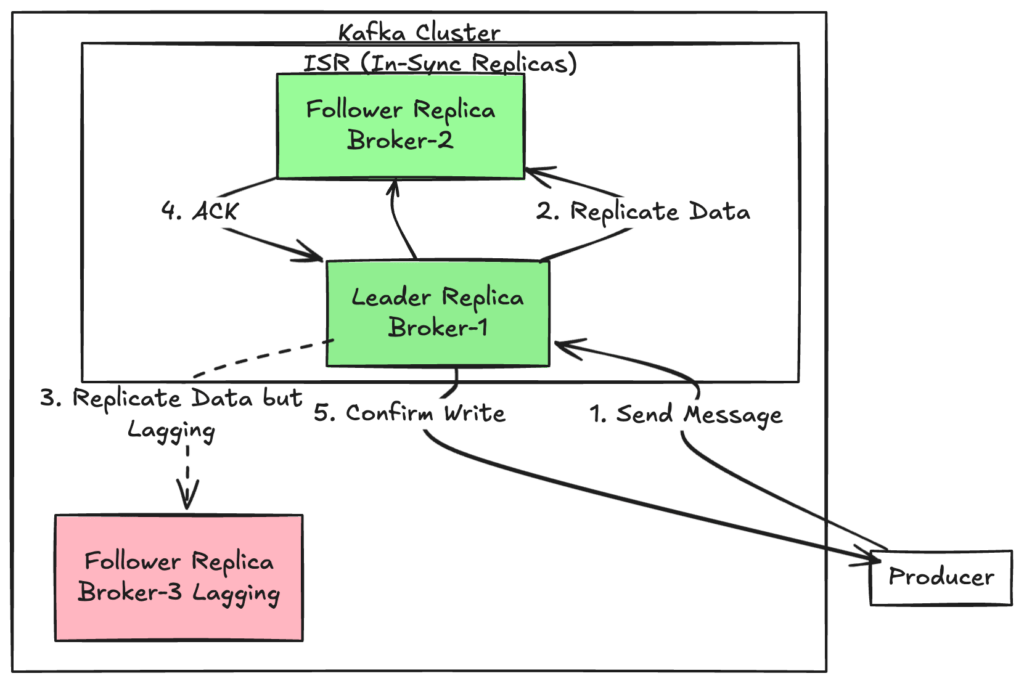
2.1 ISR Là Gì?
Về bản chất, ISR là danh sách các Replica (bao gồm Leader) đang theo kịp Leader về mặt replication. Cụ thể, điều kiện để ở trong ISR:
Follower phải fetch dữ liệu từ Leader trong vòng:
replica.lag.time.max.ms = 30000 (30 giây, mặc định)
Nếu Follower không fetch trong 30 giây → BỊ LOẠI khỏi ISR
Broker 1 (Leader): P0, ISR=[1,2,3]
↓ Broker 3 bị chậm mạng 40 giây
Broker 1 (Leader): P0, ISR=[1,2] ← Broker 3 bị loại!
↓ Mạng Broker 3 phục hồi, bắt kịp
Broker 1 (Leader): P0, ISR=[1,2,3] ← Broker 3 được thêm lại2.2 Leader Election Từ ISR
Kịch bản: Broker 1 (Leader) bị cháy nguồn
Trước sự cố:
P0: Leader=Broker1, ISR=[Broker1, Broker2, Broker3]
Kafka Controller phát hiện Broker1 chết (qua KRaft consensus):
Controller chọn Broker trong ISR làm Leader mới
→ Broker2 được chọn (theo nhiều tiêu chí: preferred leader, load)
Sau sự cố:
P0: Leader=Broker2, ISR=[Broker2, Broker3]
Time to failover: ~10-30 giây (phụ thuộc session.timeout.ms)
Data loss: ZERO (vì Broker2 đã có tất cả data đã committed)2.3 Trường Hợp ISR Rỗng — Kafka Chọn Gì?
Kịch bản tệ nhất: Data center cắt điện, tất cả ISR chết
Option 1: Đợi (mặc định)
unclean.leader.election.enable=false
→ Partition ngừng hoạt động, không đọc/ghi được
→ Đảm bảo ZERO data loss khi ISR phục hồi
→ Phù hợp: Banking, Financial, Medical
Option 2: Bầu Follower ngoài ISR làm Leader
unclean.leader.election.enable=true
→ Hệ thống tiếp tục hoạt động
→ Follower lag có thể thiếu vài nghìn message → DATA LOSS!
→ Phù hợp: Metrics, Logs (chấp nhận mất một ít)3. LEO và HW — Cơ Chế Đảm Bảo An Toàn Khi Đọc
3.1 LEO (Log End Offset)
LEO = Offset của message MỚI NHẤT đã ghi vào ổ đĩa của từng replica
Leader (Broker1): LEO = 100 (đã ghi 100 message)
Follower (Broker2): LEO = 98 (đang sync, còn thiếu 2 message)
Follower (Broker3): LEO = 97 (lag hơn, thiếu 3 message)3.2 HW (High Watermark) — Ranh Giới An Toàn Để Đọc
High Watermark = min(LEO của tất cả ISR members)
= min(100, 98, 97)
= 97
Consumer CHỈ ĐƯỢC ĐỌC offset < HW = 97
Lý do: Message ở offset 98, 99, 100 có thể chưa được replicate
đầy đủ. Nếu Leader crash ngay lúc này, và Broker3 (LEO=97)
lên làm Leader → offset 98,99,100 BIẾN MẤT.
Nhưng nếu Consumer đã đọc offset 99 → Consumer nhớ "đã xử lý"
nhưng data đó không còn trong Kafka → INCONSISTENCY.
→ HW đảm bảo: "Cái Consumer đọc, chắc chắn tồn tại trong tất cả ISR"3.3 Sơ Đồ Hoàn Chỉnh
Producer: Ghi M98, M99, M100
Broker1 (Leader) Broker2 (Follower) Broker3 (Follower)
───────────────── ────────────────── ──────────────────
LEO = 100 LEO = 98 LEO = 97
[M0...M97] [M0...M97] [M0...M97]
[M98] [M98] (đang fetch M98)
[M99] (đang fetch M99)
[M100]
ISR = [Broker1, Broker2, Broker3]
HW = min(100, 98, 97) = 97
Consumer: Chỉ được đọc đến offset 96 (< HW = 97)
→ Sau khi Broker3 fetch xong M97, M98:
HW = min(100, 98+1, 97+1) → tăng dần4. Cấu Hình HA Chuẩn Production
4.1 Công Thức “Không Bao Giờ Mất Data”
Điều kiện: Data được ghi thành công = Data sẽ không bao giờ mất dù có sự cố
Công thức:
replication.factor (N) ≥ 3
min.insync.replicas (M) ≥ 2 (và M < N)
acks = all (phía Producer)
Giải thích:
replication.factor=3: 3 bản sao vật lý
min.insync.replicas=2: ACK chỉ trả về khi ít nhất 2 bản đã ghi
acks=all: Producer yêu cầu tất cả ISR phải confirm
→ Nếu 1/3 Broker chết: 2 bản còn lại, vẫn ≥ min.insync.replicas=2 → OK
→ Nếu 2/3 Broker chết: 1 bản còn lại, < min.insync.replicas=2 → REJECT write
Producer nhận NotEnoughReplicasException, retry hoặc alert
→ Đảm bảo không ghi thành công khi không đủ replica để bảo vệ data4.2 Bảng Tính Toán Fault Tolerance
| replication.factor | min.insync.replicas | acks | Max broker failure | Data safety |
|---|---|---|---|---|
| 1 | 1 | 1 | 0 | ❌ Không HA |
| 2 | 1 | 1 | 1 | ⚠️ Có thể mất data |
| 3 | 2 | all | 1 | ✅ Production standard |
| 5 | 3 | all | 2 | ✅ Mission critical |
4.3 Cấu Hình Đầy Đủ
# server.properties (Broker config)
default.replication.factor=3
min.insync.replicas=2
unclean.leader.election.enable=false # Không bao giờ chọn out-of-sync broker
auto.leader.rebalance.enable=true # Tự cân bằng leader về Preferred Broker
# Replica lag threshold
replica.lag.time.max.ms=30000 # 30s để declare follower out of ISR# Producer config
acks=all
enable.idempotence=true
retries=21474836475. Rack Awareness — HA Ở Cấp Data Center
Deployment trên 3 AWS Availability Zones:
AZ-1 AZ-2 AZ-3
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Broker 1 │ │ Broker 2 │ │ Broker 3 │
│ │ │ │ │ │
│ P0 (Leader) │ │ P0 (Follow) │ │ P0 (Follow) │
│ P1 (Follow) │ │ P1 (Leader) │ │ P1 (Follow) │
│ P2 (Follow) │ │ P2 (Follow) │ │ P2 (Leader) │
└─────────────┘ └─────────────┘ └─────────────┘
Config:
broker.rack=us-east-1a (mỗi broker khai báo AZ của mình)
Kafka sẽ đảm bảo: Các replica của cùng Partition nằm trên AZ khác nhau
→ Nếu toàn bộ AZ-1 mất điện → P0 vẫn sống với Follower ở AZ-2 và AZ-36. Monitoring HA — Chỉ Số Bắt Buộc Phải Alert
Kafka JMX Metrics cần monitor:
1. kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions
→ Cảnh báo ngay khi > 0 và kéo dài > 5 phút
→ Nghĩa là: Có partition đang thiếu replica dự phòng!
2. kafka.server:type=ReplicaManager,name=IsrShrinks
→ Số lần ISR bị thu hẹp (Follower rời ISR)
→ Tăng đột biến = mạng đang gặp vấn đề hoặc broker quá tải
3. kafka.controller:type=KafkaController,name=ActiveControllerCount
→ Phải luôn = 1 (không phải 0 hoặc 2!)
→ 0 = Cluster mất controller, không thể election
→ 2 = Split-brain (cực hiếm nhưng cực nguy hiểm)
4. kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec
→ Network ingress per broker, detect hot brokerKết Luận & Takeaway
Công thức HA cho Production:
┌───────────────────────────────────────────────────┐
│ Không bao giờ mất data: │
│ replication.factor=3 │
│ min.insync.replicas=2 │
│ acks=all (Producer) │
│ unclean.leader.election.enable=false │
│ enable.idempotence=true (Producer) │
│ │
│ Nếu bạn deploy trên cloud: │
│ + broker.rack=<az-id> │
│ + 1 broker per AZ, tối thiểu 3 AZ │
└───────────────────────────────────────────────────┘Câu hỏi phỏng vấn Senior hay gặp: Bạn có replication.factor=3, min.insync.replicas=2, acks=all. Cluster có 3 Broker. Nếu 1 Broker bị restart để patch OS — chuyện gì xảy ra? Hệ thống có tiếp tục nhận data không?
Xem thêm trong series:
- Kafka Consumer — Group, Rebalance và Offset (Bài trước)
- Hiệu Năng Kafka: Zero-Copy, Page Cache và I/O (Bài tiếp)
💬 Góc thảo luận: Trả lời câu phỏng vấn bên trên! Và theo bạn, cấu hình
min.insync.replicas=3với cluster 3 broker có vấn đề gì không? Phân tích nhé!